
Delivering Real-time Streaming Data to Amazon S3 Using Amazon Kinesis Data Firehose

In this post let us explore what is streaming data and how to use Amazon Kinesis Firehose service to make an application which stores these streaming data to Amazon S3. As a hands-on experience, we will use AWS Management Console to ingest simulated stock ticker data from which we will create a delivery stream and save to S3. Before going into implementation let us first look at what is streaming data and what is Amazon Kinesis.
Streaming data is data that is generated continuously by many data sources. These can be sent simultaneously and in small sizes. These streaming data can be gathered by tools like Amazon Kinesis, Apache Kafka, Apache Spark, and many other frameworks. Some examples of streaming data are
- log files generated by an application
- customer interaction data from a web application or mobile application
- financial stock market data
- IOT device data (sensors, performance monitors etc.. )
Amazon Kinesis is a service provided by Amazon which makes it easy to collect,. process and analyze real-time, streaming data. At present, Amazon Kinesis provides four types of Kinesis streaming data platforms.
- Kinesis Data Streams — used to collect and process large streams of data records in real time
- Kinesis Data Firehose — used to deliver real-time streaming data to destinations such as Amazon S3, Redshift etc..
- Kineses Data Analytics — used to process and analyze streaming data using standard SQL
- Kinesis Video Streams — used to fully manage services that use to stream live video from devices
Amazon Kinesis Data Firehose
Amazon Kinesis data firehose is a fully managed service provided by Amazon to delivering real-time streaming data to destinations provided by Amazon services. At present, Amazon Kinesis Firehose supports four types of Amazon services as destinations.
- Amazon S3 — an easy to use object storage
- Amazon Redshift — petabyte-scale data warehouse
- Amazon Elasticsearch Service — open source search and analytics engine
- Splunk — operational intelligent tool for analyzing machine-generated data
In this post, we are going to look at how we can use Amazon Kinesis Firehose to save streaming data to Amazon Simple Storage (S3). Before start implementing our application let us first look at the key concepts of Amazon Kinesis Firehose.
Kinesis Data Firehose delivery stream — the underlying entity of Kinesis Data Firehose.
Data producer — the entity which sends records of data to Kinesis Data Firehose. (ex:- web or mobile application which sends log files)
Record — the data that our data producer sends to Kinesis Firehose delivery stream.
Buffer size and buffer interval — the configurations which determines how much buffering is needed before delivering them to the destinations.
Now that we have learned key concepts of Kinesis Firehose, let us jump into implementation part of our stream. The following diagram shows the basic architecture of our delivery stream. Data producers will send records to our stream which we will transform using Lambda functions. After that, the transformed records will be saved on to S3 using Kinesis Firehose. We will also backup our stream data before transformation also to an S3 bucket.
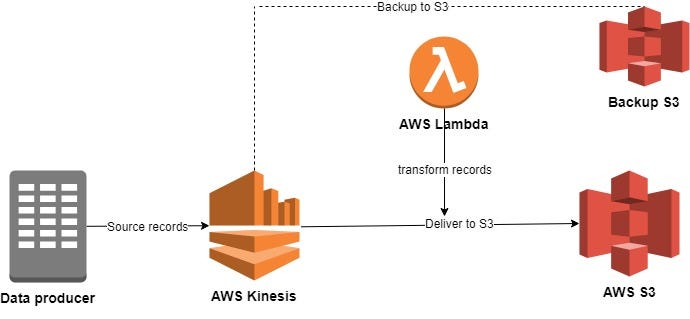
For this post, we are going to create a delivery stream where the records will be stock ticker data. We will use the AWS Management Console to ingest simulated stock ticker data and S3 as our destination. The simulated data will have the following format.
{"TICKER_SYMBOL":"JIB","SECTOR":"AUTOMOBILE","CHANGE":-0.15,"PRICE":44.89}Creating an Amazon Kinesis Data Firehose delivery stream
Kinesis Firehose delivery streams can be created via the console or by AWS SDK. For our blog post, we will use the ole to create the delivery stream. We can update and modify the delivery stream at any time after it has been created.
