
使用Pre-training的方法與時機
在做大部分deep learning任務時,使用pre-training模型是很常見的做法。雖然Kaiming He在2018年的Rethinking ImageNet Pre-training論文中提到即使train from scratch也可以達到使用pre-training模型的高度,不過pre-training的研究並沒有因此停止,隨著self-training、self-supervised learning、semi-supervised learning、domain adaption的流行越來越精彩。
今年 (2020年5月) Google Brain團隊開源了BiT (Big Transfer) 的程式碼,企圖在computer vision領域建立一個pre-training模型的標竿。這同時也是一個相當好的時機去回顧、思考這幾年關於pre-training的討論。

這篇文章會介紹pre-training、fine-tune與adaption的觀念,並透過分享兩篇論文的觀點:打破pre-training神秘力量傳說的Rethinking ImageNet Pre-training[1]與大力擁抱pre-training的BiT (Big Transfer)[2],對於何時使用pre-training給予一些insights與建議。
文章難度:★★☆☆☆ 閱讀建議:本篇文章前段的 pre-training、fine-tune簡介為相當基礎的部分。後續介紹為使用 pre-training的時機與價值,會是比較應用、工程角度的觀點。 推薦背景知識:transfer learning、domain adaption、model regularization。
Basic Idea about Pre-training
所謂的pre-training指的是利用不同domain/dataset的資料,預先透過相同或不同的任務訓練backbone網路,之後使用這些訓練好的參數做為新的網路的初始參數。而在目標任務下訓練,則稱為fine-tune。一般來說,pre-training與fine-tune的網路大部分架構會沿用,如BiT的示意圖一樣。另外,若不使用pre-training模型直接從頭訓練,稱為train from scratch。
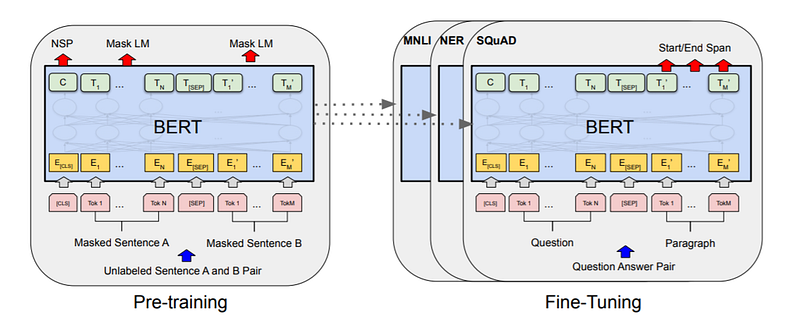
Pre-training的優點
一般來說,在訓練網路時使用pre-training model的優點主要有兩個:
- 減少訓練時間:由於網路已經預先訓練在相似的資料上,可以加快模型的收斂時間。比如說在ImageNet上透過分類問題pre-training的模型,已經透過影像的分類任務了解了影像的線條、紋路等意義,因此可以快速地adapt到其他影像任務上。
- 減少target domain所需資料數量:如上所說,pre-training可以幫助模型認識general的知識,因此可能可以使用較少的target domain資料,訓練出泛化性好的模型。不過這點其實是個相當信仰的感覺,因為其實我個人沒有看過單獨研究data數量與pre-training關係的論文。
Pre-training的缺點
基本上,我目前沒看過有論文或業界指出因為使用了pre-training model,所以model收斂結果很差的情況。因此,我個人認為pre-training唯一的缺點在於以下三點同時發生時才存在:(1) 若使用非常見網路架構,而必須自己pre-training;(2) pre-training+fine-tune時間大於train from scratch;(3) 使用pre-training的模型表現相比train from scratch沒有明顯優勢。
簡單來說,就是這個任務真的不需要 pre-training。
Rethinking Pre-training
