
Decoupling a core service from your monolith the right way
Our monolith problem
WeTransfer, like many other products, started as a small monolithic application and quickly became a big monolithic with too many responsibilities and contributors. It was getting harder to ship new features, and the technical debt was growing. That’s why we started decoupling some core logic into different services. One of those modules was the billing logic.
The billing module in charge of users’ payments and subscriptions is one of the core services of our business. A lot changed since our first implementation, and since everything lived in the same monolithic, the billing codebase was coupled with other core modules like transfers and authorization.
This post will describe our different steps to decouple all the billing logic without significantly impacting the 80M+ active users using our products. There are many different ways to approach this project, but hopefully, our learnings will help you plan yours.
Phase 1: Decouple billing logic within the monolith
Our billing logic was very coupled to the rest of our monolith, and it took a lot of effort to understand the interface between other modules and the billing codebase. So our first approach was to decouple the billing logic within the monolith. We did that in two parts:
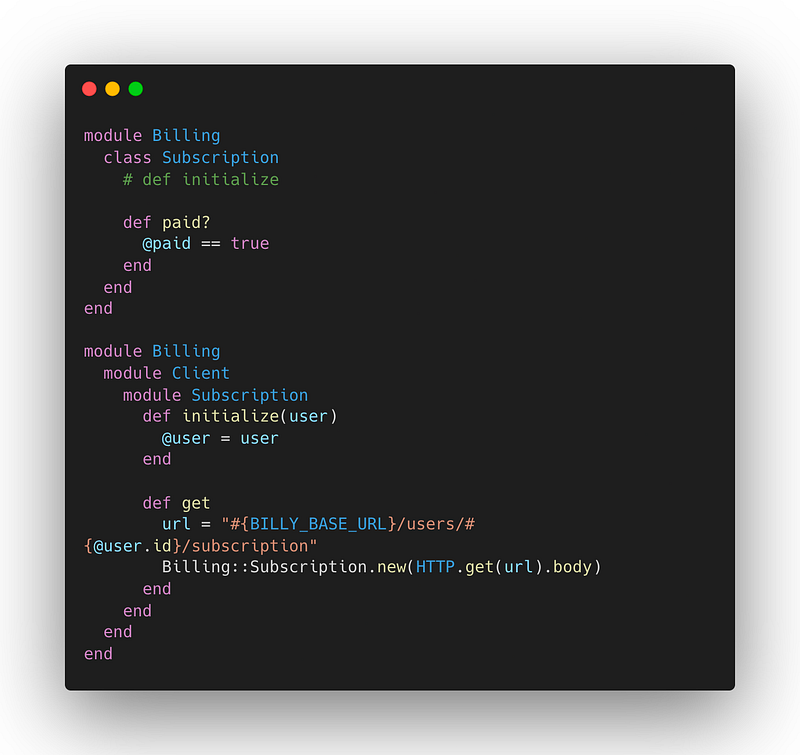
- We moved all our billing classes into new folders and modules. So most of our billing classes were prefixed with