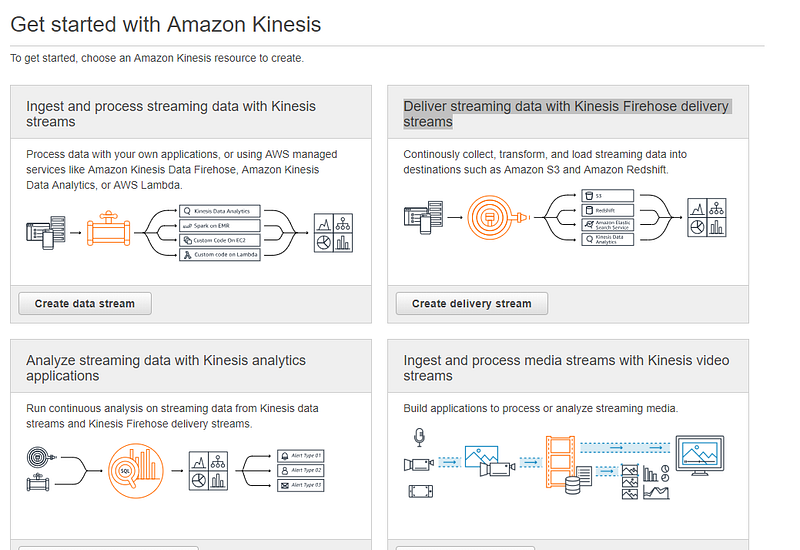
First go to Kinesis service which is under Analytics category. If you have never used Kinesis before you will be greeted with the following welcome page.

Click Get started to create our delivery stream. In the next page, you will be given four types of wizards to create Kinesis streams for four types of data platform service. For this post what we are using is Deliver streaming data with Kinesis Firehose delivery streams which is the second option.
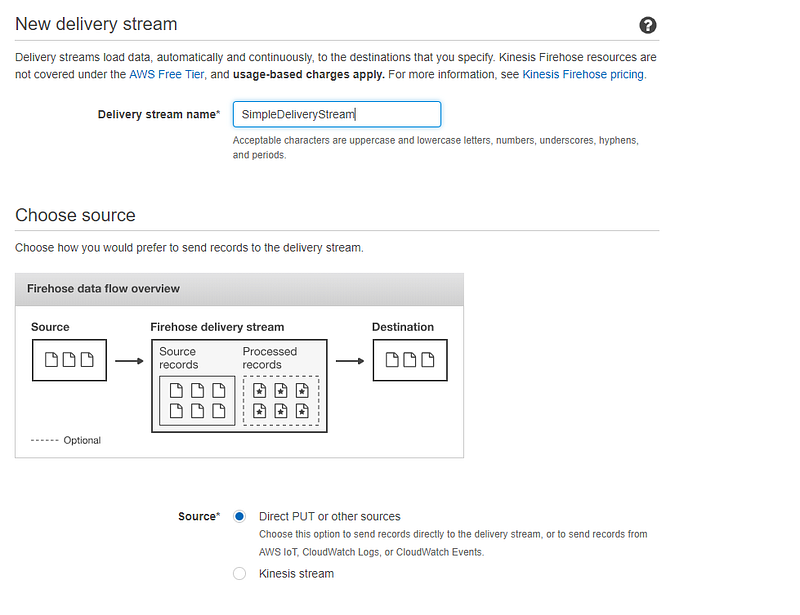
Provide a name for the Delivery stream name. Under source Select Direct PUT or other sources. This option will create a delivery stream that producer applications write directly to. If Kinesis stream is selected, then the delivery stream will use a Kinesis data stream as a data source. For simplicity of this post, we have select first option.
Transform records
In the next page, we will need to configure data transformation configurations. Kinesis Firehose can invoke a Lambda function to transform incoming source data and deliver the transformed data to destinations. Blueprints for Lambda functions are provided by AWS. But before creating a Lambda function let’s look at the requirements we need to know before transforming data.
All transformed records from the lambda function should contain the parameters described below.
- recordid — the record ID passed from Kinesis Firehose to Lambda during the invocation. The transformed record should contain the same id.
- result — the status of the data that have been transformed by the Lambda function.
- data — the transformed data
There are several Lambda blueprints provided for us that we can use to create out Lambda function for data transformation. We will use one of these blueprints to create our Lambda function.