以前在做模型訓練時有個類似都市傳說的一個說法:使用pre-trained model的模型結果一般會比較好。實際上相信關於這個說法很多人都是半信半疑,而2018年Rethinking ImageNet Pre-training這篇論文終於以實驗數據與討論終結了這個都市傳說。這篇論文乍看好像就是訴說著pre-training的非必要性,但其實更重要的是關於使用pre-trained model或是train from scratch在調參上的一些insights。
1. Train from scratch並不會比較差
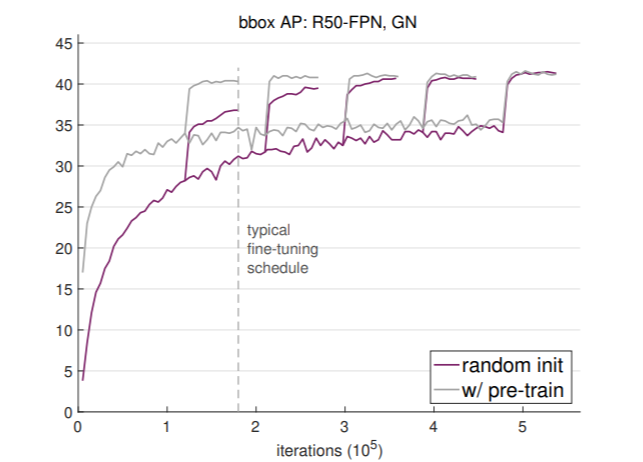
這篇論文首先使用了ResNet-50 FPN與global normalization的Mask R-CNN,展示了可以在完全不透過ImageNet pre-train的情況下,達到一樣的準確度(bounding box AP)。實驗數據可以參考前面的figure 2。
2. Pre-training可以使模型提早收斂
在figure 2中,pre-trained model收斂速度確實更早了一些,而且這個現象隨著model大小變大也更加明顯。這邊也影響了一個關鍵:由於模型收斂時間不同,learning rate scheduling調降的時間點就會變得非常關鍵。也就是figure 2中準確度突然拉升的位置。
3. Pre-training不見得會減緩over-fitting (除非dataset很小)
論文透過實驗展示了即使使用pre-trained model,在不好好調整的情況下依然無法避免over-fitting (即他的論點-pre-training不見得會減緩over-fitting),並依序展示了即使只使用一部分的target domain資料 (10K),pre-trained model也沒有明顯優勢。
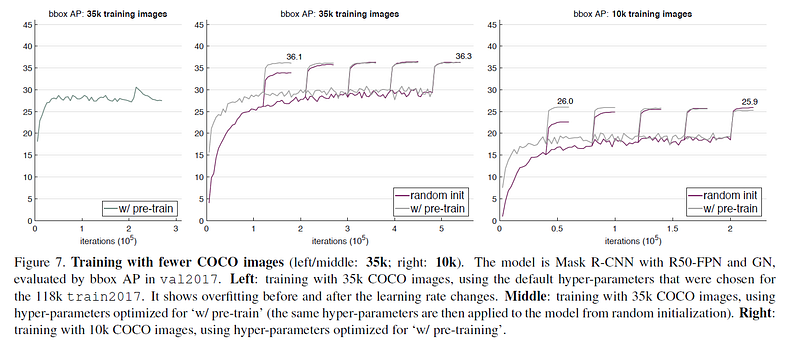
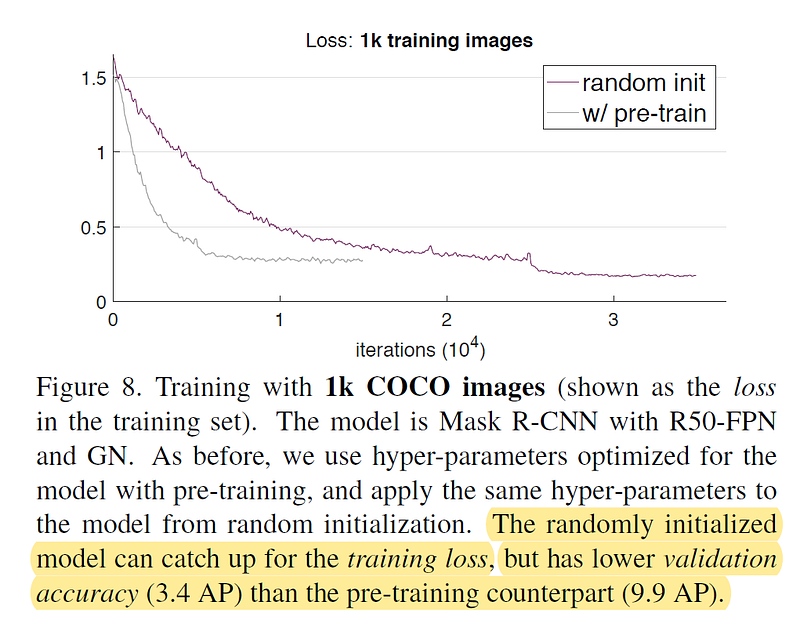
不過在只有很少量的target domain資料時,pre-training優勢就相當可見了。
4. Pre-taining對同質性不高的任務幫助較小
這句話聽起來是個廢話,論文中是用ImageNet的classification label做pre-training,target任務則是keypoints detection。而實驗數據顯示不只是結果沒有比較好,連收斂速度都沒有明顯的優勢。

Rethinking ImageNet Pre-training實際上在論文的結尾肯定了pre-training的意義 (加速收斂,增加小dataset泛化能力等),但是否定ImageNet pre-training的必要性。而上述的論點1與2上是沒什麼疑意的,不過論點3,後續有一些論文認為pre-training實際上是對model robustness有幫助的,只不過當初使用的evaluation metrics無法有效地評估robustness。而論點4隨著BiT的出現,好像暗示著pre-training其實有能力在不同任務的adaption上有所貢獻。
BiT (Big Transfer)
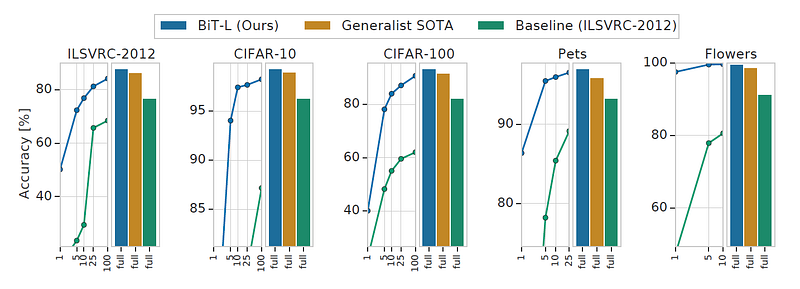
BiT是Google最新開源的視覺任務pre-trained模型,在不同的任務與不同的dataset中刷新了不少SOTA (state-of-the-art)的紀錄。在不增加任何新的技巧的情況下,展現了當代頂尖的pre-training & transfer能力。
快速理解BiT
BiT論文並沒有特殊的新技巧,在網路架構上,只有兩件顯著的設計:
- 使用更寬 (更大的channel) 的網路:許多研究紛紛指出大的網路效果好,大的dataset需要大的網路架構。
- 使用GN (group normalization) [5]與WS (weight standardization) [6]:大的網路受限於memory,通常batch不能開太大,這也導致了batch normalization的統計有誤差。另外,論文非常明確的認定batch normalization對於task transfer有害。
