
Deep Neural Networks Improve Radiologists’ Performance in Breast Cancer Screening
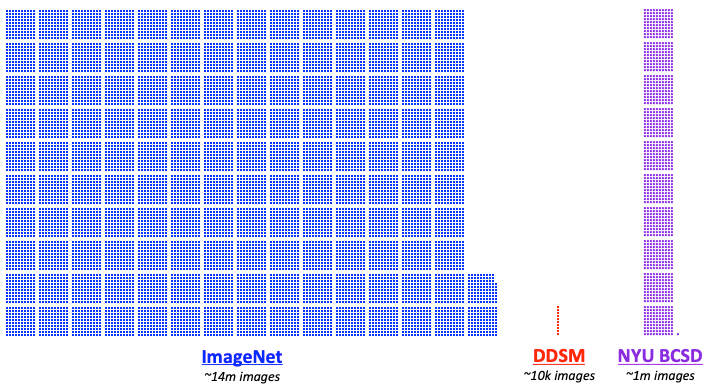
- We created a large dataset of mammograms, consisting of over 1,000,000 mammographic images (a.k.a the NYU Breast Cancer Screening Dataset), with accompanying cancer labels and lesion segmentations where applicable.
- We designed and trained a novel two-phase model for breast cancer screening that performs on par with expert radiologists in identifying breast cancer using screening mammograms.
- We are making publicly available our paper, tech report explaining our data and code and trained models.
Breast cancer is the second leading cancer-related cause of death among women in the US. Early detection, through routine annual screening mammography, is the best first line of defense against breast cancer. However, these screening mammograms require expert radiologists (i.e. physicians who completed residency training specifically in image interpretation) to pore over extremely high-resolution images, looking for the finest traces of cancerous or suspicious lesions. A radiologist can spend up to 10 hours a day working through these mammograms, in the process experiencing both eye-strain and mental fatigue.
Modern computer vision models, built principally on Convolutional Neural Networks (CNNs), have seen incredible progress in recent years. Breast cancer screening thus presents an obvious and important opportunity for the application of these novel computer vision methods. However, to truly effectively employ deep learning techniques to the problem of breast cancer screening, two important challenges need to be addressed.
Challenges
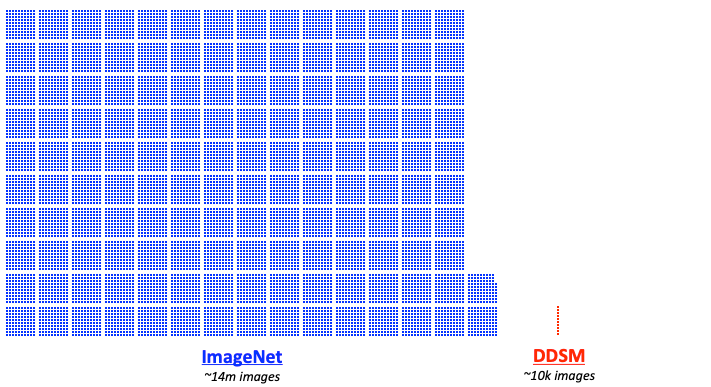
Firstly, deep learning models need to be trained on large amounts of data to be effective. For example, the ImageNet training set contains millions of images. In contrast, the most commonly used public mammography data set, the Digital Database for Screening Mammography (DDSM), contains only about ten thousand images.
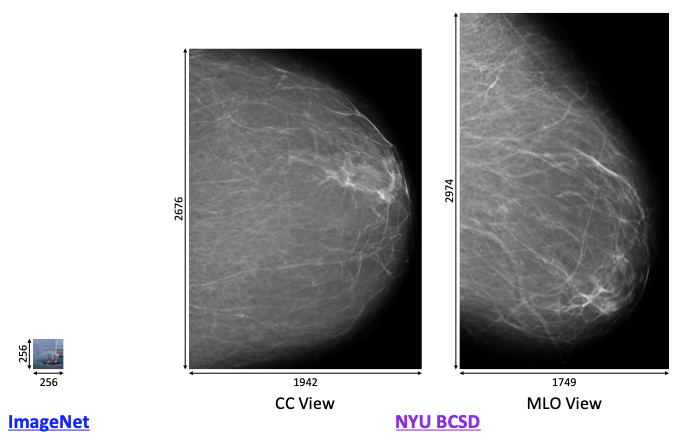
Secondly, mammographic images have extremely high resolutions. For instance, models tackling ImageNet often handle images of size 256x256. In contrast, mammogram image sizes are on the order of 2000x2000. That’s two orders of magnitude larger than what typical CNNs work with. It would be impractical to train, say, a ResNet-151 on images of this sizes on commercial-grade GPUs, as the activations and gradients would struggle to fit in GPU memory. In addition, our prior work has shown that downsampling such images can meaningfully hurt performance because of the loss of visual detail, so downsampling is not a viable alternative.