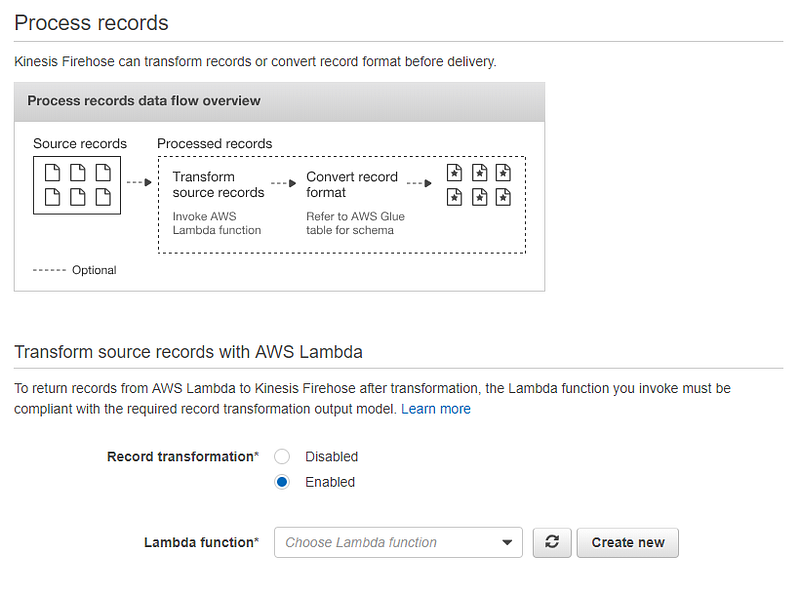
In the page of Process records in Transform source records with AWS Lambda select Enabled. This will prompt you to choose a Lambda function. Select Create new. Here we are provided with the Lambda blueprints for data transformation. Select General Firehose Processing as our blueprint.
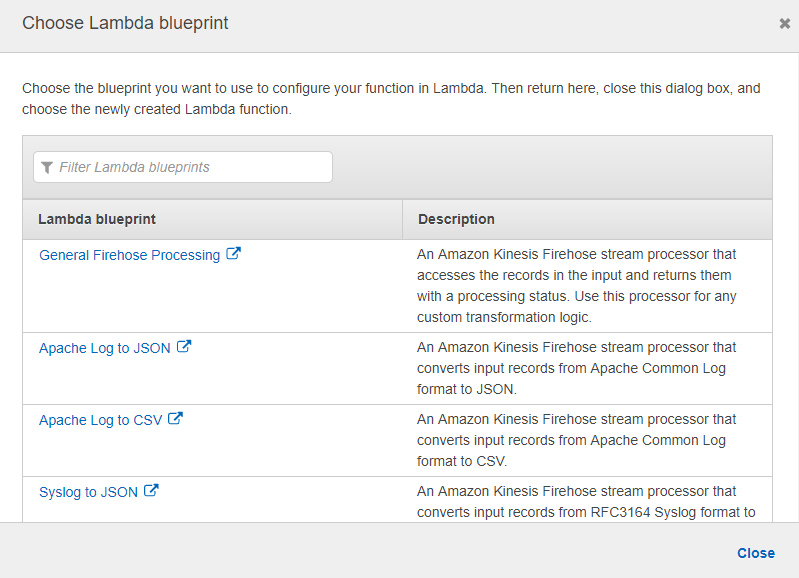
This will land us to Lambda function creation page. Provide a name for our function. Then we need to provide an IAM role which is able to access our Firehose delivery stream with permission to invoke PutRecordBatch operation.
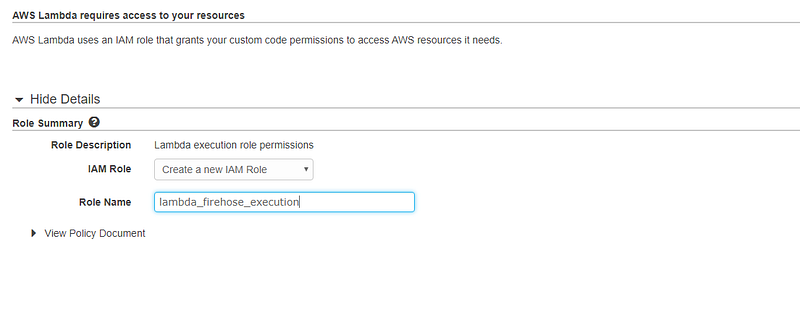
In View Policy Document, choose Edit and add the following content to the policy.
{
"Effect": "Allow",
"Action": [
"firehose:PutRecordBatch"
],
"Resource": [
"arn:aws:firehose:your-region:your-aws-account-id:deliverystream/your-stream-name"
]
}Make sure to edit your-region, your-aws-account-id, your-stream-name before saving the policy.

