
Deep learning on a combination of time series and tabular data.

We often times find ourself in a situation where we have combination of different features that we want to leverage in our model. The input data to your model is a mix of time series and tabular data. Architecting a deep learning model to work well in this scenario is an interesting problem.
One example scenario is: You have data from a device like fitbit and you want to predict a sleep stage at any given minute:
You have a mixture of:
Time series inputs:
- sequence of heart rate
- sequence of respiratory rate
Tabular features:
- time since sleep onset
- personalized embedding representing this users sleep pattern
and bunch of other features.
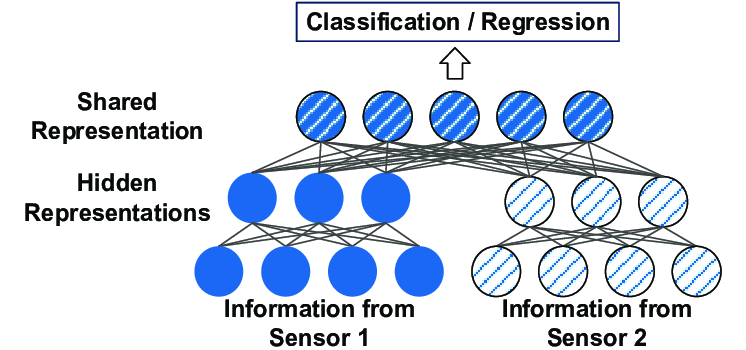
One way to approach this is treat it as multimodal deep learning.
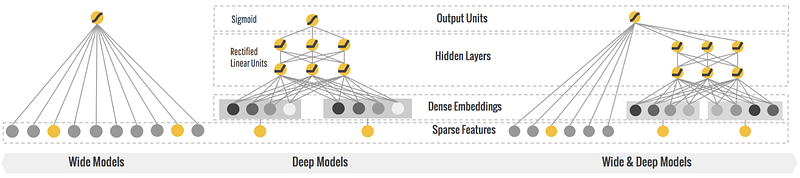
And mix in “wide and deep learning” as introduced by google research here
So how do we go about this?
- Pass in time series sequence though an RNN or LSTM or 1D CNN and capture the hidden state or CNN embedding as a representation of the sequence.
- Concatenate embeddings for each of the sequence with other tabular features.
Some interesting decisions to consider:
For the multiple time series input sequences:
- do you treat the sequences independent and fuse/concatenate the representations late (late fusion)?
- Or do you treat them as multi-channel input with each time series as a channel (early fusion)?
In general late fusion seems to work better than early fusion and also does not require padding the input when different input sequences are not of same length. However it is really dependent on the problem space and correlation of input sequences.
In general RNN seems to work better for shorter sequences and bidirectional LSTM for longer sequences. In late fusion you can mix and match RNN/LSTM/1d CNN for different sequences.
Here is a sample model implementation (in pytorch):
This example uses 2 layer bidi LSTM with late fusion.
For each of the time series features (feature_1 and feature_2) we also have the baseline values, hence we have fusion layers where we fuse representation of sequence (hidden state of LSTM) with the baseline values. However this fusion layer is not necessary and is not required in the absence of baseline values.
class TestModel(nn.Module):
def __init__(self):
super().__init__()
self.input_size = 70
self.hidden_size = 8
self.num_layers = 2
self.output_dim = 2
self.lstm_feature_1 = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True,
bidirectional=True)
self.lstm_feature_2 = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True,
bidirectional=True)
self.fc_feature_1 = nn.Linear((self.hidden_size * 2) + 1, 1)
self.fc_feature_2 = nn.Linear((self.hidden_size * 2) + 1, 1)
self.fc = nn.Linear(4, self.output_dim)
def forward(self, f, device=None):
if not device:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
x_f1, f1, x_f2, f2, f3, f4 = f
# x_f1 is feature_1_seq
# f1 is feature_1_baseline
# x_f2 is feature_2_seq
# f2 is feature_2_baseline
# f3 and f4 are tabular features
x_f1 = x_f1.view(x_f1.shape[0], 1, -1)
h0_f1, c0_f1 = self.init_hidden(x_f1, device)
h_t_f1, c_t_f1 = self.lstm_feature_1(x_f1, (h0_f1, c0_f1))
x_f1 = h_t_f1
x_f1 = x_f1.view(x_f1.shape[0], -1)
x_f2 = x_f2.view(x_f2.shape[0], 1, -1)
h0_f2, c0_f2 = self.init_hidden(x_f2, device)
h_t_f2, c_t_f2 = self.lstm_feature_2(x_f2, (h0_f2, c0_f2))
x_f2 = h_t_f2
x_f2 = x_f2.view(x_f2.shape[0], -1)
x_f1 = torch.cat((x_f1, f1), 1)
x_f1 = self.fc_feature_1(x_f1)
x_f2 = torch.cat((x_f2, f2), 1)
x_f2 = self.fc_feature_2(x_f2)
x = torch.cat((x_f1, x_f2, f3, f4), 1)
x = self.fc(x)
x = F.log_softmax(x, dim=1)
return x
def init_hidden(self, x, device):
batch_size = x.size(0)
h0 = torch.zeros(self.num_layers * 2, batch_size, self.hidden_size).to(device)
c0 = torch.zeros(self.num_layers * 2, batch_size, self.hidden_size).to(device)
return h0, c0If you have worked on a problem that has involved similar style of input: I would love to hear from you on what has worked for you or any other ways you have tried to approach it.