The work of our team addresses both of these issues. Let’s start with the need for more data.
The NYU Breast Cancer Screening Dataset (BCSD)
In collaboration with the Department of Radiology at NYU Langone Health, we built a massive dataset of anonymous screening mammograms, specifically with the training of deep learning models in mind. Our full dataset consists of 229,426 screening mammography exams, from 141,473 patients. Each exam consists of at least four images, corresponding to the four standard mammographic views. This dataset is enormous by medical imaging standards, let alone mammography.
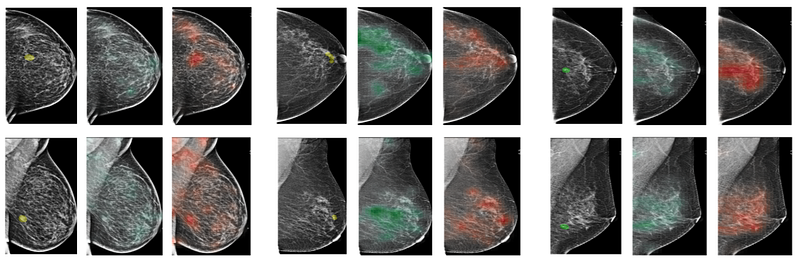
Within this dataset, about 7,000 exams were matched with corresponding biopsies (referred to as the “biopsied population”, compared to the above “screening population”). Biopsies are surgical procedures that affirmatively confirm the presence or absence of cancer. We parsed the biopsy report for each exam to extract labels indicating the presence of cancer in each breast. Furthermore, we asked 12 radiologists to hand-annotate the location of biopsied findings on each mammographic image, where applicable. This gives us pixel-level labels of where the malignant and benign findings are located.
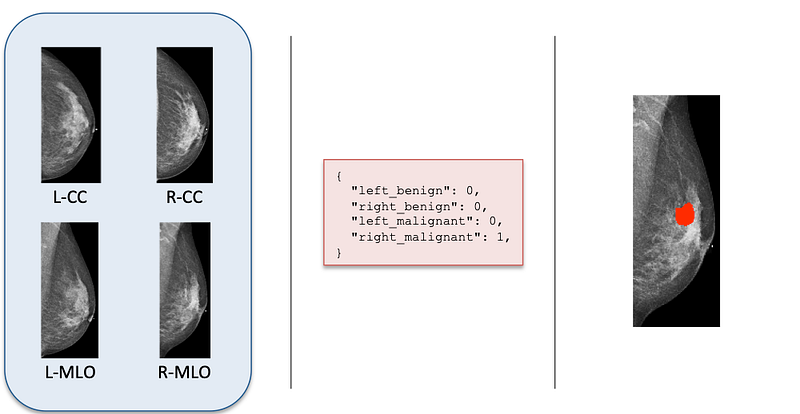
This dataset forms the foundation for all the experiments in our work, and more details about the creation, processing, extraction and statistics of the dataset can be found in our technical report.
With the data limitation out of the way, we can get to the modeling.
Deep Learning for Breast Cancer Screening
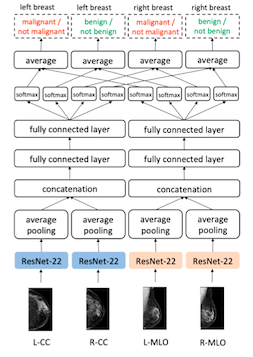
We use a multi-view CNN, which takes as input the four mammographic images. The model consists of four custom ResNet-22 columns — one for each mammographic view — followed by two fully connected layers that output four separate prediction labels: the presence of benign and malignant findings, in left and right breasts. In total, this model has about 6 million trainable parameters. We refer to this model as the “image-only” model, for reasons that will soon become apparent.
