
Deep Q-Learning to Actor-Critic using Robotics Simulations with Panda-Gym
Reinforcement learning (RL) is a type of machine learning that allows agents to learn how to behave in an environment by trial and error. The agent is rewarded for taking actions that lead to desired outcomes and penalized for taking actions that lead to undesired outcomes. Over time, the agent learns to take the actions that maximize its expected reward.
RL agents are typically trained using a Markov decision process (MDP), which is a mathematical framework for modeling sequential decision-making problems. An MDP consists of four components:
- States: The set of possible states of the environment.
- Actions: The set of actions that the agent can take.
- Transition function: A function that predicts the probability of transitioning to a new state given the current state and action.
- Reward function: A function that assigns a reward to the agent for each transition.
The agent’s goal is to learn a policy function, which maps states to actions. The policy function should be chosen to maximize the agent’s expected reward over time.
Deep Q-learning is a type of RL algorithm that uses a deep neural network to learn the policy function. The deep neural network takes the current state as input and outputs a vector of values, one for each possible action. The agent then takes the action with the highest value.
Deep Q-learning is a value-based RL algorithm, which means that it learns the value of each state-action pair. The value of a state-action pair is the expected reward that the agent will receive if it takes that action in that state.
Actor-critic is a type of RL algorithm that combines value-based and policy-based RL methods. The actor-critic algorithm has two components:
- Actor: The actor is responsible for selecting actions.
- Critic: The critic is responsible for evaluating the actions taken by the actor.
The actor and critic are trained simultaneously. The actor is trained to maximize the expected reward, and the critic is trained to accurately predict the expected reward for each state-action pair.
The actor-critic algorithm has several advantages over other RL algorithms. First, it is more stable, meaning that it is less likely to diverge during training. Second, it is more efficient, meaning that it can learn faster. Third, it is more scalable, meaning that it can be applied to problems with large state and action spaces.
Deep Q-learning and actor-critic are two of the most popular RL algorithms. Deep Q-learning is a value-based RL algorithm, while actor-critic is a hybrid RL algorithm that combines value-based and policy-based RL methods.
Here is a table that summarizes the key differences between deep Q-learning and actor-critic:

Advantages of Actor-Critic (A2C)
Actor-Critic is a popular reinforcement learning architecture that combines elements of both policy-based and value-based methods. It has several advantages, making it a powerful choice for solving a variety of reinforcement learning tasks. Here are some of the advantages of the Actor-Critic architecture:
- Low Variance: Actor-Critic methods tend to have lower variance in their updates compared to pure policy-based methods like REINFORCE. This makes training more stable and efficient.
- Efficiency: Actor-Critic methods update both the policy (actor) and the value function (critic) simultaneously. This allows for more sample-efficient learning compared to training the policy and value function separately.
- Continuous Action Spaces: Actor-Critic methods are well-suited for tasks with continuous action spaces, as they provide a flexible way to learn deterministic or stochastic policies.
- Function Approximation: They can handle function approximation, making it possible to generalize from observed states to unvisited states. This is particularly useful for tasks with large state spaces.
- Exploration-Exploitation: The critic helps in estimating the value of different actions or policies, which aids in making informed decisions about exploration and exploitation.
- Policy Improvement: The critic provides a baseline or value estimate that guides the actor’s policy updates. This helps the actor learn policies that are more likely to lead to higher expected returns.
- Asynchronous Updates: Actor-Critic architectures can be used in asynchronous learning setups, where multiple actors and critics can interact with the environment in parallel, speeding up training.
- Online Learning: Actor-Critic can be used for online learning tasks where data is continuously generated and used for updates without the need for batch processing.
- Temporal-Difference Learning: The critic often uses temporal-difference learning, which is efficient in estimating the value function with less computational cost compared to Monte Carlo methods.
- Fine-Tuning and Transfer Learning: Actor-Critic models can be fine-tuned or adapted to new tasks or environments, making them useful for transfer learning.
- Policy Search: In cases where the policy space is large and complex, Actor-Critic methods can be used for policy search and optimization.
