
Data sovereignty: sharing is not caring
Researchers are urging more data transparency, is it right to grant always data access?

artificial intelligence promises to bring about a revolution in the medical field (both in pharmaceutical and medical research and in the research itself). Artificial intelligence requires data to be trained.
Patient data are sensitive. In the past, not all data have often been obtained with proper consent, and have often ignored communities and minorities. Communities and minorities are underrepresented in databases, but medicine in the past has been permeated with systemic racism leading communities to distrust research.
The genomic broken promise

Scientific research does not like to share data. Researchers see their datasets as a resource so they can publish papers, and sharing is seen as the loss of competitive advantage.
Today there are fewer and fewer faculty positions and reduced research funding. Succeeding in obtaining a position at a university is a Darwinian challenge, so much so that informally the motto “publish and perish” meanders.
The Human Genome Project (HGP) has partly changed this view. The data were immediately made available to the community and inspired what is called the Bermuda Principles (where genomic sequences obtained by the consortium were to be published as soon as possible). This led to the possibility of having millions of sequences available today.
“there had not been a serious discussion about data sharing in biomedical research. The standard was that a successful investigator held onto their own data as long as they could.” — David Haussler who worked in the HGP project (source)
The result in reality is far from idyllic. Everyone uses different practices and principles in organizing and sharing data, making meta-studies more difficult (and talking about a kind of “tower of Babel,” where researchers who want to use data from other groups lose so much time in having to explore and preprocess the dataset).
Also, there is not always transparent about how these data were obtained. Guidelines change from country to country, and metadata is often not available. Not all data are then available; there are often still researchers who are reluctant to submit and publish datasets. This is why the community continues to call for an open data share policy, to push journals and institutions to be more restrictive and require mandatory data sharing for publications and funding.
For more on the topic:
Everything sequences tell and hide
Researchers are pushing for an increasingly transparent policy for both data and articles, but not everyone agrees.
Databases have made it possible to succeed in conducting countless studies. GWAS studies have made it possible to shed light on the cause of countless diseases (genetic and otherwise), and today in forensic medicine the databases have been essential in uncovering the culprits of numerous cold cases.
The data have not always been acquired clearly and with real consent. A famous example is the Henriette Lacks cell case. In 1951, a sample of cervical cancer was taken without consent and was immortalized. HeLa cells are considered among the fundamental models of biology and are used in almost every laboratory in the world. Her genome has been sequenced and made accessible without consent from her family.
Genomic sequences can be used to reidentify the subject (as shown by a 2013 study) and can be used to identify potential susceptibility to different diseases. For example, an employer might discover that one of its employees has cancer or another disease and could discriminate against him or her.
“When you provide your genetic information to a DNA testing company, you are also providing information about those related to you — including distant cousins. When your relatives, including distant ones whom you may not even know, provide their DNA, they are also providing genetic information about you.” — Darnovsky (source)
Moreover, as shown, these sequences are not always kept securely. Especially company databases can be hacked (92 million sequences from the MyHeritage service were on a private server). In addition, companies are not clear about how they use the data and often sell it to third parties that are not specified. Not to mention that the laws are currently rather vague, and it is also not clear who owns the rights.
Companies have a very transparent sharing policy with government authorities, and several activists have noted:
“There’s great concern in the law-enforcement context both about civil liberties in general and about disproportionate impact on communities of color, because they are already disproportionately in contact with police.” — Darnovsky (source)
Algorithm and biases

“Of all the forms of inequality, injustice in health is the most shocking and inhuman” — Martin Luther King Jr
As shown, algorithms can have racist biases (such as facial recognition algorithms have led to erroneous cases of arrests of black people). But there are also examples in the field of medicine: A model for allocating limited resources to new mothers disfavored black mothers and favored white mothers, a clinical algorithm for kidney considered black patients healthier than reality (reducing access to care), algorithms for melanoma recognition performed worse on darker skin, several models of oximeters were less accurate on darker skin (and patients were less likely to receive supplemental oxygen).
On the other hand, the use of these models impacts people’s lives, and more subject participation would be needed. In fact, several studies state that citizens should participate in the discussion about the regulations of these algorithms especially if they may be harmful. Initiatives such as BLOOM have indeed put greater inclusion as a key issue (for more information: here).
The voices behind the sequences

