
Deep Deterministic Policy Gradients (DDPG): Bridging the Gap between Continuous Action Spaces and Reinforcement Learning
Introduction
Reinforcement learning (RL) has witnessed significant advancements in recent years, driven by the development of algorithms that enable agents to learn and adapt to their environments. One of the key challenges in RL is dealing with continuous action spaces, which arise in many real-world applications. Traditional RL algorithms like Q-learning and policy gradient methods are designed for discrete action spaces and struggle when confronted with continuous actions. Deep Deterministic Policy Gradients (DDPG) is a breakthrough algorithm that addresses this challenge by allowing RL agents to navigate in continuous action spaces efficiently. This essay delves into the fundamentals, characteristics, and applications of DDPG, shedding light on its significance in the field of reinforcement learning.
Deep Deterministic Policy Gradients (DDPG): Forging the Link Between Continuous Action Spaces and Reinforcement Learning.
Foundations of DDPG
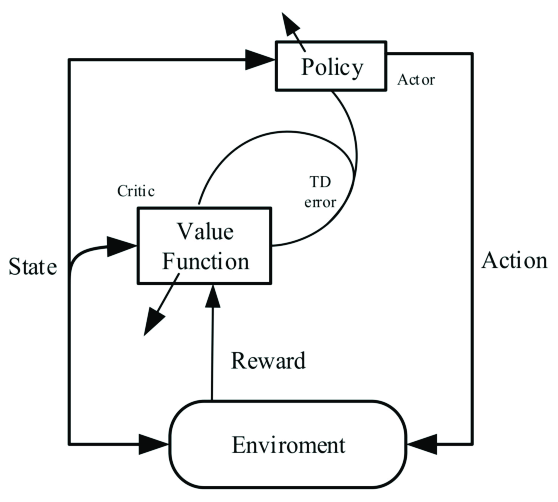
DDPG is an actor-critic algorithm, combining the advantages of policy-based and value-based approaches. It was introduced by Timothy P. Lillicrap et al. in the paper “Continuous control with deep reinforcement learning” in 2016. DDPG extends the DQN architecture, which is well-known for its success in handling high-dimensional state spaces. The key innovation is to adapt DQN to continuous action spaces.
- Actor-Critic Architecture: In DDPG, the agent employs two neural networks: an actor and a critic. The actor network is responsible for selecting actions based on the current state, while the critic network evaluates these actions. The actor aims to maximize the expected return, while the critic assesses the quality of the chosen actions by estimating the action-value function. By maintaining these two networks, DDPG strikes a balance between exploration and exploitation, which is essential for efficient learning.
- Target Networks: DDPG incorporates the idea of target networks to enhance stability during training. It employs target actor and critic networks, which are slowly updated with the main actor and critic networks. This stabilization technique mitigates the problem of divergence that can occur during training.
- Ornstein-Uhlenbeck Noise: To encourage exploration in continuous action spaces, DDPG introduces the Ornstein-Uhlenbeck (OU) process, a stochastic process that adds temporally correlated noise to the actions. This noise is crucial for preventing the agent from getting stuck in local optima and facilitating effective exploration.
Characteristics of DDPG
DDPG exhibits several notable characteristics that make it a prominent choice in various RL applications:
- Handling Continuous Action Spaces: The most distinguishing feature of DDPG is its ability to handle continuous action spaces. Traditional RL algorithms struggle when actions are not discrete and finite. DDPG leverages deterministic policies, allowing agents to produce continuous-valued actions with ease.
- Sample Efficiency: DDPG is relatively sample-efficient compared to other RL algorithms. The off-policy nature of DDPG enables it to reuse past experiences efficiently, accelerating the learning process. This property is particularly valuable in real-world scenarios where data collection can be expensive or time-consuming.
- Stable Training: The use of target networks in DDPG contributes to stable training. By reducing the variance and potential divergence issues, DDPG converges more reliably and is less prone to oscillations.
- Exploration-Exploitation Tradeoff: The incorporation of OU noise in the actions ensures a balance between exploration and exploitation. Agents are encouraged to explore the action space while gradually exploiting learned policies.
Applications of DDPG
DDPG has found applications in a wide range of domains, including robotics, autonomous control, finance, and games. Some notable use cases include:
- Robotics: DDPG has been employed to train robotic agents to perform tasks with continuous and high-dimensional action spaces. This includes tasks such as robotic arm control, locomotion, and manipulation.