- Balance of Exploration and Exploitation: Actor-Critic methods can be designed to balance exploration and exploitation, which is crucial for learning optimal policies in reinforcement learning.
While Actor-Critic methods offer several advantages, they also come with their own challenges, such as hyperparameter tuning and potential instability in training. However, with proper tuning and techniques like experience replay and target networks, these challenges can be mitigated to a large extent, making Actor-Critic a valuable approach in reinforcement learning.
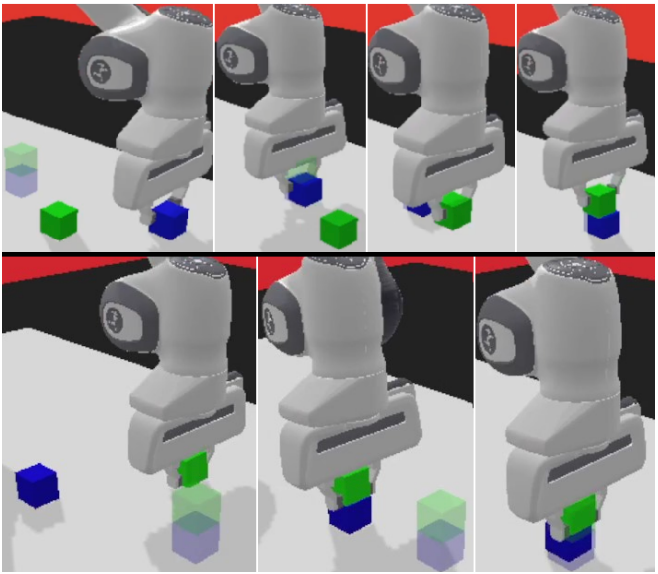
PandaReachDense 🦾 Code Implementation:
The provided code exemplifies how to implement an Actor-Critic reinforcement learning architecture in the context of “PandaReachDense,” showcasing the successful fusion of policy-based and value-based methods. This code implementation encompasses the following essential components:
Step 1: Install Libraries:
- The code begins by initializing the reinforcement learning environment, typically using popular libraries like Gym. The chosen environment represents the task that the agent needs to learn.
!apt-get install -y \
libgl1-mesa-dev \
libgl1-mesa-glx \
libglew-dev \
xvfb \
libosmesa6-dev \
software-properties-common \
patchelf
!pip install \
free-mujoco-py \
pytorch-lightning \
optuna \
pyvirtualdisplay \
PyOpenGL \
PyOpenGL-accelerate\
stable-baselines3[extra] \
gymnasium \
huggingface_sb3 \
huggingface_hub \
panda_gym
Step 2: Import Libraries
import os
import gymnasium as gym
import panda_gym
from huggingface_sb3 import load_from_hub, package_to_hub
from stable_baselines3 import A2C
from stable_baselines3.common.evaluation import evaluate_policy
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
from stable_baselines3.common.env_util import make_vec_env
Step 3: Create the environment
env_id = "PandaReachDense-v3"
# Create the env
env = gym.make(env_id)
# Get the state space and action space
s_size = env.observation_space.shape
a_size = env.action_space
print("\n _____ACTION SPACE_____ \n")
print("The Action Space is: ", a_size)
print("Action Space Sample", env.action_space.sample()) # Take a random actionStep 4: Normalize observation and rewards
A good practice in reinforcement learning is to normalize input features.
For that purpose, there is a wrapper that will compute a running average and standard deviation of input features.
We also normalize rewards with this same wrapper by adding norm_reward = True
env = make_vec_env(env_id, n_envs=4)
env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)Step 5: Create the A2C Model 🤖
For more information about A2C implementation with StableBaselines3 check: https://stable-baselines3.readthedocs.io/en/master/modules/a2c.html#notes
To find the best parameters I checked the official trained agents by Stable-Baselines3 team.