After creating the IAM role we will be redirected back to the Lambda function creation page. Here choose the created role. After that, we need to write our own Lambda function code in order to transform our data records. Lambda blueprint has already populated code with the predefined rules that we need to follow.
As mentioned above our streaming data will be having the following format.
{"TICKER_SYMBOL":"JIB","SECTOR":"AUTOMOBILE","CHANGE":-0.15,"PRICE":44.89}For the simplicity of this post, we will do a simple transformation for this records. We will ignore “CHANGE” attribute when streaming the records. So our transformed records will have attributes ticker_symbol, sector and price attributes only. Paste the following code to your Lambda function to achieve this.
'use strict';
console.log('Loading function');exports.handler = (event, context, callback) => {
/* Process the list of records and transform them */
const output = event.records.map((record) => {
console.log(record.recordId);
const payload =JSON.parse((Buffer.from(record.data, 'base64').toString())) const resultPayLoad = {
ticker_symbol : payload.ticker_symbol,
sector : payload.sector,
price : payload.price,
};
return{
recordId: record.recordId,
result: 'Ok',
data: (Buffer.from(JSON.stringify(resultPayLoad))).toString('base64'),
};
});
console.log(`Processing completed. Successful records ${output.length}.`);
callback(null, { records: output });
};After creating the Lambda function go back to delivery stream create page. Here select the new Lambda function that we have just created.
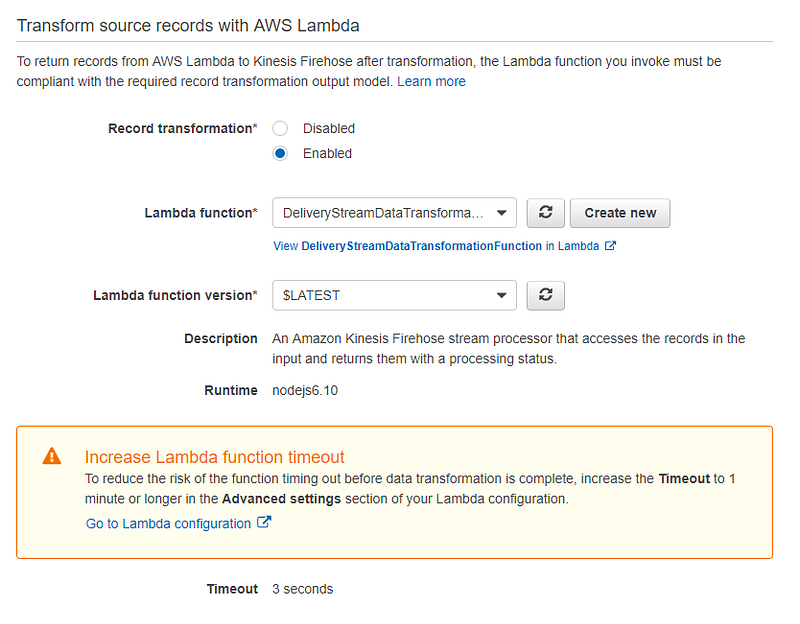
Destination
In the next page, we will be prompted to select the destination. In this post, we are going to save our records to S3.
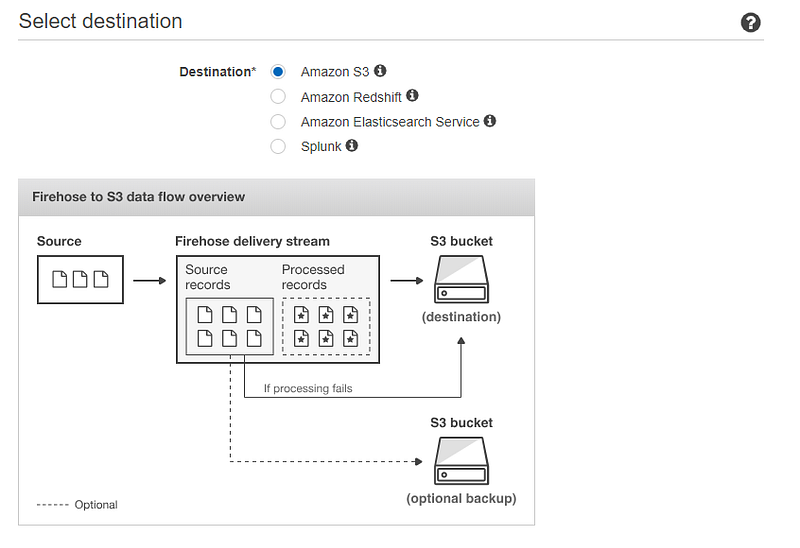
In S3 destination choose the S3 bucket that we are going to store our records. If you haven’t created an S3 bucket yet, you can choose to create new. If you want to back up the records before the transformation process done by Lambda then you can select a backup bucket as well.
