
Deep Learning has (almost) all the answers: Yes/No Question Answering with Transformers

Boolean Question Answering may seem like an easy task but it is surprisingly difficult and current baselines are not remotely close to human performance levels.
In this story we’ll see how to use the Hugging Face Transformers and PyTorch libraries to fine tune a Yes/No Question Answering model and establish state-of-the-art* results. You can find the full code notebook here.
Disclaimer: This post aims at delivering a short and easy-to-use pipeline for Boolean Question Answering. If you’re looking for some more background reading I recommend having a look at this comprehensive review of the current NLP/Question Answering landscape.
Why Boolean Question Answering is amazing
These days Extractive Question Answering gets all the hype. However, ignoring Yes/No Question Answering would be missing half of the picture. Indeed, answering closed-form questions has tremendous value. Here is a non-exhaustive list of use cases in the industry:
- Search engines: knowledge base querying, conversational agents…
- Automatic information extraction: form filling, parsing large documents…
- Voice user interfaces: smart assistants, vocal conversation parsing…
Now that we have established that Yes/No Question Answering is awesome, let’s have a look at the data.
Dataset: BoolQ
BoolQ is a reading comprehension dataset built by researchers from Google AI Language. An example in the dataset consists of a question, a paragraph and an answer which is either yes or no.

The data collection pipeline is the following (a more detailed explanation is given in the paper):
- Questions originate from past queries to the Google search engine
- They are kept if a Wikipedia article is returned
- In those instances, the question/article pairs are given to a human for annotation.
- The annotator finds a passage within the article answering the question and labels the answer
- question/passage/answer pairs are returned
Ultimately 13K pairs are gathered from this pipeline along with 3K pairs from the Natural Questions training set. These examples are split into a 9.4K train set, 3.2K dev set and an unreleased 3.2K test set.
As shown below, various kinds of inference are necessary to answer the questions.

The BoolQ team obtained its best results with BERT-large pre-trained on the MultiNLI dataset. Note that the majority-baseline yields an accuracy of 62% while human annotators reached 90% accuracy (on 110 cross-annotated examples).
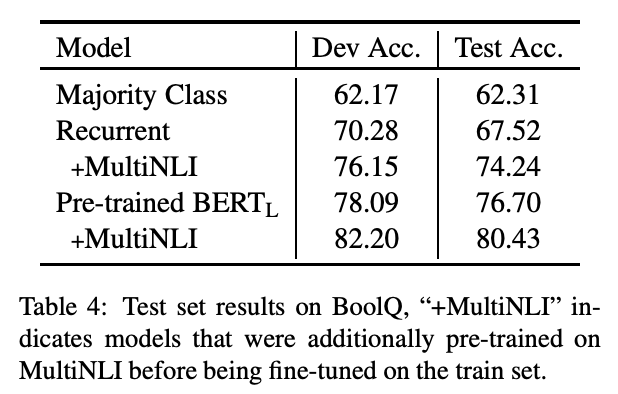
These results show the power of Transformer models for language understanding. However, as we will see, there is still room for improvement!
Model: RoBERTa
RoBERTa: A Robustly Optimized BERT Pretraining Approach is a language model released by researchers from Facebook AI. In a nutshell, BERT’s little sister is the aggregation of several improvements added on top of the original BERT architecture. The key differences are the following (a more thorough analysis is conducted in the paper):
- Masked language modelling (MLM) is done with dynamic masking rather than static masking (Section 4.1)
- The Next Sentence Prediction training objective is dropped altogether (Section 4.2)
- 500K optimization steps are performed on mini batches of size 8000 rather than 1000K steps on mini batches of size 256 (Section 4.3)
- Text encoding is handled by an implementation of BPE using bytes as building blocks rather than unicode characters (Section 4.4)
- Pretraining over more data (from 16 GB to 160 GB) as explained in Section 5