而論文中提到的三種模型名稱BiT-S、BiT-M、BiT-L其實不是架構上不同,而是用不同的pre-training dataset。S、M、L分別對應了:ILSVRC-2012 (1.3M images)、ImageNet-21k(14M images)、JFT(300M images)。而模型架構論文預設是使用ResNet152x4,及加寬4倍 (channel x4) 的ResNet152。
事實上BiT並沒有在所有dataset上達到SOTA,這也不是他的本意。BiT目標是一個輕鬆、易調整的general pre-training概念。而在fine-tune時超參數的調整邏輯,他們命名為BiT-HyperRule。
小結論
對比Rethinking ImageNet Pre-training一文與BiT論文,總會覺得有哪裡卡卡的。事實上,兩篇論文出發的觀點不同,前者想強調的是不一定要pre-training,而後者則是想盡力放大pre-training的優勢,結果也並不算矛盾。
整體上在pre-training上整個風向還是傾向能pre-training就pre-training,畢竟即使沒有優勢,也不會拉低模型表現。回到標題-使用Pre-training的方法與時機,以下是我個人考量使用pre-training的食譜。
- 自己的模型使否有公開pre-training好的參數。若有,選pre-training任務最接近的參數來用。
- 若沒有,觀察自己的dataset數量是否夠、是否有足夠的variance。若足夠全面,可以直接train from scratch,訓練過程的中前段可以留一個checkpoint加速未來實驗。
- 若沒有,挑選domain盡量接近的公開dataset自己pre-training。
事實上,雖然[1]在論文中認為 pre-training on ImageNet不會讓model變得更robust,不論2019年 ICLR的一篇論文[3]在開頭就這樣說:
He et al. (2018) have called into question the utility of pre-training by showing that training from scratch can often yield similar performance to pre-training. We show that although pre-training may not improve performance on traditional classification metrics, it improves model robustness and uncertainty estimates.
或許這邊之後還有機會有更多的討論吧!
老話一句:Deep Learning領域每年都會有大量高質量的論文產出,說真的要跟緊不是一件容易的事。所以我的觀點可能也會存在瑕疵,若有發現什麼錯誤或值得討論的地方,歡迎回覆文章或來信一起討論 :)
Related Topics
References
- Kaiming He, Ross Girshick, and Piotr Dollar. “Rethinking ImageNet Pre-training“ [arXiv]
- Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. “Big Transfer (BiT): General Visual Representation Learning” [arXiv]
- Dan Hendrycks, Kimin Lee, and Mantas Mazeika. “Using Pre-Training Can Improve Model Robustness and Uncertainty” [arXiv]
- Open-Sourcing BiT: Exploring Large-Scale Pre-training for Computer Vision [Google AI Blog]
- Group Normalization [arXiv]
- Weight Standardization [arXiv]