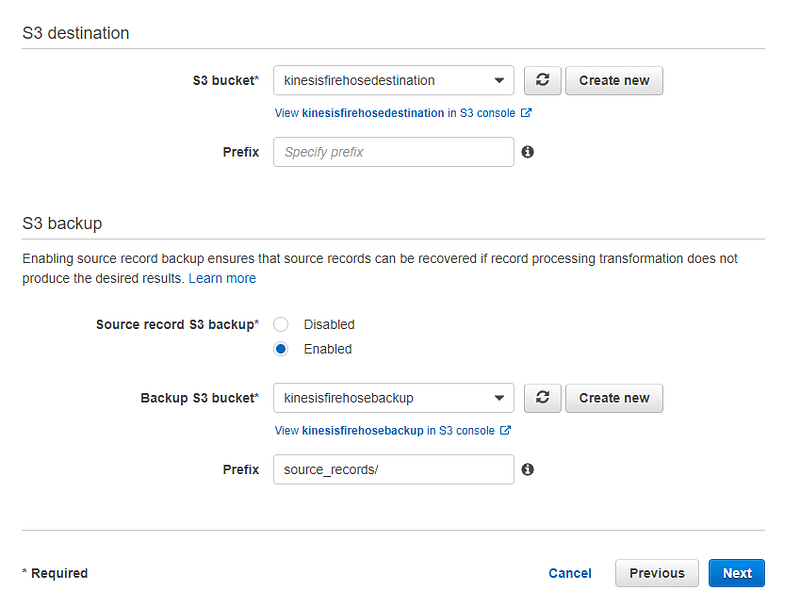
After selecting our destination we will be redirected to configurations page. Here we can first select a buffer size and a buffer interval, S3 compression and encryption and error logging. Keep the default values to all the configuration settings except for IAM role. We need to provide an IAM role for Kinesis to access our S3 buckets. If you already have an IAM role you can choose it if you don’t create new.
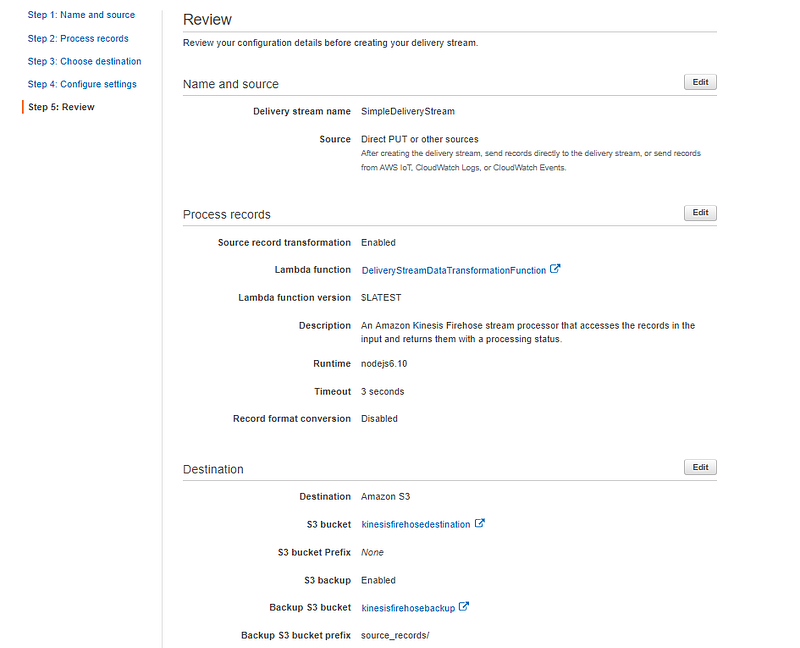
After reviewing our configurations and click Create delivery stream to create our Amazon Kinesis Firehose delivery stream. The new Kinesis Firehose delivery stream will take a few moments in the Creating state before it is available for us. After the delivery stream state changed to Active we can start sending data to it from a producer.