Billing::(since the codebase is in Ruby). Then we set our team as the GitHub code owner of those folders so we would be notified of any contributions made. We also took this opportunity to communicate with the rest of the engineering team about our plans and that any new logic using billing modules should be carefully reviewed. For example, we didn’t want to add more dependencies between the existing modules and the billing logic. - We created different
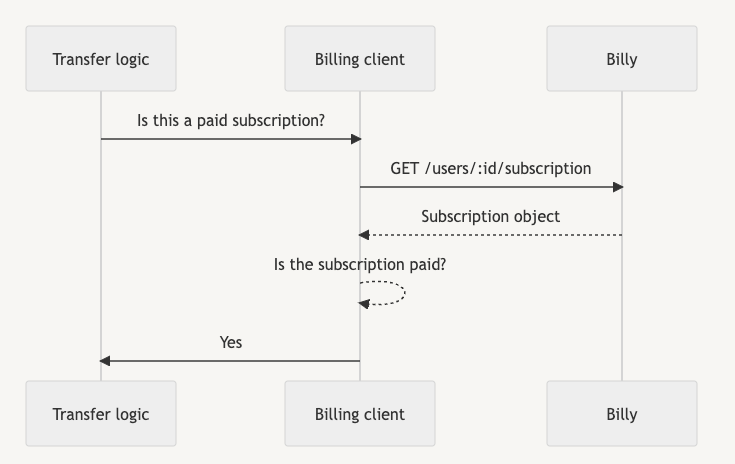
Clientclasses as middleware interfaces between the billing code we wanted to migrate and the rest of the monolith. The idea was that every interaction with the billing logic would need to go through one of these Clients. For example:
Before the decoupling:
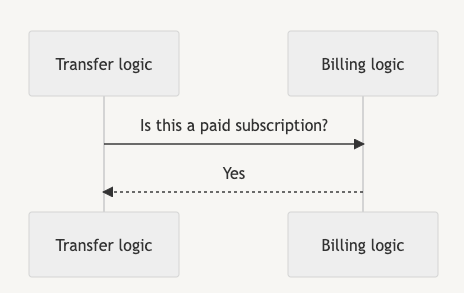
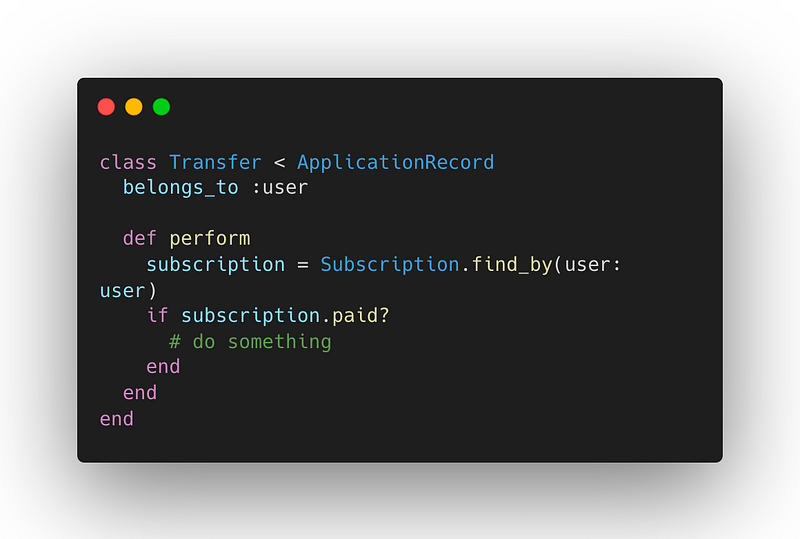
After the decoupling:
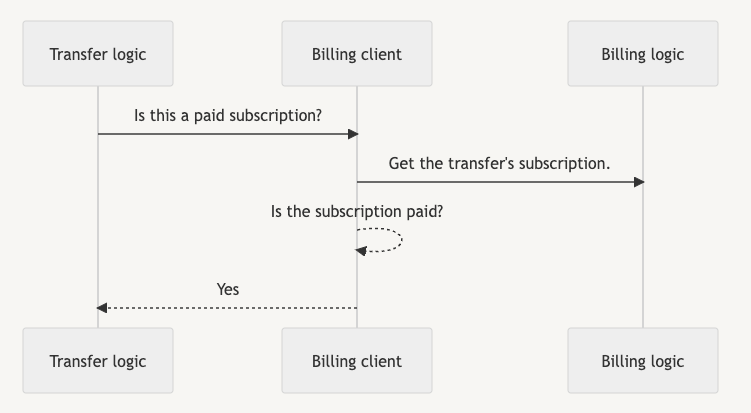
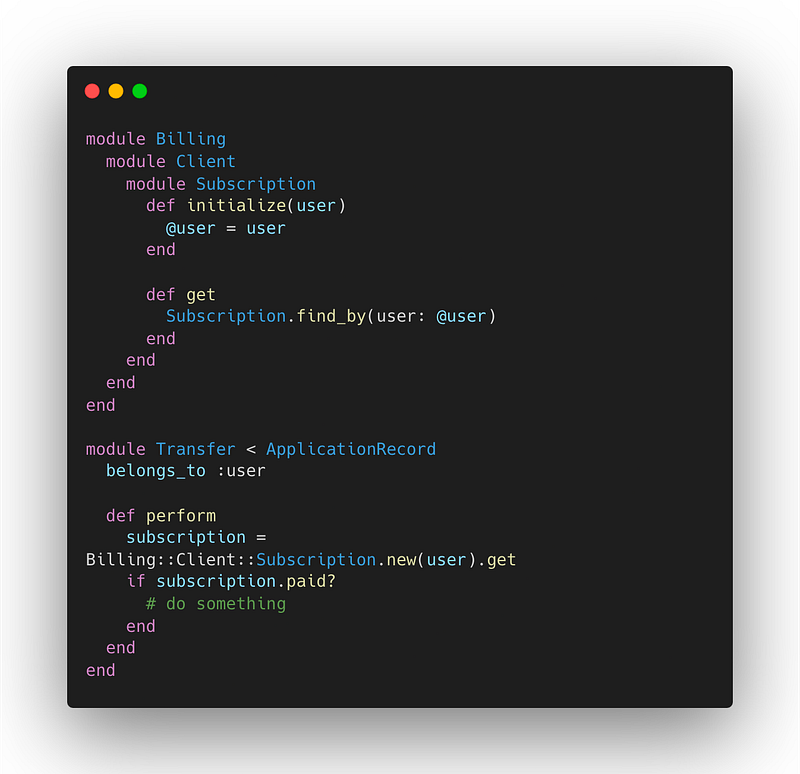
We wrote the billing client with the same format as a REST API interface since that would become, in a future phase, the interface with the new billing service. Working on this new client helped us understand every interaction needed with the new billing service. We could also start thinking about more complex things we needed to decouple. That gave us a clear plan of things we had to discuss with other teams and allowed us to start working on the API spec we expected every team to use in the future.