RoBERTa outperforms BERT on all 9 of the GLUE tasks as well as on the SQuAD leaderboard. This is quite impressive considering that RoBERTa and BERT share the same MLM pretraining objective and architecture.
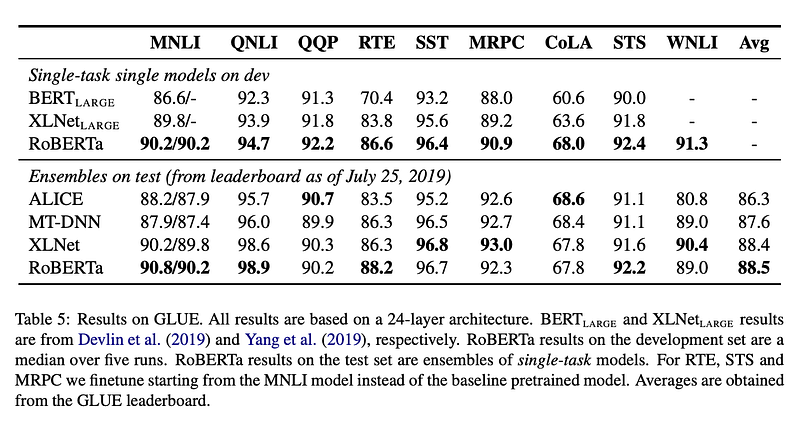
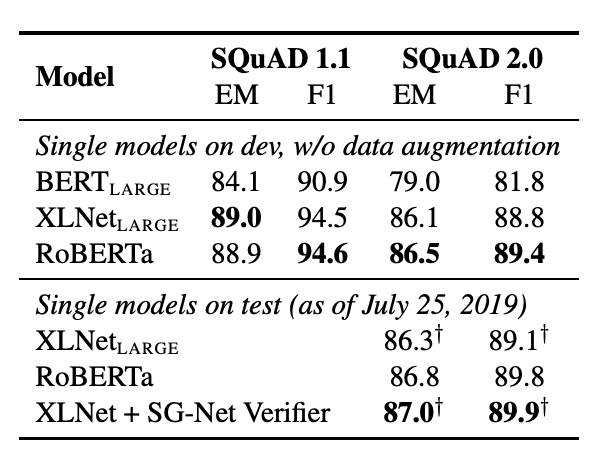
According to the authors “this raises questions about the relative importance of model architecture and pretraining objective, compared to more mundane details like dataset size and training time that we explore in this work”. However, ALBERT and ELECTRA are the newest kids in the block and they’ve set the bar even higher in the GLUE and SQuAD leaderboards.
Hands-on Yes/No Question Answering
Now that we are acquainted with the dataset and model, let’s get to work!
Mission statement:
Beat the development set results obtained by the BoolQ team. RoBERTa will be our weapon of choice.
Setup
The training and development sets can be downloaded at:
Regarding your development environment I suggest using Google Colab since it offers free GPUs.
You will need to install the following libraries:
pip install torch torchvision
pip install transformers
pip install pandas
pip install numpyAnd you can download the data with the following commands:
gsutil cp gs://boolq/train.jsonl .
gsutil cp gs://boolq/dev.jsonl .Model loading
Thanks to the Transformers library, loading a model and its associated tokenizer is painless. We start with RoBERTa-base (125M parameters). As for the optimizer, we will use Adam and the learning rate recommended in the BoolQ paper.
Data loading
First, we define a helper function to handle the tokenization process. Indeed, encode_data will take care of the following steps:
- Split the questions and passages into tokens
- Add the sentence start token
<s>and the</s>token denoting the separation between question and passage as well as the end of the input - Map the tokens to their IDs
- Pad (with the
<pad>token) or truncate every question/passage pair to amax_seq_length - Produce attention masks to discriminate relevant tokens from padding tokens
Note that max_seq_length has to be smaller than 512 which is the standard input capacity for BERT-like models.
Now that the data has been converted to RoBERTa-friendly features, we are left with building PyTorch Dataloaders.
