
Essential Math for Machine Learning: Confusion Matrix, Accuracy, Precision, Recall, F1-Score
The Art of Balancing
This article is part of the series Essential Math for Machine Learning.
Introduction
Imagine you’re training a spam filter. How do you measure the performance of the model? Is it more important to correctly identify all actual spam emails, even if it mistakenly flags some legitimate emails, or vice versa? In this blog post, we’ll learn how to use a tool called confusion matrix and its derived metrics to evaluate the performance of classification models.
Confusion Matrix
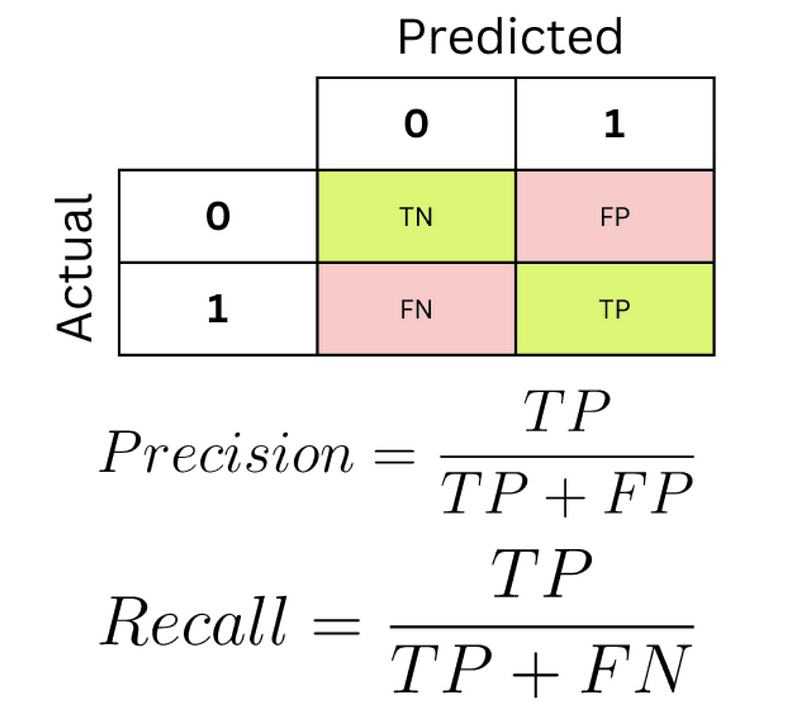
A confusion matrix is a fundamental tool for evaluating the performance of classification models in machine learning. It’s a simple table that visualizes how often your model correctly or incorrectly predicts the various classes (or categories) within your dataset.
Key Components
- True Positives (TP): The number of instances your model correctly predicted as positive.
- True Negatives (TN): The number of instances your model correctly predicted as negative.
- False Positives (FP): The number of instances your model incorrectly predicted as positive (also known as Type I error).
- False Negatives (FN): The number of instances your model incorrectly predicted as negative (also known as Type II error).
Accuracy
Accuracy is one of the most basic metrics used to evaluate a classification model. It represents the percentage of correct predictions made by your model. To calculate accuracy from a confusion matrix, you use the following formula:
Accuracy = (TP + TN) / (TP + TN + FP + FN)In essence, accuracy tells you what proportion of total predictions (both positive and negative) were correctly classified by your model.
While accuracy is a valuable metric, it’s essential to recognize that it can be misleading if you have a dataset with imbalanced classes (significantly more of one class than the other). Let’s say you have 1000 emails in your inbox. Only 10 of these are spam, while 990 are legitimate emails. A simple spam filter that classifies everything as “not spam” would achieve 99% accuracy. However, this filter would be terrible because it fails to catch any of the actual spam emails, which is its primary purpose. In such cases, you’ll want to consider additional metrics like precision, recall, and F1-score for a more complete picture of your model’s performance.
Precision
The formula for precision based on a confusion matrix:
Precision = TP / (TP + FP)Precision measures the proportion of true positive predictions among all positive predictions. In our spam filter example, precision tells us what percentage of emails flagged as spam were actually spam.
- High precision: Great! Your model rarely flags innocent emails as spam.
- Low precision: Oops! Your model is firing off false alarms, flagging many legitimate emails as spam.
Recall
The formula for recall based on a confusion matrix:
Recall = TP / (TP + FN)Recall measures the proportion of true positive predictions among all actual positive instances. For the spam filter, recall tells us what percentage of actual spam emails were correctly identified.
- High recall: Fantastic! Your model catches most of the spam emails.
- Low recall: Uh oh! Your model is letting some spam slip through the cracks.
F1-Score
Precision and recall often have an inverse relationship. Optimizing for one might come at the expense of the other. Imagine tightening your spam filter’s criteria to improve precision (fewer false alarms). This might also decrease recall (missing more actual spam).
So, which one matters more? It depends! In healthcare, where misdiagnoses are critical, high recall might be paramount. In finance, where false positives can trigger unnecessary transactions, high precision might be crucial. Consider the real-world implications of your model’s predictions to weigh the importance of each metric.
Sometimes, finding the right balance between precision and recall is crucial. That’s where the F1-score comes in. F1-score is a harmonic mean of precision and recall, calculated as:
F1 = 2 * (precision * recall) / (precision + recall)F1-score:
- Ranges from 0 to 1, with 1 being the best score.
- Combines the strengths of precision and recall into a single metric.
- Useful when a balanced evaluation of both aspects is needed.
Example: Imagine a scenario where precision is 0.7 and recall is 0.8. Calculating the F1-score:
F1 = 2 * (0.7 * 0.8) / (0.7 + 0.8) ≈ 0.75In this case, the F1-score of 0.75 indicates a good balance between precision and recall.
Python in Action
Let’s put theory into practice with a simple example. Imagine classifying cats and dogs in images. Here’s how we’d calculate precision, recall, and F1-score. The code is available in this colab notebook.
true_labels = [1, 1, 0, 0, 1, 1, 0, 1, 1] # 1 for spam, 0 for non-spam
predicted_labels = [1, 0, 1, 0, 0, 1, 1, 0, 1]
# Calculate true positives (TP), false positives (FP), and false negatives (FN)
n = len(true_labels)
tp = sum(1 for i in range(n) if true_labels[i] == 1 and predicted_labels[i] == 1)
tn = sum(1 for i in range(n) if true_labels[i] == 0 and predicted_labels[i] == 0)
fp = sum(1 for i in range(n) if true_labels[i] == 0 and predicted_labels[i] == 1)
fn = sum(1 for i in range(n) if true_labels[i] == 1 and predicted_labels[i] == 0)
print("True positives (TP):", tp)
print("True negatives (TN):", tn)
print("False positives (FP):", fp)
print("False negatives (FN):", fn)
# Calculate accuracy
accuracy = (tp + tn) / (tp + tn + fp + fn)
print("Accuracy:", accuracy)
# Calculate precision
precision = tp / (tp + fp)
print("Precision:", precision)
# Calculate recall
recall = tp / (tp + fn)
print("Recall:", recall)
# Calculate F1-score
f1 = 2 * (precision * recall) / (precision + recall)
print("F1-score:", f1)Output:
True positives (TP): 3
True negatives (TN): 1
False positives (FP): 2
False negatives (FN): 3
Accuracy: 0.4444444444444444
Precision: 0.6
Recall: 0.5
F1-score: 0.5454545454545454Conclusion
Precision, recall, and F1-score are three tools in your machine learning toolbox. They can help you make informed decisions and optimize your models for the task at hand!