We train the model on a mix of data from the exams matched with biopsies, which have explicit cancer labels from biopsy reports, as well as exams not matched with biopsies, which we treat as the absence of cancer. The model is trained to predict all four labels for each exam.
Although we have a large dataset of mammograms, because we have relatively few positive examples of cancer compared to negative examples, training a model from scratch with such a limited training signal can be problematic. We take a quick detour to address this issue.
Transfer Learning with BI-RADS Classification
Although we cannot use pretrained image classification models for our task, we can still apply transfer learning to cancer classification. Building on our prior work, we pretrain a model for a similar task: BI-RADS classification.
In mammography, BI-RADS labels are a standardized radiologist assessment of a patient’s chance of having breast cancer based on a mammogram. Being primarily an estimate of risk used to guide further workup and testing (if indicated) rather than a diagnosis, BI-RADS categories are a much noisier training signal than cancer labels from biopsies. Nevertheless, they correspond roughly to the downstream problem of cancer classification, allowing the model to learn to identify exams suspicious for malignancy, exams which contain clearly benign findings and exams which are clearly normal.
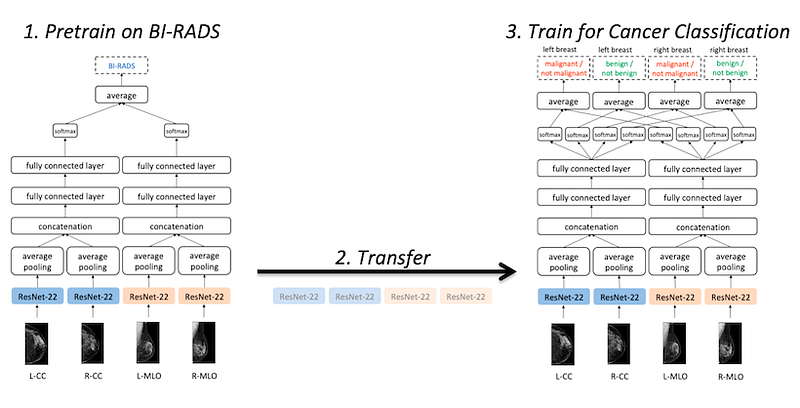
The architecture of our BI-RADS classification model is identical to that of our cancer classification model, except the final layer outputs BI-RADS categories. After training the model on BI-RADS classification, we then take the weights from the ResNet-22 columns and use them to initialize our cancer classification model.
With transfer learning from BI-RADS classification, we can already train a fairly accurate breast cancer classification model. However, this comes at the cost of using a model with less capacity, with a shallower ResNet for processing visual features. Is there a way that we can take advantage of a deeper model while still training on full-resolution mammograms?
Clearly, something has to give. In our case, we make the following compromise: What if we give up end-to-end training?
Patch-level Cancer Classification
Remember the pixel-level segmentations? They could serve as an extremely powerful training signal, telling us exactly where a suspicious change is located in a mammogram. While we could directly train a localization model for identifying cancers, here we’ll target something much simpler: classifying patches.
From our big dataset of mammograms, we randomly sample 256x256 patches from our full mammogram images. If a sampled patch overlaps with an annotated lesion, we assign the patch the corresponding label: malignant, benign or a negative label. Then, we train a model to classify these patches.
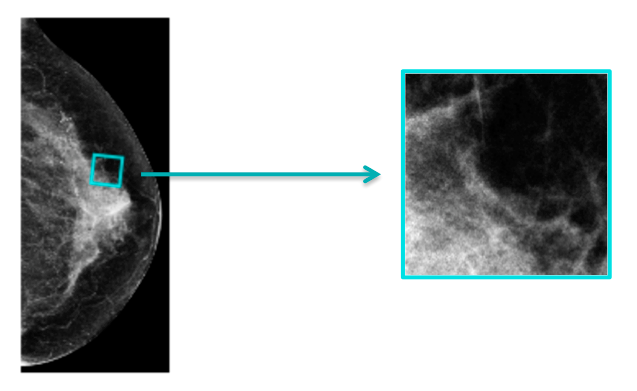
With 256x256-sized patches, not only can we use a model with higher capacity, it also means that we can use off-the-shelf models trained for ImageNet. We experimented with a large number of existing models, and found DenseNet-121 to perform best. Because we’re sampling small patch from large mammograms, we can sample and train a very large number of these patches–we end up training the model for 1,000 epochs on 5,000,000 sampled patches. This model performs exceedingly well on this patch-classification task.