Feel free to play with the batch_size parameter but keep in mind that larger batch sizes will require more GPU memory.
Training and Evaluation
The procedure consists in two phases that we alternate every epoch:
Training:
- Sample a batch and load it into the GPU if we have one
- Feed it to the model which will return the batch loss
- Backpropagate the loss and clip the gradients to avoid exploding gradients
- Perform an optimization step
Evaluation:
- Sample a batch and load it into the GPU if we have one
- Feed it to the model which will return the batch logits
- Use the logits to make predictions
- Compute the accuracy of our model
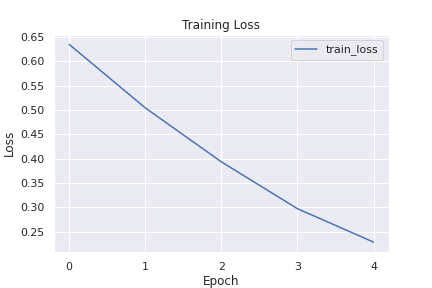
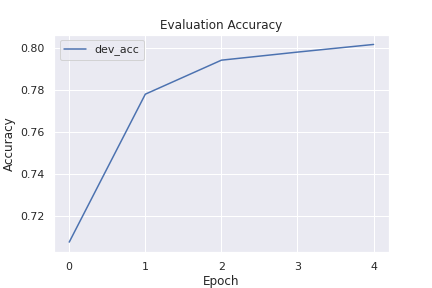
These results look promising. We’re pretty close to BERT-large (340M parameters) performances with a much smaller model. Let’s scale things up and use RoBERTa-large instead. To do so we only need to make a few tweaks:
- Replace
"roberta-base"by"roberta-large"in the Model loading code snippet (line 10) - Set
batch_sizeto 8 in the PyTorch Dataset building code snippet (line 1) since the larger model will take more GPU memory - Set
epochsto 3 andgrad_acc_stepsto 4 in the Training and Evaluation code snippet (line 1-2) in order to keep training time in check and an effective batch size of 32 - Run the pipeline again
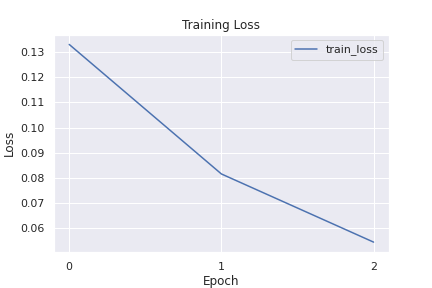
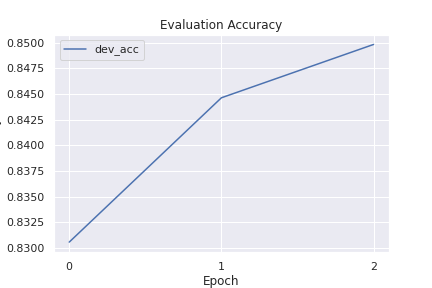
Voilà ! State-of-the-art results for Yes/No Question Answering.
Prediction
Let’s test our model on a paragraph from the SQuAD dataset:


As expected the model predicts the correct answers 🚀
To sum up, we saw that Boolean Question Answering is a difficult problem with many use cases. Through a practical guide, we fine-tuned RoBERTa on the BoolQ dataset in order to establish SOTA results.
Next steps
Next steps would consist in:
- Trying out newer models such as ALBERT and ELECTRA
- Reducing inference times through Knowledge Distillation
- Combining Yes/No Question Answering with Extractive Question Answering
- Perform data augmentation to increase the number of training samples
References
- BoolQ paper: https://arxiv.org/abs/1905.10044
- RoBERTa paper: https://arxiv.org/abs/1907.11692
- BERT paper: https://arxiv.org/abs/1810.04805
*Note that T5 superseded RoBERTa in the SuperGLUE leaderboard