
How I Used Large Language Models (LLM) to Automate personal Slack Bot for QnA
As part of LLM CoE team, over last few months I was heavily invested in enabling LLM vendors, models, applications and solution blueprints. It is a learning opportunity every day to bring a comprehensive eco-system of technology, designs, assessments, evaluations, integrations and solution offerings to help our customers adapt to the new Gen-AI and LLM based solutions.
My objective for this blog was to implement a practical solution to my own opportunities (and challenges) and thereby document a practical LLM use case that is currently in “production” ( I spend quite a bit of time in my slack channel).
The Problem Statement
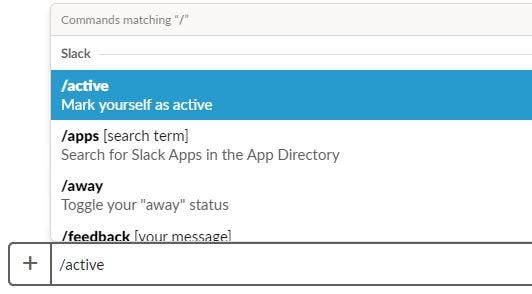
I use my personal slack channel. I use it to connect to close friends and people I know to share questions, check trends and discussion technical questions across data lakes, data mesh’s, lake-houses, machine learning projects, cloud platforms etc etc. I have close to 50 friends and close associates that I interact with through my slack. Many a times, I am on the receiving end where I end up documenting and answering questions based on the work I did or the issues I faced. My intention for this scenario was to stand up a slack “custom slash command” where anyone can and a question to the common slack channel and use the slack command to get automated answers (from slack bot) based on similar questions asked in history. So, if one of my friends asked a question that I answered last month (as example) — then the slack bot will generate the answer based on the last discussion thread.
The datasets I used for this setup was from below :
- Blogs I have written in Medium
- Youtube content (transcription) from my channels (on topics I discussed in detailed)
- White-papers I co-wrote and published
- Some if the public information that I saved in my google drive
- Past information/ questions I answered previously (this was tedious as I has to manually created a FAQ document from my own conversations)
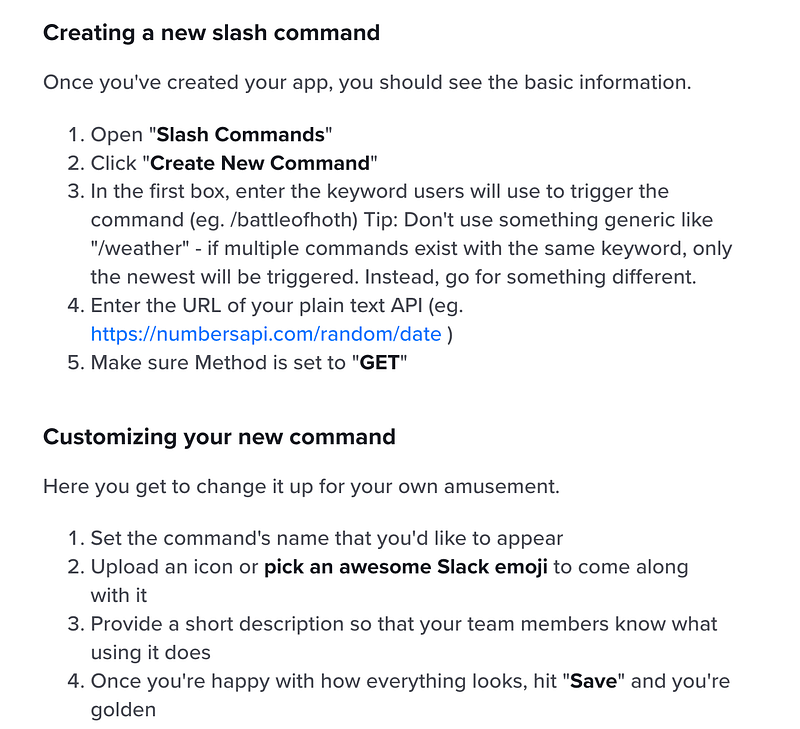
** Slack Slash command is a special command we can type in slack using a “/” that internally call a API layer to fetch results programatically.