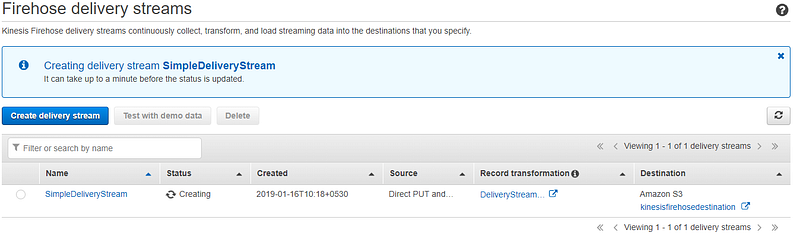
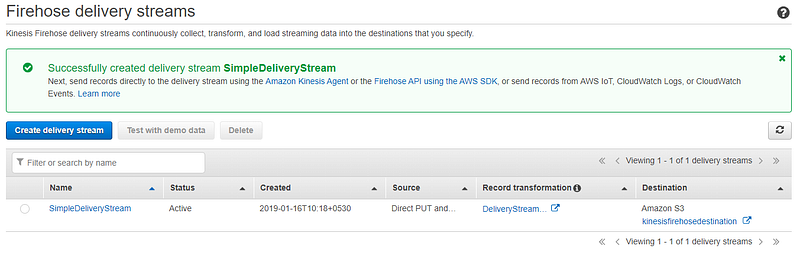
Now we have created the delivery stream. Let us now test our created delivery stream. For that click on the delivery stream and open Test with demo data node.
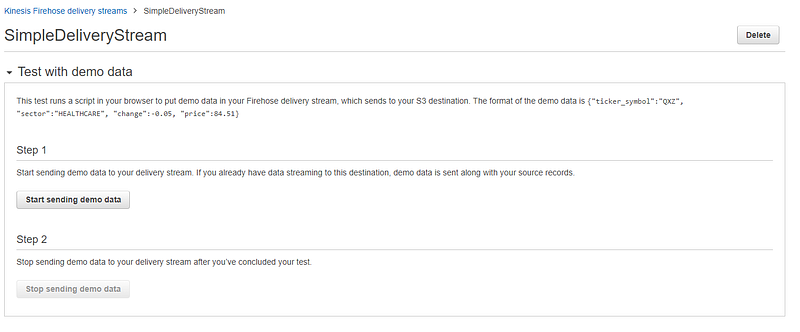
Click on Start sending demo data. This will start records to be sent to our delivery stream. After sending demo data click in Stop sending demo data to avoid further charging. Note that it might take a few minutes for new objects to appear in your bucket, based on the buffering configuration of your bucket. To confirm that our streaming data was saved in S3 we can go to the destination S3 bucket and verify. Verify whether the streaming data does not have the Change attribute as well. All the streaming records before transform can be found on the backup S3 bucket.
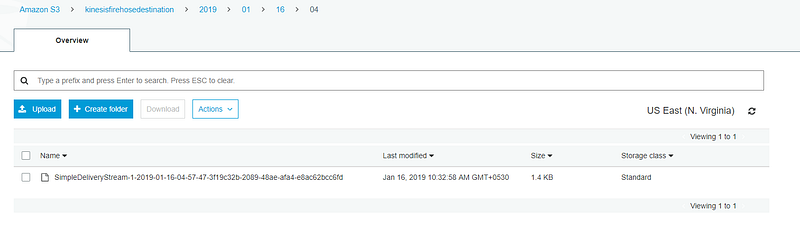
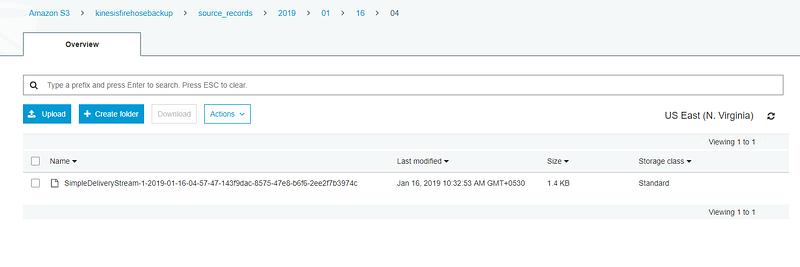
We have now created successfully a delivery stream using Amazon Kinesis Firehose for S3 and have successfully tested it. You can look more into Kinesis Firehose where the destination might be Amazon Redshift or the producer might be a Kinesis datastream. Follow this documentation to go more depth on Amazon Kinesis Firehose.