
Demystifying DreamBooth: A New Tool for Personalizing Text-To-Image Generation
Exploring the technology that turns boring images into creative masterpieces

Introduction
Imagine the joy of effortlessly generating a new image of your beloved puppy against the backdrop of the Acropolis in Athens. Not satisfied yet, you would like to see how Van Gogh would have painted your best friend or what he would look like if he had been conceived by a lion 😱! Thanks to DreamBooth, all of this is a reality, and today it is possible to make any animal, object or ourselves travel in fantasy from a handful of images.
While many of us have already seen on social media the mind-blowing results that can be achieved with this technology and there is no shortage of tutorials so that we can try it on our own photographs, rarely someone has tried to answer the question: yes, but how the hell does it work?
In this article, I will do my best to break down the scientific paper DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation by Ruiz et al. from which everything started. But don’t worry, I’ll simplify the complex parts and give explanations where they might require some prior knowledge. Now, fair warning, this is an advanced topic, so I assume you’ve got the basics of deep learning and related stuff covered. But hey, if you want to dig deeper into diffusion models or other cool topics, I’ll drop some references along the way. Let’s dive in!
Related Work

Before we get into the nitty-gritty of DreamBooth’s approach, let’s take a closer look at the related work and tasks associated with this technique.
Image Composition
Amidst the chaos of everyday life, it’s been far too long since your beloved backpack embarked on a globetrotting journey. It is time to infuse it with an exciting dose of adventure while you are planning your next vacation. Enter image composition, merge your subject seamlessly into new backgrounds, letting your backpack travel from the Grand Canyon to Boston in seconds.
If simply copy-pasting the subject doesn’t fulfill your desire for new perspectives, one possibility is to explore the application of 3D reconstruction techniques. However, it’s important to note that these techniques are primarily designed for rigid objects and often require a substantial number of starting views.
DreamBooth introduces a remarkable capability to generate fresh poses within new contexts while smoothly incorporating crucial elements such as lighting, shadows, and other scene-relative aspects. Achieving such consistency has proven challenging with prior methodologies. In the paper, this task is also denoted by the name recontextualization.
Text-to-Image Editing and Synthesis
Image editing based on textual input is a secret dream cherished by many avid users of photo editing software. Early methodologies, such as those employing GANs, demonstrated impressive results, but only in well-structured scenarios like editing human faces.
Even new approaches that take advantage of diffusion models have limitations and are usually restricted to global editing. Only recently have advances such as Text2LIVE emerged that allow localized editing. However, none of these techniques allow the generation of a given subject in new contexts.
Although text-image synthesis models like Imagen, DALL·E 2, and Stable Diffusion have made significant strides, the attainment of fine-grained control and the preservation of subject identity in synthesized images continue to pose substantial challenges.
Controllable Generative Models
To avoid subject modification, many approaches rely on a user-provided mask that limits the area to be modified. Inversion techniques, such as the one used by DALL·E 2, present an effective solution for preserving the subject while modifying the context.
Prompt-to-Prompt enables both local and global editing without the need for an input mask.
However, these methods do not adequately preserve the identity while generating novel samples of a subject.
While some GAN-based methods focus on generating instance variations, they often have limitations. For instance, they are primarily designed for the face domain, require many instances of the input subject, struggle with unique subjects, and fail to preserve important subject details.
Finally, recently Gal et. al. presented Textual Inversion, a methodology with features common to DreamBooth but which, as we will see, is limited by the expressiveness of the frozen diffusion model on which it is based.
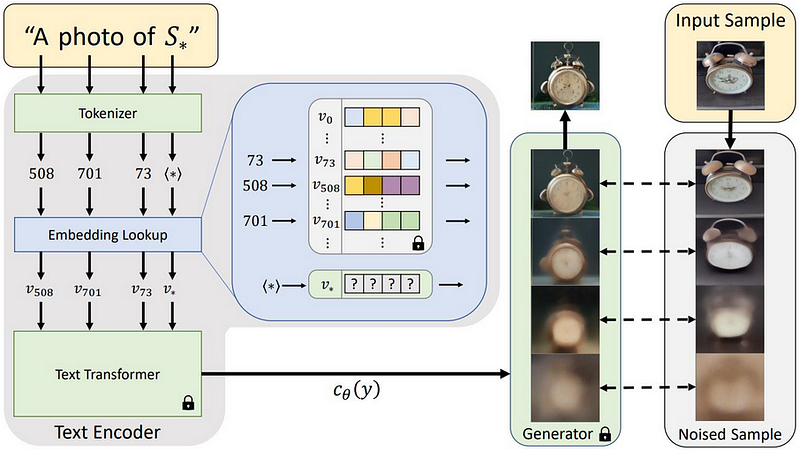
Since this is the work with which the authors compare DreamBooth, it is worth providing a brief description of it.