The debate began years ago. While researchers called for more transparency toward the data with a letter in Nature, others responded, “As Indigenous geneticists, we remind researchers of the broken promise to extend medical benefits to communities whose genomic data are publicly available.”
The authors noted that the genome of indigenous peoples is sought for its unique variations. This has made it possible to study associations between diseases and gene alterations. In fact, indigenous populations having been isolated for thousands of years have a unique genotype. These variations are also the result of interaction with a different environment and represent important information. For example, loci identified in the African Ancestry and Amish communities enabled the development of a drug for cystic fibrosis and lowering cholesterol levels, respectively.
On the other hand, communities have not benefited from the medicine developed due in part to their sequences. Indigenous communities suffer from severe disparities in access to treatments and medicine.
The National Institutes of Health (NIH) has launched the “All of Us” research program, where NIH is committed that 50 percent of participants are from underrepresented communities (including U.S. Indigenous communities: Native Americans, Alaskan Natives, and Native Hawaiians). The goal is to promote inclusion and the fact that communities may also benefit in the future from precision medicine

DNA sequencing companies generally have in their database mainly sequences from people of European descent (more than 80 percent). Therefore, the strongest gene-disease associations have been identified and the data has already been sold to pharmaceutical companies. On the other hand, programs such as “All of Us” given the transparent data policy also allow companies such as Ancestry to access community data and compare it with their own, and even sell it.
Data are not a gift. At best, they are ‘on loan’, and hence revocable if misused. Data are a responsibility not an entitlement. — Nature letter (source)
the call for a more transparent policy (also motivated by researchers as a means of democratizing science) came into conflict with Indigenous data sovereignty (IDS). In addition, the United Nations Declaration on the Rights of Indigenous Peoples (UNDRIP) recognizes and respects the right of Indigenous people to self-determination and self-governance for inclusion in genomic studies. In addition, there is skepticism from Indigenous communities who have dealt with colonialism and racism by the institutions.
Federated learning to preserve data sovereignty
In 2018, the Maori community noted 300 hours of Te Reo Maori language. This dataset would be enough to be able to train models of spell-checkers, grammar assistants, and other NLP applications. However, the Maori community did not want this data to be available to commercial entities and established a Data Sovereignty protocol. In the protocol, they stipulate that if an application is to be built it must be done by the Maori community.
In a letter, Boscarino discusses a method that could allow the indigenous community to participate in scientific projects while maintaining sovereignty over the data itself: federated learning.
Federated learning is a technique for training machine learning models, where datasets are distributed either on multiple devices or in different data centers. The main difference with traditional training techniques is the lack of a central data center. The different nodes in the system train the model independently without the original data being exposed and stored.
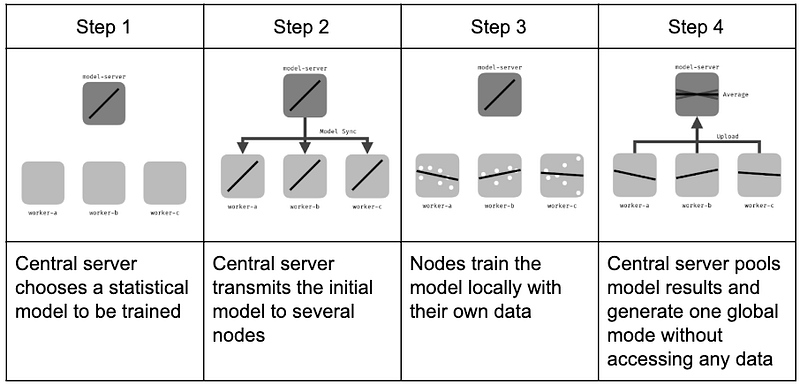
The advantages are greater privacy, the data are not stored by those who train the models, and there is less risk of data leakage. It is also compatible with the indigenous data processing guidelines: OCAP (ownership, control, access, and possession) and CARE (collective benefit, authority to control, responsibility, ethics).
Parting thoughts
Artificial intelligence will have a transformative effect on medicine, enabling the development of precision medicine applications, new therapies, and the discovery of mechanisms of diseases that are not yet understood. However, artificial intelligence requires data.
Data in the medical field is sensitive material. Inside the sequences is information that can also be used for other applications and potential discrimination. To collect data, consensus is essential, but today the discussion has also expanded to other issues.
Indigenous peoples are demanding control over their data. Federated learning could be one of the solutions to allow control by communities and be able to train artificial intelligence models.
If you have found it interesting:
You can look for my other articles, you can also subscribe to get notified when I publish articles, and you can also connect or reach me on LinkedIn. Thanks for your support!
Here is the link to my GitHub repository, where I am planning to collect code and many resources related to machine learning, artificial intelligence, and more.
Or feel free to check out some of my other articles on Medium:





