
Deconstructing BERT
Reveals clues to its state-of-art performance in NLP tasks
Transformer architecture models, particularly BERT, has demonstrated to be quite effective in many NLP tasks by just fine tuning a model that was pretrained in an unsupervised manner on a large corpus. BERT model takes as input a sequence of words and produces a series of word embeddings across layers. These word embeddings take into account the context in which a word occurs.
Two recently (April 2019 and 6 June 2019) published papers (1 and its blog, 2 and its blog) offer some geometric insights into to why BERT may be performing so well.
Some of the key findings from these papers
- BERT’s word vector output encodes rich linguistic structure. BERT approximately encodes syntax trees in the word embeddings it outputs for a sentence. It is possible to recover these trees by a linear transformation of the word embeddings. (1 and its blog)
- BERT appears to encode syntactic and semantic features in word vectors in complementary subspaces (2 and its blog).
- Different senses of a word have representations (determined by the sentence context) that are spatially separated in a fine-grained manner (2 and its blog)
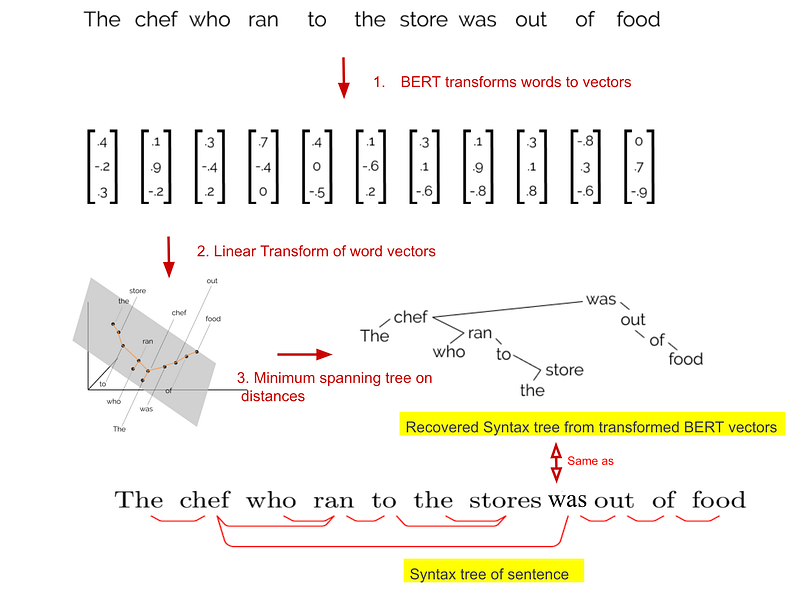
Recovering parse trees from BERT word vectors for a sentence
Language is made of discrete structures — sequence of symbols(words) with the syntactic structure of sentences captured in a tree. Neural net models, in contrast operate on continuous data — they translate symbolic information into vectors in high dimensional space. These vectors (word embeddings) have been known to capture semantic similarity in their lengths/orientation (e.g. word2vec, fasttext etc.) .
As mentioned above, recent discovery shows BERT word vector output encodes rich linguistic structure. Encoded in the vector output for a sentence is geometrically approximate copies of syntax trees. Words in a sentence are given locations in a high-dimensional space and if we subject these word vectors to a specific transformation, the Euclidean distance between these locations maps to syntax tree distance. In essence we can recover syntax tree (and the dependency tree too with directional edges) for a sentence by transforming the word vectors using a specific linear transformation and then finding a minimum spanning tree on the distances between the word vectors.
The mapping between the tree distance in the syntax tree (tree distance between two nodes is the number of edges in the path between them) and Euclidean distance (between nodes in the minimum spanning tree derived from word embeddings) is not linear. The syntax tree distance between two words corresponds to the square of the Euclidean distance between the corresponding nodes in the extracted minimum spanning tree. The second paper offers a reason as to why it is the square of the Euclidean distance as opposed to just the Euclidean distance (the remaining portion of this section is not core to understanding BERT model — can be skipped).