Importantly, the patch-classification model has a significant limitation: by operating on small patches of the full mammograms, it lacks information from the full context of a mammogram. In practice, radiologists routinely make clinical determinations based on whole breast evaluation comparing tissue in different regions of a breast, different mammographic views of the breast or even between breasts. The patch classification model, while having extremely high capacity, is constrained to use very local features. It effectively misses the forest for the trees.
In contrast, our “image-only” model was able to use information from all parts of a mammogram, but had far less capacity. So is there a way we can combine the benefits of both?
Patch-Classification Heatmaps: Seeing both the forest and the trees
Since our patch-level classifier is so good at mammogram patches, why don’t we try using the output of the patch-level classifier as an input to the “image-only” model?
We do just that: we apply the (trained and frozen) patch classifier in a sliding window fashion across the entire high-resolution mammogram, generating a sort of “heatmap” of predictions. We extract heatmaps for both the benign and malignant predictions from the patch classifier.
We then append these heatmaps as additional channels to our actual mammogram images. We modify our “image-only” model to take inputs of three channels: the mammographic image, the ‘benign’ patch heatmap and the ‘malignant’ patch heatmap. We call this the “image-and-Heatmaps” model. Training this model thus requires us to first run the patch classifier across the whole mammogram to generate the heatmaps, and then us both the mammogram images and heatmaps as inputs to the model. It turns out that this works really well.
Results
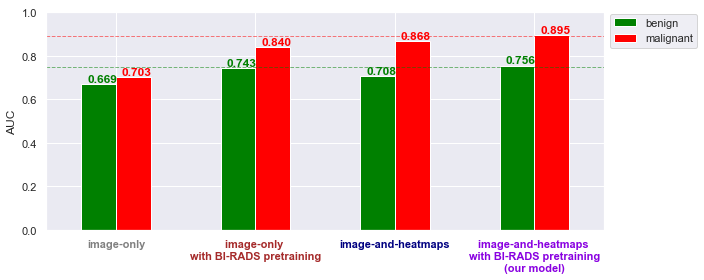
We measure the performance of our model using the area under the ROC curve (AUC for short). We find that using BI-RADS pretraining and patch classification heatmaps both help significantly, and the combination of both does even better. Despite having fewer positive examples, our models actually perform better on accurately classifying malignant cases than benign cases. This may be because benign cases are often harder to spot, in many cases being “mammographically occult”, which means that radiologists conclude that the benign lesion could not have been identified from mammograms alone. In these cases, these benign lesions were usually identified and worked up on other screening methods (for example, breast ultrasound or MRI).
Comparison to Radiologists
An important question to ask for models trained on medical data is: how well do they work in practice? To answer this question, we conducted a reader study. Using a subset of our test set, comprising both positive and negative examples of cancer, we asked a group of 14 radiologists with varying levels of experience to determine the presence of malignant lesions based on just the screening mammograms. We compared their predictions to our model’s predictions. (Note: the distribution of sampled exams for the reader study is slightly different from the full test set, so the AUC numbers here are not directly comparable to those in the table above.)
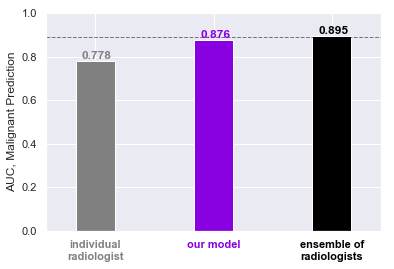
Impressively, our model performs at least as well as an average individual radiologist on this task. While the model still somewhat underperforms the averaged predictions of all 14 radiologists — effectively an ensemble of radiologists — this already demonstrates the utility of our model. (In practical terms, it would be unrealistic to have every screening mammogram be looked over by that many radiologists, as the standard of care in the United States is a single radiologist reading the study.) In outperforming an average individual radiologist, our model may potentially be used to assist a radiologist tasked with going through 80–150 screening mammograms a day.