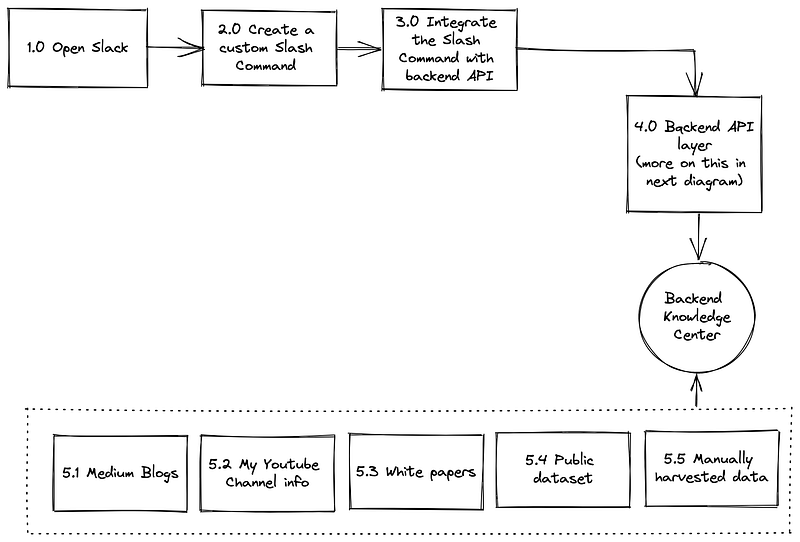
The Solution Overview
The magic happens at the backend. The solution is based on 2 parts
- Part 1 — offline loading data from the multiple data sets (depicted in the above) into knowledge center (called vector database, more on this ahead)
- Part 2- Online search and retrieve. This is where we so a similarity search of the question and context and search the vector database to collate a series of similar data and eventually use LLM models to summarize.
For the first part, I build dedicated python based micro-services that can connect to a source (like google drive, youtube sdk, scan medium blogs etc.) and read data. Once the data was read, I chunked the data into smaller pieces (used a default chunk size of 1000) and then for each chunk sent the chunk to a LLM model called embeddings models to convert the chunk into a vector space (think of a vector space in this example as an 1536 dimentional address space for each chunk). Once the embeddings were done for each chunk within each document from each source, I pushed the data (text and vector space) into a vector database (now you get it :-), a vector database is a database that can store and search an embeddings vector). Finally, after phase 1, my vector database has a collection of datasets and their vector representation. (whew)
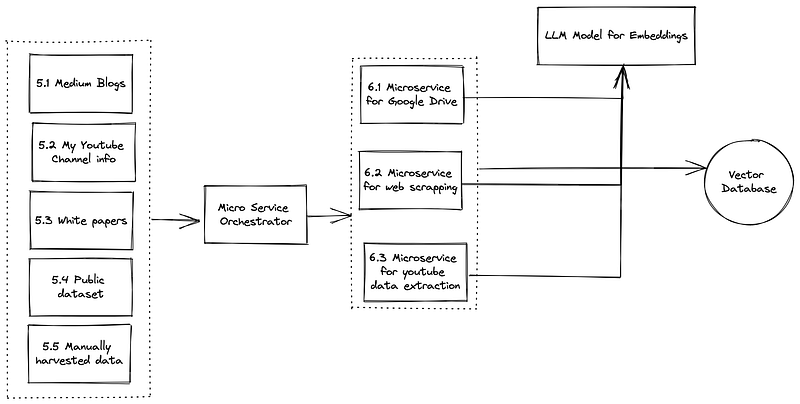
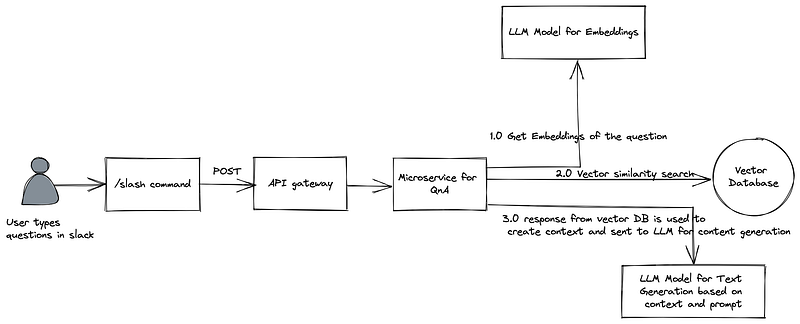
For the part 2, I added one more microservice that received the slash command as POST request. The question asked in the slack channel is delivered as payload to the microservice (through API gateway). The microservice then calls the embeddings LLM to get a vector representation of the new question. Once the vectorized question is available, the microservice then calls the vector database to do a similarity search and get top 3 answers (I use 3 in this case) from the database (one of the other reason to use vector database is to so a similarity search). Once the top 3 results are returned, I combine the answers to create a context and call my final generative LLM to answer the question based on the context (through prompt engineering). The resulting answer is then send back to the slash command (slack) screen.
Conclusion
This was a personal experience, through this example I was able to touch multiple facets of LLM based application development. Stay tuned as there are more to come.

In Plain English
Thank you for being a part of our community! Before you go:
- Be sure to clap and follow the writer! 👏
- You can find even more content at PlainEnglish.io 🚀
- Sign up for our free weekly newsletter. 🗞️
- Follow us on Twitter(X), LinkedIn, YouTube, and Discord.




