
Demystifying PDF Parsing 01: Overview
Task Definition, Method Classification and Method Introduction to PDF Parsing
Transforming unstructured documents like PDF files and scanned images into structured or semi-structured formats is a critical part of artificial intelligence. This process is key to the intelligence of AI.
In previous articles, I have discussed:
- Parsing PDF files and their tables using unstructured framework.
- Extracting formulas in PDFs with Nougat.
- Parsing tables in PDFs with Nougat.
However, these articles have primarily focused on using open-source tools to address specific problems, without stressing how these tools should be further developed.
This series of articles will categorize the mainstream methods of PDF parsing and explore the principles of some representative open-source frameworks. From a developer’s perspective, learn how to develop your own pdf parsing tools.
Regarding open-source frameworks, our focus is not solely on their usage. The key lies in whether we can learn insights or ideas from them, as this would be greatly beneficial.
As the first article in the series, the main content of this article is to define the task of pdf parsing and classify the existing methods, then briefly introduce them.
The Main Task of PDF Parsing
Figure 1 illustrates the primary task of PDF parsing:
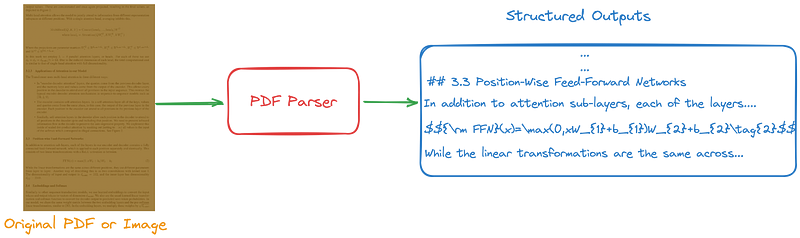
- Input: PDF file or image.
- Output: Structured or semi-structured files like Markdown, HTML, JSON or other formats defined by developers.
While the task description may appear simple, life experience shows that such tasks often demand more effort.
Method Classification
From my current understanding, methods for building PDF parsing tools can be primarily divided into the following four categories:
- Pipeline-based: This treats the entire process of PDF parsing as a sequence of models or algorithms. Each step handles its own sub-task, systematically solving the overall task.
- OCR-free small model-based: This method takes an end-to-end approach to address the entire task. It views PDF parsing as a form of sequence prediction. A small model is trained to predict tokens in formats like Markdown, JSON or HTML using the prepared training data.
- Large multimodal model-based: Utilize the powerful capabilities of large multimodal models, and delegate document understanding tasks to them. Specifically, define various tasks of PDF parsing in the form of sequential predictions. By using different prompts or fine-tuning large multimodal model, we can guide it to accomplish different tasks, such as layout analysis, table recognition, and formula recognition. The output will be in formats like Markdown, JSON or HTML.
- Rule-based: The parsing of PDF file is based on predefined rules. Although this method is fast, it lacks flexibility.
This series of articles focuses on the first three methods, without discussing rule-based methods.
Pipeline-Based Methods
This method views the task of parsing PDFs as a pipeline of models or algorithms, as depicted in Figure 2.
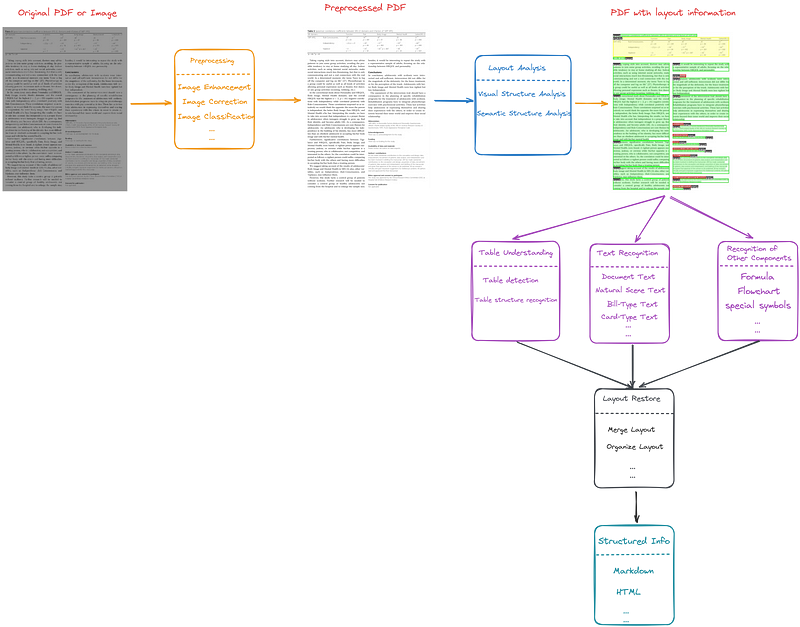
The pipeline-based method can be broadly divided into the following five steps:
- The original pdf file may have some problems, such as being blurry, the orientation of the picture is skewed, etc., so preprocessing is needed, such as image enhancement, image direction correction, etc.
- Conduct layout analysis, which involves two main components: visual structure analysis and semantic structure analysis. Visual structure analysis aims to identify the document’s structure and establish the boundaries of its similar regions. Meanwhile, semantic structure analysis involves labeling these detected areas with specific document types like text, title, list, table, figure, and so on. Also, analyze the reading order of the page.
- Treat the different areas identified during the layout analysis independently, which include table understanding, text recognition, and recognition of other components such as formulas, flowcharts and special symbols, etc.