At the start of the project, it took a lot of work to understand the complete scope since the codebase had many modules we needed to familiarize ourselves with. After this phase, the scope was better defined, most of the code was already decoupled within the monolithic, and the challenges ahead were clear. We were ready to start working on the new billing service.
Phase 2: Onboard the new billing service: Billy
The billing logic included more than four years of development, so rewriting everything was not part of the scope. To avoid that, we included the monolith code into the new Billy repository using git submodules. Our new codebase had a folder with all the monolith files. That allowed us to focus on writing the controllers first while being able to call already existing classes.
We also decided to reuse the same database as the monolithic. We knew that once we started working on this project, we needed to clean the code in the monolithic as soon as possible; if not, it could delay other projects that depended on it. So our focus was to have an API ready first, and then we would focus on the actual code and database in Billy.
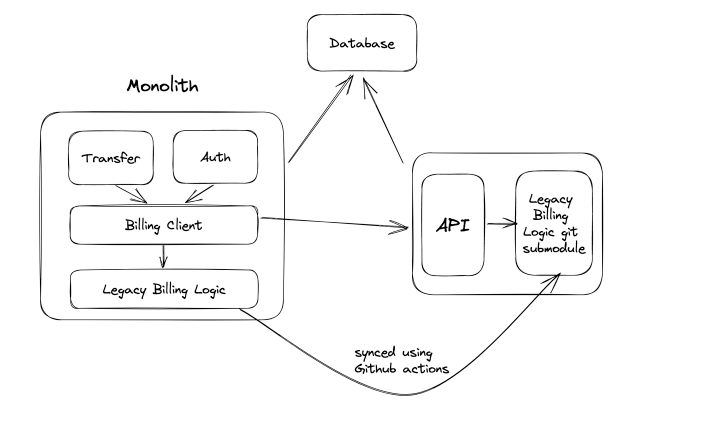
Once the setup was ready, we started refactoring the billing client in the monolith to make HTTP calls to Billy:
Feature Flags and monitoring
Once some endpoints were finalized, it was time to start releasing them to production. Since those endpoints were critical to the rest of the products, it was essential to avoid downtime and to have a rollback strategy in case anything went wrong. For that, we relied on feature flags allowing us to do percentage rollouts to some users and roll back if anything was not working as expected.