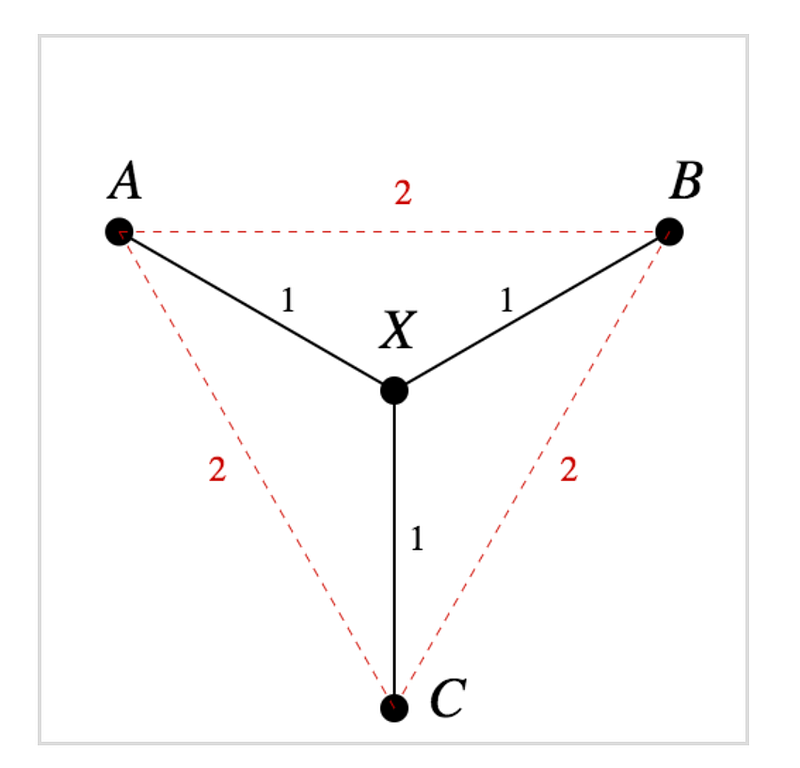
It is not possible to isometrically (mapping preserving distances ) map a tree to Euclidean space, because of tree branches.
For example, The tree distance between nodes A and B on the left is 2 — d(A,X) + d(X,B)
Since d(A,B) = d(A,X) + d(X,B), in an isometric mapping to Euclidean space, A, X, and B have to be collinear ( X has to be on the line connecting A and B in order for the above condition to hold)
Applying the same argument to point A, X, and C, d(A,C) = d(A,X) + d(X,C), A, X, and C have to be collinear too. But this implies B = C, which is a contradiction.
However there is an isometric mapping from tree to squared distance (Pythagorean embeddings) as illustrated below
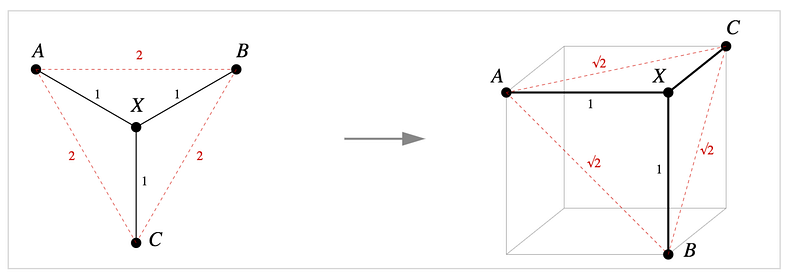
The blog article has more examples. In general they illustrate
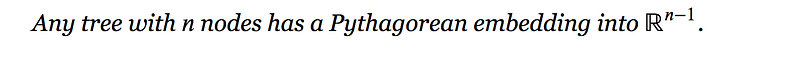
Also,
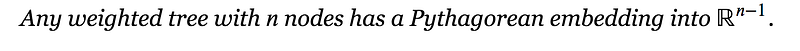
The blog has additional interesting results. For instance, randomly branched trees, if mapped to a sufficiently high dimensional space, where each child is offset from its parent by a random unit Gaussian vector, will be approximately a Pythagorean embedding. A practical implication of this is that context embeddings approximate Pythagorean embeddings of a sentence’s dependency parse tree. From the squared distance property, we have an overall shape of the embedded tree recovered from the vectors.
The shape of the recovered tree ( influenced by the edge lengths between nodes) is only approximately similar to ideal tree — the discrepancy has some patterns. The average embedding distance between dependency relations vary widely. It is not known what these differences mean. Perhaps BERTs representations, have additional information beyond just dependency parse trees.