Textual Inversion starts from a pre-trained diffusion model, such as Latent Diffusion, and defines a new placeholder string S*, to represent the new concept to be learned. At this point, keeping the diffusion model frozen, the new embedding is fine-tuned from just 3–5 images, similar to DreamBooth. If this brief description is not clear enough, wait until you read the more detailed description of DreamBooth, which has many points in common with this work.
Method
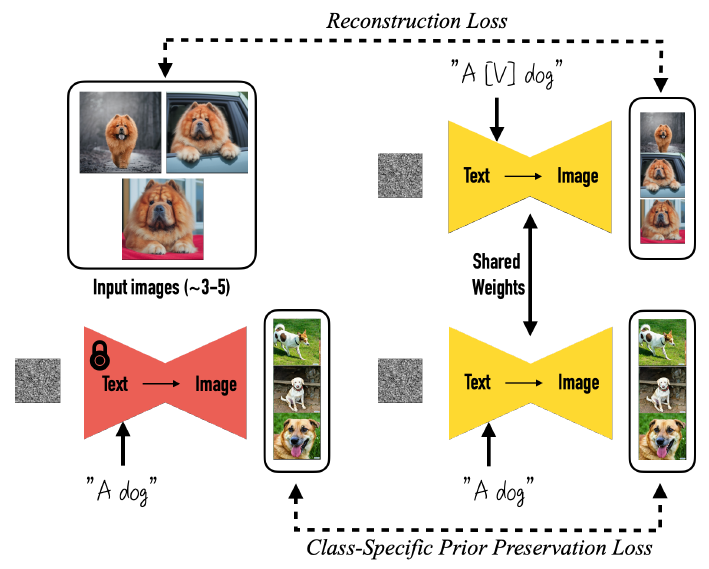
Before describing the components of DreamBooth in detail, let’s see schematically how this technology works:
- Choose 3–5 images of your favorite subject, it can be an animal, an object or even an abstract concept such as an art style.
- Associate this concept with a rare word to which corresponds a unique token that will represent it from now on, in the scientific paper the authors call this word [V].
- Fine-tune the model using images of the subject of interest with a simple prompt such as “A [V] [class noun]”, for example “A [V] dog” if the input images are photographs of your dog.
- Since we are fine-tuning all the parameters of the model, there is a risk that at this point all dogs (or whatever class our subject is) will become the same as our input images. To avoid this degradation of our model, we generate images from our frozen model with a prompt such as “A dog” (or “A [class noun]”) and add a loss that penalizes when the images generated by our model that we are fine-tuning for this prompt deviate from those generated by the frozen model.
Okay, now that we have a high-level idea of the procedure, let’s go into more detail about the various components.
Text to Image Diffusion Models
Do you really want to learn how diffusion models work and, in particular, latent diffusion models such as Stable Diffusion? Read my previous article below, I will be waiting for you here when you are done!
OK, maybe you don’t want a whole explanation, in which case I will give here the intuition behind diffusion models, which is very simple.
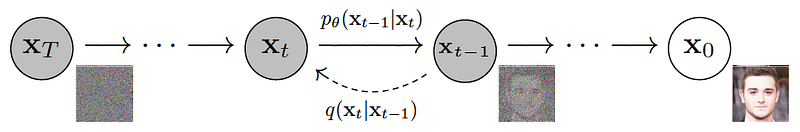
- Take an image x0 and add a certain amount of noise (e.g. Gaussian noise) proportional to a certain timestep t. If t is zero the added noise will be zero, if t > 0 the added noise will be as large as t is, until you arrive at an image that is just noise.
- Train a model, such as a U-Net, to predict the noise-free image (or the noise that has been added) by giving as input to the model the timestep t and the corrupted image.
- At this point, having trained a model that can remove noise from an image, we can sample an image composed only of noise and gradually remove it (doing it all at once works poorly) either by predicting the image without noise or by predicting the noise and subtracting it from the image.