It is worth noting here that this task in our reader study is a simplification of what radiologists do in reality. As mentioned above, based on screening mammograms, radiologists only assign BI-RADS labels: an assessment of risk. To actually perform a full diagnosis of cancer, radiologists ask the patient to return for additional images and rely on a suite of other imaging techniques: diagnostic mammography (similar to screening mammography but where other specialized views focusing on a smaller area in the breast are also used), ultrasound and MRI, which can be concluded with a biopsy to make a final determination.
Hence, this result can be seen from two perspectives. On one hand, classifying breast cancer screening exams alone is not a task that radiologists are typically trained or expected to do. On the other hand, we show that our model is able to predict the presence of cancer, a downstream goal, using only screening mammograms, and this could potentially be of great help to radiologists.
We can go one step further: what if we combined the expertise of radiologists with the accuracy of our model?
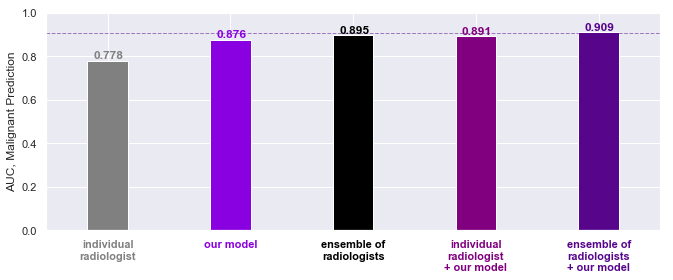
We find that the combination of the radiologist and our model is actually even better. This shows not only that radiologists and the model specialize in different aspects of this task, but further that having radiologists working in conjunction with the model actually leads to even more accurate predictions. In our opinion, this is the true takeaway from our work–that our models can be used to not substitute but assist radiologists with their work, leading to better outcomes for patients.
Conclusion
The confluence of the deep learning revolution in computer vision and the growth of medical imaging technology has opened the doors to a new wave of research at the intersection of machine learning and healthcare. Today, we have a real chance to apply cutting-edge machine learning methods to improve millions of lives, and the close collaboration between the NYU Center for Data Science and the Department of Radiology at NYU Langone Health has presented just such an opportunity. This research was the product of integrating medical knowledge and machine learning expertise, and combining the power of modern medical imaging technology with the power of cutting-edge computing hardware.
We are proud to present our work on applying deep learning to the problem of breast cancer screening, and the accompanying report detailing our data creation procedure. We have shown that trained neural networks can not only perform comparably to trained radiologists on the task, but furthermore can meaningfully improve the accuracy of radiologists and assist them with their work. We believe this is an exciting result, and we are happy to share both our methods, as well as our code and trained models with the world. By opening our models to the public, we hope to invite other research groups to both independently validate and furthermore build on our work.
Of course, this is just the beginning. There are many further problems we want to solve. Can we train models to directly localize and classify cancer lesions? Can we train models to better incorporate past patient exams, just as radiologists compare different sets of exams from the same patient in making determinations? And can we make these models interpretable, to understand how they are making their judgments, and in turn provide that additional knowledge to radiologists and doctors? These are just some of the questions we are working to answer in the near future, and we cannot wait to let you hear about more soon.
- Read more about our methods in the paper.
- Learn about our dataset construction in the technical report.
- Download our code and trained models.
This work was done by Nan Wu, Jason Phang, Jungkyu Park, Yiqiu Shen, Zhe Huang, Masha Zorin, Stanisław Jastrzębski, Thibault Févry, Joe Katsnelson, Eric Kim, Stacey Wolfson, Ujas Parikh, Sushma Gaddam, Leng Leng Young Lin, Kara Ho, Joshua D. Weinstein, Beatriu Reig, Yiming Gao, Hildegard Toth, Kristine Pysarenko, Alana Lewin, Jiyon Lee, Krystal Airola, Eralda Mema, Stephanie Chung, Esther Hwang, Naziya Samreen, S. Gene Kim, Laura Heacock, Linda Moy, Kyunghyun Cho, and Krzysztof J. Geras.