- Autonomous Vehicles: In autonomous driving and drone control, DDPG has been used to navigate vehicles in continuous and dynamic environments, making decisions like steering, throttle, and braking.
- Finance: DDPG has shown promise in optimizing trading strategies for financial assets by dynamically adjusting portfolio allocations in response to market conditions.
- Gaming: In the gaming industry, DDPG has been used to train agents for various video games, including both virtual and physical games, where precise and continuous control is essential.
Code
Creating a complete Deep Deterministic Policy Gradients (DDPG) implementation with a dataset and plots requires multiple components, including an environment, neural networks for the actor and critic, the DDPG algorithm, and the code for collecting and visualizing data. Below, I’ll provide a simplified Python code example using the OpenAI Gym environment and the Matplotlib library for plotting. Please note that this is a basic example, and in practice, you may need to adjust hyperparameters and implement more advanced techniques for better results.
import numpy as np
import tensorflow as tf
import gym
import matplotlib.pyplot as plt
from collections import deque # Import the 'deque' data structure
import random # Import the 'random' module for sampling
# Create the environment (you can use any Gym environment)
env = gym.make('Pendulum-v1')
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
# Actor and Critic networks using TensorFlow
def build_actor_network():
actor = tf.keras.Sequential([
tf.keras.layers.Input(shape=(state_dim,)),
tf.keras.layers.Dense(400, activation='relu'),
tf.keras.layers.Dense(300, activation='relu'),
tf.keras.layers.Dense(action_dim, activation='tanh')
])
return actor
def build_critic_network():
critic = tf.keras.Sequential([
tf.keras.layers.Input(shape=(state_dim + action_dim,)),
tf.keras.layers.Dense(400, activation='relu'),
tf.keras.layers.Dense(300, activation='relu'),
tf.keras.layers.Dense(1)
])
return critic
# DDPG Agent
class DDPGAgent:
def __init__(self, buffer_size=10000, gamma=0.99): # Define and set the gamma parameter
self.gamma = gamma # Store the gamma value
self.actor = build_actor_network()
self.critic = build_critic_network()
self.target_actor = build_actor_network()
self.target_critic = build_critic_network()
# Experience replay buffer
self.buffer = deque(maxlen=buffer_size)
# Define target networks with the same weights as the online networks
self.target_actor.set_weights(self.actor.get_weights())
self.target_critic.set_weights(self.critic.get_weights())
# Define optimizer for actor and critic
self.actor_optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
self.critic_optimizer = tf.keras.optimizers.Adam(learning_rate=0.002)
def add_to_buffer(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample_from_buffer(self, batch_size):
batch = random.sample(self.buffer, batch_size)
states, actions, rewards, next_states, dones = zip(*batch)
return np.array(states), np.array(actions), np.array(rewards), np.array(next_states), np.array(dones)
def actor_loss(self, actor, states, actions):
actor_actions = actor(states)
return -tf.math.reduce_mean(self.target_critic(tf.concat([states, actor_actions], axis=-1)))
def critic_loss(self, critic, target_critic, states, actions, rewards, next_states, dones, gamma):
target_actions = self.target_actor(next_states)
target_Q = target_critic(tf.concat([next_states, target_actions], axis=-1))
target_Q = rewards + (1 - dones) * gamma * target_Q
predicted_Q = critic(tf.concat([states, actions], axis=-1))
return tf.keras.losses.MeanSquaredError()(target_Q, predicted_Q)
def update_target_networks(self, tau):
for target, online in zip([self.target_actor, self.target_critic], [self.actor, self.critic]):
target_weights = target.get_weights()
online_weights = online.get_weights()
new_weights = []
for tw, ow in zip(target_weights, online_weights):
new_weights.append(tw * (1 - tau) + ow * tau)
target.set_weights(new_weights)
def select_action(self, state):
# Convert the state to a NumPy array
state = np.array(state)
# Add batch dimension to the state
state = np.expand_dims(state, axis=0)
# Use the actor network to predict the action
action = self.actor(state)
# Clip the action to the environment's action space range (if needed)
action = np.clip(action, env.action_space.low, env.action_space.high)
return action[0]
def train(self, batch):
states, actions, rewards, next_states, dones = batch
with tf.GradientTape() as tape:
actor_loss = self.actor_loss(self.actor, states, actions)
actor_gradients = tape.gradient(actor_loss, self.actor.trainable_variables)
self.actor_optimizer.apply_gradients(zip(actor_gradients, self.actor.trainable_variables))
with tf.GradientTape() as tape:
critic_loss = self.critic_loss(self.critic, self.target_critic, states, actions, rewards, next_states, dones, self.gamma) # Use self.gamma
critic_gradients = tape.gradient(critic_loss, self.critic.trainable_variables)
self.critic_optimizer.apply_gradients(zip(critic_gradients, self.critic.trainable_variables))
# Update target networks
self.update_target_networks(tau=0.001) # Corrected usage without 'self' as an argument
return actor_loss, critic_loss
# Create the DDPG agent
agent = DDPGAgent()
# Define training parameters
num_episodes = 1000
max_steps = 500
batch_size = 64
# Data for plotting
episode_rewards = []
# Main training loop
for episode in range(num_episodes):
state = env.reset()
episode_reward = 0
for step in range(max_steps):
action = agent.select_action(state)
next_state, reward, done, _ = env.step(action)
agent.add_to_buffer(state, action, reward, next_state, done)
if len(agent.buffer) > batch_size:
batch = agent.sample_from_buffer(batch_size)
agent.train(batch)
state = next_state
episode_reward += reward
if done:
break
episode_rewards.append(episode_reward)
if episode % 10 == 0:
print(f"Episode {episode}, Reward: {episode_reward}")
# Plot the rewards
plt.plot(episode_rewards)
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.title('DDPG Training Performance')
plt.show()Please note that this is a simplified DDPG implementation for educational purposes. In practice, you would need to fine-tune hyperparameters, implement exploration strategies, and add more advanced techniques like target network updates, experience replay, and noise injection for better convergence and performance.
Episode 0, Reward: -1680.8948963876296
Episode 10, Reward: -1679.5995310661028
Episode 20, Reward: -1606.5684823667889
Episode 30, Reward: -1512.7027887078905
Episode 40, Reward: -1676.5041254870414
Episode 50, Reward: -1487.7886571655226
Episode 60, Reward: -1398.5321690200287
Episode 70, Reward: -1551.9420807262784
Episode 80, Reward: -1486.3573806257755
Episode 90, Reward: -1554.8263679376812
Episode 100, Reward: -1626.2031086536663
Episode 110, Reward: -1748.090455073805
Episode 120, Reward: -1748.9325973864356
Episode 130, Reward: -1815.397089952616
Episode 140, Reward: -1851.6618096208608
Episode 150, Reward: -1640.4318136353127
Episode 160, Reward: -1770.584144941453
Episode 170, Reward: -1833.3219935587158
Episode 180, Reward: -1623.6034643226374
Episode 190, Reward: -1665.2530466311787
Episode 200, Reward: -1408.9315897707427
Episode 210, Reward: -1402.3905855302553
Episode 220, Reward: -1492.498696778396
Episode 230, Reward: -1575.0888791882496
Episode 240, Reward: -1318.1519733134166
Episode 250, Reward: -1690.9066406844872
Episode 260, Reward: -1514.6773317792013
Episode 270, Reward: -1402.8461496077618
Episode 280, Reward: -1465.1098395045676
Episode 290, Reward: -1260.8688433687248
Episode 300, Reward: -1796.0143575950494
Episode 310, Reward: -1531.2343184101258
Episode 320, Reward: -1844.936063494665
Episode 330, Reward: -1874.1536186912906
Episode 340, Reward: -1768.260784763511
Episode 350, Reward: -1812.1616207847326
Episode 360, Reward: -1473.1086455036793
Episode 370, Reward: -1475.9218817489402
Episode 380, Reward: -1684.7238211820204
Episode 390, Reward: -1560.571142399997
Episode 400, Reward: -1653.463864644562
Episode 410, Reward: -1739.1047749465001
Episode 420, Reward: -1538.6847651826101
Episode 430, Reward: -1797.7695370907268
Episode 440, Reward: -1753.385184699908
Episode 450, Reward: -1411.2439738408768
Episode 460, Reward: -1529.6975201567782
Episode 470, Reward: -1529.3672711616964
Episode 480, Reward: -1270.6924999352966
Episode 490, Reward: -1811.122971166864
Episode 500, Reward: -1352.2794767410176
Episode 510, Reward: -1074.376306592394
Episode 520, Reward: -1799.215113417089
Episode 530, Reward: -1114.8987398325082
Episode 540, Reward: -1674.867892414308
Episode 550, Reward: -1417.7894890126722
Episode 560, Reward: -1040.5575650055653
Episode 570, Reward: -1031.9366290130758
Episode 580, Reward: -1009.1584381585435
Episode 590, Reward: -1068.7452936074503
Episode 600, Reward: -1132.6695536883617
Episode 610, Reward: -1649.3662247818313
Episode 620, Reward: -1419.6648128394509
Episode 630, Reward: -1866.03017186529
Episode 640, Reward: -972.867763976454
Episode 650, Reward: -1379.1625350345296
