
Day 13 — Spark Shuffling Behind the scenes
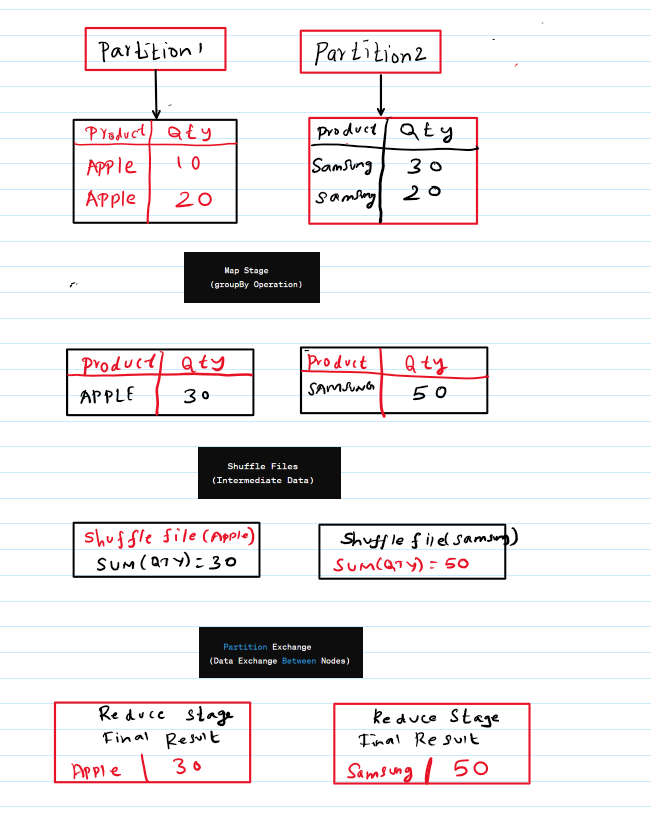
Here is the sample code how shuffling is working behind the scenes,
from pyspark.sql import SparkSession# Initialize SparkSession
spark = SparkSession.builder \
.appName("Product") \
.getOrCreate()# Create a sample DataFrame
data = [("Apple", 10), ("Samsung", 30), ("Apple", 20), ("Samsung", 20)]
df = spark.createDataFrame(data, ["Product", "Qty"])# Perform a groupBy operation, triggering shuffling
grouped_df = df.groupBy("Product").sum("Qty")# Show the result
grouped_df.show()# Stop SparkSession
spark.stop()Shuffling in PySpark (and Spark in general) is a critical operation that involves redistributing data across the cluster to perform certain transformations or actions. Shuffling typically occurs when there’s a need to exchange data between partitions or when operations such as groupByKey, join, or sortByKey are performed. Here's an overview of the backend design for shuffling in PySpark:
Partitioning:
- Data in a PySpark RDD or DataFrame is divided into partitions, which are distributed across the nodes in the Spark cluster.
- Partitioning is the process of determining which records go to which partition based on a partitioning function or key.
Map Stage:
- During a shuffle operation, each executor reads the data from its local partitions and performs any required transformations.
- It then writes the output to temporary disk storage known as spill files.
Shuffle Map Task:
- Each partition is processed by a shuffle map task, which is responsible for writing records to shuffle files.
- Shuffle map tasks run concurrently on each executor and generate output for different partitions.
Shuffle Files:
- Shuffle files are intermediate files that contain the shuffled data.
- Each shuffle file corresponds to a particular partition and is created for each unique key.
Partition Exchange:
- Once all shuffle map tasks have completed, the shuffle files are exchanged between executors.
- Spark uses a mechanism known as “shuffle block managers” to manage the exchange of shuffle files between nodes.
Reduce Stage:
- After the shuffle files have been exchanged, reduce tasks are launched to read and process the shuffled data.
- Each reduce task is responsible for processing a specific partition of the shuffled data and performing any required aggregations or transformations.
Final Output:
- The output of the reduce tasks is combined to produce the final result of the shuffle operation.
- The final result may be stored in memory, written to disk, or returned to the driver program, depending on the nature of the operation.
Disk Spill:
- In case the data to be shuffled exceeds the available memory, Spark spills intermediate data to disk.
- Disk spillage can occur during both the map and reduce stages of shuffling.