- The first three points describe an unconditional diffusion model. In order to produce a conditional output based on textual prompt, the text is encoded using models like CLIP, or language models such as BERT, T5, and others. This encoding step allows for the integration of additional information, which is then fed as input to the model alongside the corrupted image and the timestep t.
The authors in the paper use two diffusion models: Google’s Imagen (also DreamBooth is from Google Research) and Stable Diffusion from Stability AI, the main open-source text-to-image model.
Imagen employs a multi-resolution strategy to enhance the quality of generated images. Initially, a diffusion model is trained using low-resolution 64x64 images. The output of the low-resolution model is then upscaled by two additional diffusion models that operate at higher resolutions, 256x256 and 1024x1024. The first model specializes in capturing macro-details, while the subsequent models refine the output by leveraging the conditioning effect of the lower resolution model’s generated image. This iterative refinement facilitates the generation of high-resolution images with improved quality and fidelity.
Stable Diffusion instead, as a latent diffusion model, introduces a three-step approach to enhance the efficiency of training and generating high-resolution images. Initially, a Variational Autoencoder (VAE) is trained to compress a high-resolution image. From this point onward, the process closely resembles that of standard diffusion models, with one key distinction: instead of employing the original image as input, the latent representation generated by the VAE encoder is utilized. Subsequently, the output of the inverse diffusion process is then restored to the original resolution using the VAE decoder. For a more comprehensive understanding of this entire procedure, I delve into greater detail in the aforementioned article.
Personalization of Text to Image Models
DreamBooth aims to place the subject instance (e.g. your dog) within the output domain of the model, enabling the model to generate fresh images of the subject upon query. An advantage of diffusion models, as opposed to GANs, is their ability to effectively incorporate new information into their domain while retaining knowledge of previous data and avoiding overfitting to a limited training image set.
Designing Prompts for Few-Shot Personalization
As mentioned above, the model undergoes training using simplistic prompts structured as “a [identifier] [class noun]”. Here, [identifier] represents a distinct identifier associated with the subject, and [class noun] serves as a general description of the subject’s category (such as cat, dog, watch, etc.). The authors incorporate the class noun into the prompt to establish a connection between the general class and our individual subject, observing that using an incorrect or missing class noun leads to longer training times and language drift, ultimately affecting performance. Essentially, the main aim is to capitalize on the relationship between the specific class and our subject, utilizing the existing knowledge acquired by the model about the class. This enables us to generate fresh poses and variations of the subject across various contexts.
Rare-Token Identifiers
The paper highlights that common English words are not ideal in this context since the model needs to disassociate them from their original meaning and reintegrate them to refer to our subject.
To address this, the authors propose using an identifier that has a weak prior in both the language and diffusion models. While selecting random characters like “xxy5syt00” may initially appear appealing, it poses potential risks. It is important to consider that the tokenizer could tokenize each letter individually. So, what is the solution? The most effective approach involves identifying uncommon tokens in the vocabulary and then inverting these tokens within the text space. This minimizes the likelihood of the identifier having a strong prior.
Funny enough, most tutorials use “sks” for this purpose but, as pointed out by one of the authors, this seemingly harmless word can have side effects…
Class-Specific Prior Preservation Loss

Unlike Textual Inversion, DreamBooth fine-tunes all layers of the model to maximize performance. Unfortunately, doing so runs into the well-known problem of language drift, i.e. when a model is initially pre-trained on an extensive text corpus and subsequently fine-tuned for a particular task, it gradually diminishes its understanding of the language’s syntax and semantics.
An additional issue arises from the potential reduction in output diversity. This can be observed in the second row of Fig. 6, where the model, unless further adapted, has a tendency to replicate solely the poses found in the input images. This effect becomes more pronounced when the model is trained for an extended duration.
To mitigate these problems, the authors introduce a class-specific prior preservation loss, let’s look at its overall loss formula and then explain its components:
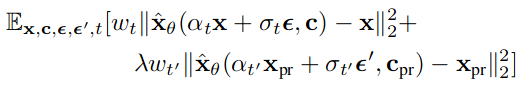
The first part is the standard L2 denoising error, typical of any diffusion model. α_t scales the initial image x to which is then added a Gaussian noise ε ∼ N (0, I), multiplied by σ_t. The random variable z_t := α_t*x + σ_t*ε then has distribution N(α_t*x, σ_t²). The model xˆ_θ at this point will try to predict the original image from z_t, t and the conditioning vector c = Γ(P), where Γ in the case of DreamBooth is T5 and the prompt P has the form “a [identifier] [class noun]”.