model = A2C(policy = "MultiInputPolicy",
env = env,
verbose=1)Step 6: Train the A2C agent 🏃
model.learn(1_000_000)
# Save the model and VecNormalize statistics when saving the agent
model.save("a2c-PandaReachDense-v3")
env.save("vec_normalize.pkl")Step 7: Evaluate the agent 📈
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
# Load the saved statistics
eval_env = DummyVecEnv([lambda: gym.make("PandaReachDense-v3")])
eval_env = VecNormalize.load("vec_normalize.pkl", eval_env)
# We need to override the render_mode
eval_env.render_mode = "rgb_array"
# do not update them at test time
eval_env.training = False
# reward normalization is not needed at test time
eval_env.norm_reward = False
# Load the agent
model = A2C.load("a2c-PandaReachDense-v3")
mean_reward, std_reward = evaluate_policy(model, eval_env)
print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")Conclusion
In conclusion, the implementation of the Actor-Critic reinforcement learning architecture within the “PandaReachDense” robotic control environment marks a significant step forward in the field of intelligent decision-making and control. The fusion of policy-based and value-based methods has demonstrated its prowess in enabling a robotic arm, equipped with its end-effector, to perform precise and dynamic interactions in complex settings.
The training process, as exemplified in this code implementation, showcases the adaptability and efficiency of the Actor-Critic approach. By seamlessly combining policy learning and value estimation, the agent becomes adept at manipulating the robotic arm’s end-effector to reach designated target positions. This not only offers a practical solution for tasks like robotic control but also holds the potential for transforming various domains requiring agile and informed decision-making.
The use of the “PandaReachDense” environment, with its dense reward function that provides continuous feedback, further emphasizes the effectiveness of this approach. The agent learns to make incremental improvements with each time step, fostering a sense of continuous progress towards task completion. This stands in contrast to sparse reward functions where success is binary, making the Actor-Critic method particularly well-suited for such tasks.
As the implementation encourages users to adapt and fine-tune the code for their specific needs, it represents a valuable resource for researchers and practitioners seeking to tackle a diverse range of complex challenges. The code offers a foundation for experimentation with neural network architectures, hyperparameter tuning, and advanced reinforcement learning techniques, serving as a launchpad for further exploration and innovation.
In summary, the marriage of the Actor-Critic architecture and the “PandaReachDense” robotic control environment not only highlights the capacity to revolutionize decision-making in robotics but also presents a versatile tool for addressing complex, real-world problems that demand precision and adaptability. It is a testament to the transformative potential of reinforcement learning in shaping the future of intelligent systems and automation.
“Stay connected and support my work through various platforms:
- GitHub: For all my open-source projects and Notebooks, you can visit my GitHub profile at https://github.com/andysingal. If you find my content valuable, don’t hesitate to leave a star.
- Patreon: If you’d like to provide additional support, you can consider becoming a patron on my Patreon page at https://www.patreon.com/AndyShanu.
- Medium: You can read my latest articles and insights on Medium at https://medium.com/@andysingal.
- The Kaggle: Check out my Kaggle profile for data science and machine learning projects at https://www.kaggle.com/alphasingal.
- Hugging Face: For natural language processing and AI-related projects, you can explore my Huggingface profile at https://huggingface.co/Andyrasika.
- YouTube: To watch my video content, visit my YouTube channel at https://www.youtube.com/@andy111007.
- LinkedIn: To stay updated on my latest projects and posts, you can follow me on LinkedIn. Here is the link to my profile: https://www.linkedin.com/in/ankushsingal/."Requests and questions: If you have a project in mind that you’d like me to work on or if you have any questions about the concepts I’ve explained, don’t hesitate to let me know. I’m always looking for new ideas for future Notebooks and I love helping to resolve any doubts you might have.
Remember, each “Like”, “Share”, and “Star” greatly contributes to my work and motivates me to continue producing more quality content. Thank you for your support!
Resources:
- https://stable-baselines3.readthedocs.io/en/master/common/atari_wrappers.html
- https://github.com/andysingal/Reinforcement_Learning/tree/main/games
- https://spinningup.openai.com/en/latest/algorithms/sac.html
- https://github.com/qgallouedec/panda-gym
- https://github.com/hill-a/stable-baselines
If you enjoyed this story, feel free to subscribe to Medium, and you will get notifications when my new articles will be published, as well as full access to thousands of stories from other authors.





