
Data storage structures: B+ tree, B-Link tree, and LSM tree

B+ Tree

A B+ Tree is a type of balanced tree data structure. It is an improvement of the B-Tree and is commonly used in databases and file systems. B+ Trees are optimized for disk access. They store data in sorted order and are designed to allow efficient insertion, deletion, and retrieval of data from disk. B+ Trees are also characterized by their high degree of branching, meaning that there are fewer disk accesses required for operations on a B+ Tree than on a B-Tree. The basic structure of a B+ Tree consists of a root node and a set of leaf nodes. The leaf nodes store the actual data, while the root node stores the pointers to the leaf nodes. Each node contains a number of keys, which are used to identify the data stored in the node. B+ Trees are self-balancing, meaning that they can be easily re-organized when data is inserted or deleted. This allows the tree to remain balanced and efficient even when data is added or deleted. B+ Trees also have a large fan-out, meaning that they can store more data in each node than a B-Tree. This makes them very efficient for large datasets.
B-Link tree
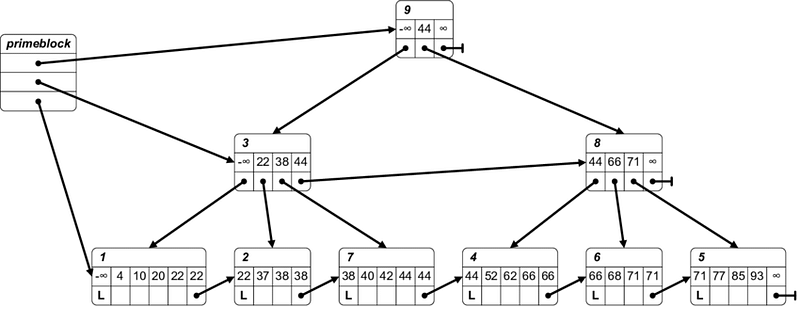
B-Trees are a type of self-balancing tree data structure that keeps data sorted and allows searches, sequential access, insertions, and deletions in logarithmic time. It is a generalization of the binary search tree, in which a node can have more than two children. B-Trees are well-suited for storage systems that read and write relatively large blocks of data, such as discs. They are commonly used in databases and filesystems.
B-Trees are used for two main purposes:
- To store data in sorted order.
- To provide fast access to the data.
A B-Tree is organized into a series of nodes that contain a certain number of keys and associated values. All nodes at the same level must contain the same number of keys. A node is divided into two parts: the left part contains the keys and the right part contains pointers to the children. The root node is the highest node in the tree and contains the smallest key. The key to a B-T ree’s efficiency is its self-balancing feature. When a node is full, it splits into two nodes, and the keys are redistributed among them. If a node is empty, it is merged with an adjacent node. This keeps the tree balanced, ensuring that the tree remains efficient. B-Trees also have the advantage of being able to store data in large blocks, allowing for efficient access to large amounts of data. This makes them ideal for storing data in files and databases.
LSM-TREES
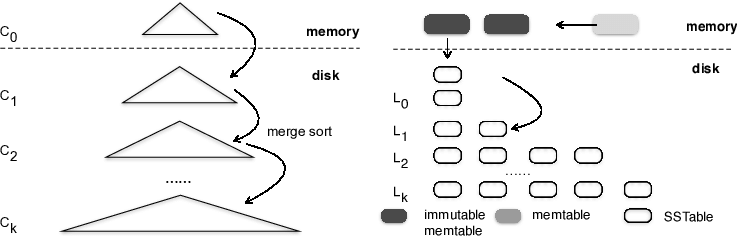
LSM-Trees (Log-Structured Merge-Trees) are a type of data structure used for storing and retrieving data from disk. They are an alternative to traditional B-trees, providing better write performance and improved scalability. LSM trees are used in databases, file systems, and other data storage systems. The basic idea behind LSM-Trees is to store data in a log-structured format on disk. This structure allows for efficient reads and writes, and makes it easier to scale the system as more data is added. Data is stored in a series of “tiers”, with each tier representing a larger amount of data. Each tier is composed of a number of “sorted runs”, which are sorted collections of data that are merged together to form a larger data structure. When a write operation occurs, the data is added to the lowest tier and is eventually merged up to the higher tiers. Read operations can be performed by traversing the tiers from the lowest to the highest.
B Tree And B+ Tree Data Structure
B Tree and B+ Tree are both tree data structures that are used to store data in sorted order. Both are disk-based data structures, meaning that they are designed to store data on a disk drive for efficient access. The main difference between B Tree and B+ Tree is their structure.
A B Tree is a multiway tree with a variable number of branches at each node. It is a self-balancing tree that uses a fan-out technique to store data. This means that each node has a number of pointers to other nodes that are related to that node. This allows the tree to maintain a balanced structure, while still allowing for efficient searches.
A B+ Tree is a variant of a B Tree that uses a leaf-oriented storage structure. In a B+ Tree, all the data is stored in the leaf nodes, while the internal nodes contain only pointers to other nodes. This makes searches more efficient, as it reduces the number of nodes that need to be traversed to get to the data. Additionally, B+ Trees are more space efficient than B Trees, since they don’t require extra storage for internal nodes.
B-Tree vs LSM-Tree
B-Trees and LSM-Trees are both types of indexing structures used to store data.
A B-Tree is a type of tree-based indexing structure that stores data in a hierarchical structure. B-Trees are designed to store large amounts of data in an efficient manner and are well-suited for applications that require fast reading and writing of data. B-Trees are also known for their good caching performance and low memory usage.
LSM trees are a type of tree-based indexing structure that stores data in a log-structured way. LSM-Trees are designed to provide fast data access and are well-suited for applications that require fast read and write access. LSM-Trees also have good caching performance and low memory usage.
The main difference between B-Trees and LSM-Trees is that B-Trees are optimized for random reads and writes, while LSM-Trees are optimized for sequential reads and writes. B-Trees are also typically used in databases and other applications that require fast random access, while LSM-Trees are used in applications that require fast sequential access.