Episode 660, Reward: -1431.522727369365
Episode 670, Reward: -1752.5052691979815
Episode 680, Reward: -1571.8786387127752
Episode 690, Reward: -1169.199621666014
Episode 700, Reward: -1415.4519449991785
Episode 710, Reward: -1822.466464204076
Episode 720, Reward: -1318.4644312000457
Episode 730, Reward: -1414.7454637691387
Episode 740, Reward: -1846.2784374568773
Episode 750, Reward: -1390.9115099028634
Episode 760, Reward: -1498.9023940292273
Episode 770, Reward: -1598.1958680718178
Episode 780, Reward: -1312.1821681827178
Episode 790, Reward: -1373.6441153027827
Episode 800, Reward: -1483.8361337740548
Episode 810, Reward: -1489.298107055303
Episode 820, Reward: -1759.191355938306
Episode 830, Reward: -1202.6665991836596
Episode 840, Reward: -1391.037023586251
Episode 850, Reward: -1217.818059883296
Episode 860, Reward: -1296.4888469664088
Episode 870, Reward: -1332.3981382154534
Episode 880, Reward: -1176.7749026769732
Episode 890, Reward: -1282.8680852206767
Episode 900, Reward: -1342.5245204993857
Episode 910, Reward: -1643.2737877348507
Episode 920, Reward: -1278.685316991944
Episode 930, Reward: -1043.1786265699413
Episode 940, Reward: -1305.3037606182481
Episode 950, Reward: -1202.8848555969596
Episode 960, Reward: -1607.5294672752339
Episode 970, Reward: -1793.96667258336
Episode 980, Reward: -951.5458544987462
Episode 990, Reward: -1035.3949288302485
In this particular log, it seems that an agent or system goes through episodes and receives rewards. The rewards appear to fluctuate over time, indicating that the agent’s performance varies during the training or testing process. Here are some insights that can be derived from this data:
- Reward Progression: The rewards in the log show a variation over time, with both positive and negative values. The trend is not consistently improving or deteriorating, suggesting that the agent’s performance might be sensitive to different factors.
- Exploration vs. Exploitation: In reinforcement learning, agents often face a trade-off between exploration (trying new strategies) and exploitation (using the best-known strategy). The variations in rewards could indicate that the agent is still exploring different approaches to the task.
- Learning Dynamics: The fluctuations in rewards suggest that the learning process may not be stable. The agent may be encountering challenges or changes in the environment, leading to variations in performance.
- Training Progress: The trend of rewards might indicate whether the agent is converging to an optimal policy or still struggling to find the best approach. A consistent improvement in rewards over time would be a positive sign of learning.
- Challenges and Opportunities: Sudden drops or spikes in rewards may point to specific challenges or opportunities that the agent encounters. Analyzing these moments can provide insights into what’s working and what’s not.
- Hyperparameter Tuning: To improve the agent’s performance, hyperparameter tuning and algorithm adjustments may be necessary. The rewards log can help in identifying the effectiveness of these changes.
It’s important to note that further analysis and context are needed to draw definitive conclusions and make informed decisions about the agent’s performance and training process. Depending on the specific problem and application, different metrics and evaluation methods might be required to assess the success of the agent’s learning.
Challenges and Future Directions
While DDPG offers substantial benefits, it is not without its challenges. The hyperparameters of DDPG can be sensitive, and fine-tuning is often required to achieve optimal performance. Additionally, its sample efficiency can be further improved. The future of DDPG and continuous action RL algorithms lies in addressing these challenges, exploring new techniques for enhancing exploration, and extending its capabilities to even more complex environments.
Conclusion
In conclusion, Deep Deterministic Policy Gradients (DDPG) stands as a remarkable advancement in the realm of reinforcement learning. By bridging the gap between RL and continuous action spaces, DDPG has opened up new possibilities for applications in robotics, autonomous control, finance, and gaming. Its characteristics of handling continuous actions, sample efficiency, and stability in training make it a valuable tool for researchers and practitioners. As the field of RL continues to evolve, DDPG will likely play a central role in shaping the future of intelligent agents in the real world.