- Integrate the previous results to restore the page structure.
- Output structured or semi-structured information, such as Markdown, JSON or HTML.
It is worth mentioning that PDF parsing is actually a subset of document intelligence, also known as document AI. Beyond the content shown in Figure 2, document intelligence also includes:
- Information extraction: Entity recognition, relationship extraction.
- Document retrieval: Keyword retrieval, structure-based retrieval.
- Semantic analysis: Content classification, summary, document QA.
Below are some representative pipeline-based pdf parsing frameworks:
- Marker: It is a lightweight pipeline of deep learning models capable of converting PDF, EPUB, and MOBI files into markdown format.
- Unstructured: A comprehensive framework that offers good customizability.
- LayoutParser: A unified toolkit for deep learning based document image analysis.
OCR-Free Small Model-Based Methods
The OCR-FREE solution believes that methods driven by the OCR model, like pipeline-based methods, depend on extracting text from external systems. This leads to higher computing resource usage and longer processing times. Furthermore, these models might inherit OCR inaccuracies, which can complicate document understanding and analysis tasks.
Therefore, the OCR-free small model-based methods should be developed, as illustrated in Figure 3.
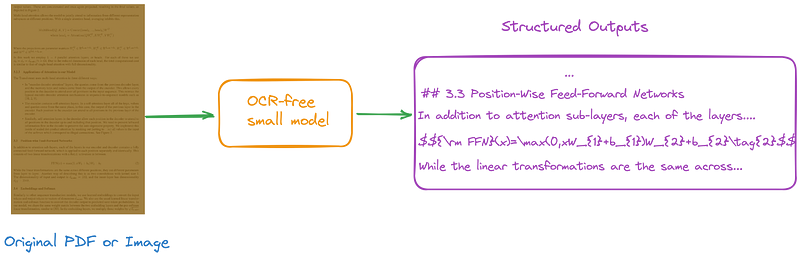
From a structural perspective, OCR-free methods are relatively straightforward compared to pipeline-based methods. The key areas of OCR-free methods that require focus are the construction of training data and the design of the model structure.
Below are some representative OCR-free small model-based pdf parsing frameworks:
- Donut: OCR-free document understanding transformer.
- Nougat: Based on Donut architecture, which is particularly effective when used with PDF papers, formulas, and tables.
- Dessurt: It’s based on an architecture similar to Donut, combining bidirectional cross attention with various pre-training methods.
Large Multimodal Model-Based Methods
In the era of LLMs, it’s not surprising to consider using large multimodal models for PDF parsing.
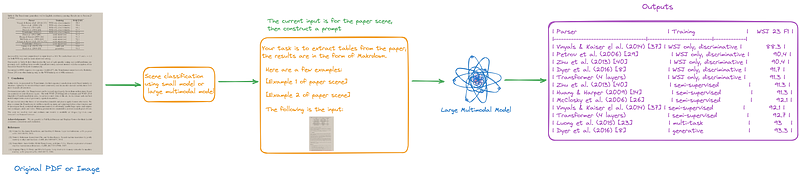
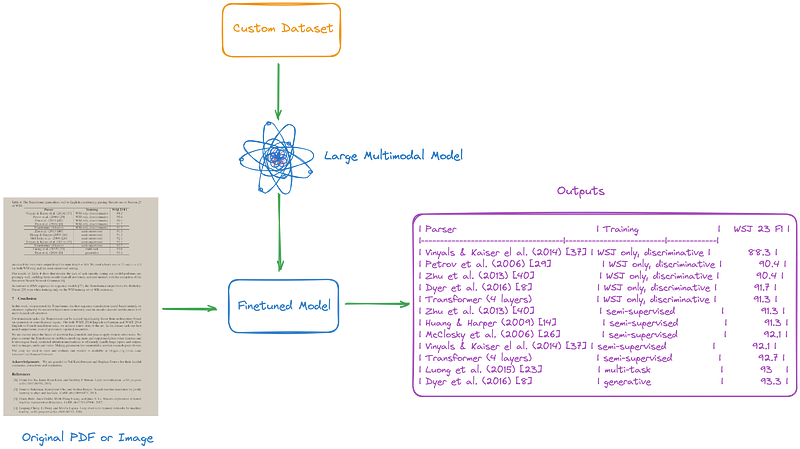
As illustrated in Figure 4 and 5, we can create prompts or fine-tune large multimodal models to enhance them, aiding us in completing various tasks.
Below are some representative large multimodal models:
- TextMonkey: A large multimodal model that focuses on text-related tasks, including document Q&A and scene text Q&A, has achieved state-of-the-art results in multiple benchmarks.
- LLaVAR: It collected rich text training data and used a higher-resolution CLIP as the visual encoder to enhance OCR capabilities.
- GPT-4V: High-quality close source large multimodal model.
Conclusion
In general, this article defined the primary tasks involved in PDF parsing, categorized the existing methods, and then provided a brief introduction to each.
Please note that this article is based on my current understanding. If I gain new insights into this field in the future, I will update this article.
If you’re interested in PDF parsing or document intelligence, feel free to check out my other articles.
Finally, if there are any errors or omissions in this article, or if you have any thoughts to share, please point them out in the comment section.

This story is published under Generative AI Publication.
Connect with us on Substack, LinkedIn, and Zeniteq to stay in the loop with the latest AI stories. Let’s shape the future of AI together!







{kind=link}