The second part is the prior preservation loss, in this instead of x we have x_pr, an image generated by the model with frozen weights (before fine-tuning) from a random initial noise z_1 ∼ N (0, I) and conditioning vector c_pr = Γ(“a [class noun]”). This part then pushes the model to re-obtain x_pr from a corrupted version of it, thus pushing the model to generate images similar to those generated before the fine-tuning process for instances of the subject class.
Finally, w_t and w_t’ are terms related to the noise schedule and λ defines the relative weight to be given to the two losses.
Experiments

Dataset
The dataset used for the experiments was generated by the authors and consists of 30 subjects including unique objects such as backpacks or sunglasses and animals such as dogs, cats, etc. Of the 30 subjects, 21 of the 30 subjects are objects, and 9 are live subjects/pets.
The authors then define 25 prompts: 20 recontextualization and 5 property modification prompts for objects; 10 recontextualization, 10 accessorization and 5 property modification prompts for living subjects/pets.
Evaluation Metrics
For the evaluation, four images are generated per subject and per prompt, for a total of 3,000 images.
To measure subject fidelity, CLIP-I and DINO are used.
CLIP-I, already used in previous work, calculates the average pairwise cosine similarity between CLIP embeddings of generated and real images. CLIP is trained to make a text description have the same embedding as an image to which it refers, so that if two images represent the same text they will have similar embeddings.
DINO, a new metric introduced by the authors, is analogous to CLIP-I but instead of generating embeddings with CLIP these are generated with ViT-S/16 DINO, a self-supervised trained model.
In the paper, is observed that CLIP-I, due to the way CLIP is trained, does not distinguish between different subjects that might have very similar textual descriptions. On the other hand, DINO (the model, not the metric) is trained in a self-supervised manner, which facilitates the distinction of unique features within a subject or image. For this reason, they regard DINO as their primary metric.
Finally, a third metric, CLIP-T, is introduced to measure, another important aspect: prompt fidelity, that is, when the generated image is close to the input prompt.
CLIP-T is similar to the previous metrics as well, measuring the average cosine similarity between two embeddings obtained with CLIP: one from the prompt and the other from the image. It is important to note that CLIP was specifically trained to generate textual embeddings that are similar to the ones of the corresponding images.
Comparisons
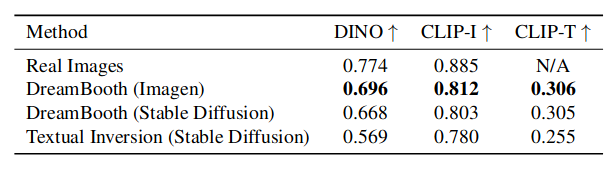
As we can see from Table 1, DreamBooth is clearly superior to Textual Inversion when measured using the DINO and CLIP-T metrics, while the distance is less when measured with CLIP-I, which, however, as already mentioned, is not a good metric for measuring fidelity to a specific subject.
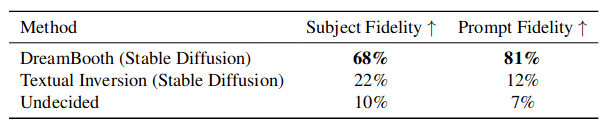
It is very difficult to find a metric that correlates perfectly with what a person would judge to be a more or less good outcome. For this reason, the authors also measure the preference of a sample of 72 users. The results highlight that the percentage of users who prefer DreamBooth for both subject fidelity and prompt fidelity is larger than one would be led to believe by looking at the previous metrics alone. We can judge for ourselves by looking at the images shown in Fig. 4 of the paper, where the stark difference between the two methodologies is clear, at least for this specific example.
Conclusion
The field of image generation and generative AI has gained significant attention in recent times. Advancements in image synthesis, particularly through the use of diffusion models, have propelled this area forward.
In this article, we delved into the scientific paper of DreamBooth — an impressive solution that enables the generation of new images with varying poses and contexts while maintaining fidelity to the desired subject. This innovative approach showcases the remarkable progress made in the realm of image synthesis and holds great potential for future developments.
Thank you for taking the time to read this article, and please feel free to leave a comment or connect with me to share your thoughts or ask any questions. To stay updated on my latest articles, you can follow me on Medium, LinkedIn or Twitter.