We needed a good monitoring setup to understand if things were working as expected. We use Datadog for all our services, allowing us to monitor infrastructure metrics and follow traces across our products. We could easily track the incoming throughput to Billy and how it was working out for other services.
- Was the latency acceptable?
- Is our circuit breaker working as expected?
- Is the monolith handling error responses correctly?
Phase 3: Cleanup
Once the endpoints were implemented and in production, we could remove the git submodule and move files from the monolith to Billy. For some files, it was just a copy-paste; for others, it was an excellent opportunity to work on improvements. Some improvements were impossible to tackle immediately, so we created a Jira Epic with different things we wanted to work on once the decoupling project was done. That already showed the advantage of having the billing logic outside the monolithic. Suddenly some ideas that sounded very hard to implement became something we could quickly implement in the new code base.
By the end of this phase, there would be no more billing files in the monolith, and they would all live in Billy now, with new names, interfaces, test suites and documentation.
Phase 4: Database split
Billy was a separate service, but we still used the monolithic database, which worked well as a first approach. However, we depended on their migration process; any incident or downtime could still affect us.
We migrated using AWS Database Migration Service, which allowed us to sync the tables from the monolith to Billy’s new DB, meaning we would have the same data in both databases. All we had to do was to switch our service to point to the new database. Before the switch, we stopped any cronjob or background job and disabled the writes to ensure we didn’t miss any data. We planned that during low throughput times of the day, and since reads were still possible, the impact was minimal, recovering successfully after the switch.
Learnings
- Rely on regression tests if you have any. Since no feature should be affected during the decoupling, any regression tests across your product should pass.
- Do regular check-ins with your team and track your challenges as small initiatives with clear action points and scope.
- You will find many improvements and refactors along the way. Make sure you track those for later. This is a big win from the decoupling, so use it. You’ll be tempted to work on those fixes during the refactor, which might be okay for small things, but be careful with scope creep, which could cause distraction and delays.
- If a rollback were needed, some features would have to be implemented in both the monolith and Billy. This was time-consuming, so moving fast to remove that code from the monolith and rely 100% on Billy was essential.
- Tests take a lot of work to maintain during a rewrite. Don’t underestimate the time it could take; have a clear strategy to keep that simple to avoid fixing tests you will have to rewrite.
- If you have another less critical client using your API, integrate and test that first. We did this with an admin tool that is used internally only.
Things we could have done differently
- We underestimated the effort needed from other teams, and we started some conversations too late. For example, the Data team was required to modify their pipelines before we could switch to a new database. We tackled that at the end of the project, causing a few blockers during the final stage.
- We shipped some refactors fast without taking the time to prepare the metrics needed to evaluate if everything was still working correctly. We could have set up metrics beforehand to allow us to find any anomalies after the release.
- At the beginning of the project, we could have defined smaller milestones in case the project was put on hold. This was easier to do later in the project when the scope was clearer and things easier to estimate.
Conclusion
A big decoupling project needs a lot of planning, time and investment, and the benefits aren’t always evident to the business. Also, many things could go wrong if the codebase is too big and your team is unfamiliar with all the moving parts. You will find a lot of blockers in the way, and you need to make sure you find an excellent workaround to make it a success; otherwise, months of work could become on hold forever.
In our case, the project took longer than initially planned, but it was a success. These are the key benefits we could measure:
- 32918+ lines of code were removed from the monolith and refactored in Billy. This meant it was a lot easier to introduce new features in the monolith, things were less coupled, and it was easier to understand how to interact with the billing logic.
- Productivity for our team: CI/CD was four times faster for us now. It was also much easier to release and roll back new features since our new service had fewer contributors. It was also an excellent opportunity to improve our dev experience. We could implement improvements we had in our backlog for three years.
- Availability: Incidents in the monolithic didn’t affect our billing anymore. We could also recover much easier from any incident caused by a new release and implement SLOs specific to Billy.
Of course, some things like latency could be a lot better when you run everything on the same service, but in this case, a decoupled service proved to be a great approach, and it was critical to its success the approach we took to make it happen. I hope some of our learnings help you if you find yourself in the same situation!