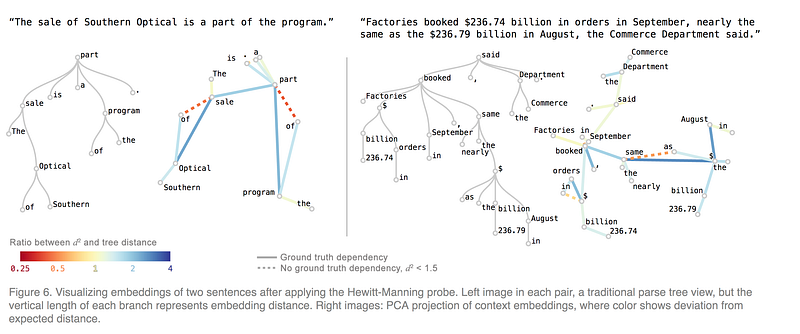
As an aside it would be interesting to see kind of anomalous edges that are close (part/of same/as in figure above) if we do the same exercise on gene/protein sequences to examine if there is information contained in them — not necessarily corroborating actual 3-D geometric configurations.
Syntax tree is also captured in attention matrix for a sentence
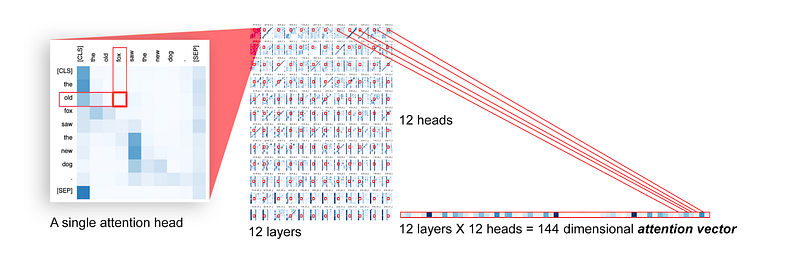
The second paper also shows attention matrix for a sentence captures syntax tree. Consider the sentence “the old fox saw the new dog”. Consider the word pair “old, fox”. We can construct a vector by picking up the scalar value for this pair from each attention head from across all layers (12 layers for BERT base with 12 attention heads in each layer) If we train linear classifiers that take as input such model-wide attention vector for each word pair, and classify if there is a relation between the two words, and the type of relationship, these classifiers perform reasonably well (even if not state of art results) suggesting that syntactic information is encoded in attention matrix for a sentence.
BERT appears to encode semantic features in its embeddings
By simply visualizing the embedding for words like die in different sentence contexts, we can see how word sense affects embeddings.

In general, the word embeddings show
- different senses of a word are separated (three clusters above for the word “die”). Word sense disambiguation is accomplished by this separation
- Within cluster there seem so be separation of finer shades of meaning (see embeddings below for the word “lie”
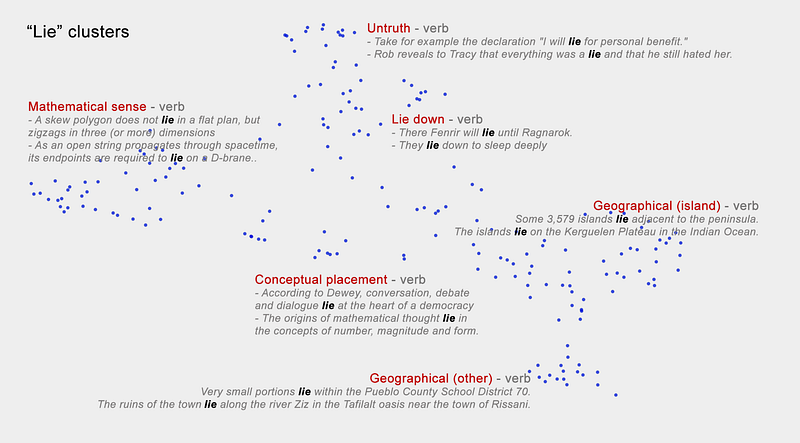
- Analogous to position representing syntax we saw earlier, here position of embeddings represent semantics
The second paper claims word senses are captured in a lower dimensional space, though it is not clear how that is. Given this observation, it appears a vector encodes both syntactic and semantic information in complementary subspaces
Experiments with published code
The Github repository for the first paper has code to recover syntax trees from sentences as described above
For example, for the input sentence
The duckling that fell through a drain was rescued
The recovered parse tree from the word embeddings for the sentence above as well as a dependency parser output for the same sentence is shown below

Conclusion
Deconstruction of models along the lines above in future
- could potentially reveal more linguistic structure (like the parse tree) or equivalently more subspaces
- Understanding the geometry of internal representations could potentially find areas to improve model architecture