
Data Integrity
Design systems to prevent manipulation of data, code, and logs
One of my post that may later become a book on Secure Code. Also one of my posts on Application Security.
Free Content on Jobs in Cybersecurity | Sign up for the Email List
I remember sitting in a secure programming class for programmers at a large bank where I worked. The person teaching the class demonstrated an attack that manipulated the logs using a cyber attack. People’s jaws dropped. Someone said, “Wow, I didn’t know they could do that!” I, on the other hand, was surprised that this was the first time people writing banking software became aware of this potential problem. It’s not their fault. The company they work for should have provided security training sooner!
You cannot assume that no one tampered with code, data, logs, configuration, or anything else in your system unless you a.) implement controls to make that impossible in the first place or b.) use a method to validate the system resource has not changed.
Checking the integrity of files and data often involves hashes. I explained what hashes are at a high level in Cybersecurity for Executives in the Age of Cloud. If you are not already familiar with hashes you may want to review that first. In addition to using hashes, you’ll want to understand how to choose the correct algorithm and key size. If you are looking for technical details, I provide some resources in this post and at the end of my last book.
I also explained in that book how important deployment systems are for security. By automating the actions people in your organization take related to deployments you can ensure that people don’t make inadvertent mistakes or make malicious changes during a deployment. This only holds true if you have designed a secure deployment system. For example, the Solar Winds attack and the Target Breach, two cyber attacks I’ve analyzed in case studies, involve altered code deployed using automated systems.
How was it that attackers were able to change the code? Architecting deployment systems is a complex topic beyond code, software, or even technical controls? I may include more details about that in another book. It is often the subject of my consulting calls for IANS Research clients. Sometimes clients will have me review system architectures for them and provide recommendations.
When considering how to maintain file integrity you’ll want to leverage controls outside the software itself. These controls fall into the realm of governance, networking, and system permissions. Perhaps you deploy a system that writes files to a write-once-read-only data store. That way the files can be written but no one is allowed to alter them after that point. Database stored procedures and update mechanisms can use this same approach. You can ensure proper permissions to cloud storage systems as well.
Those things are all very important but this book focuses on the code individual developers write. You may not have control over your deployment system and how it works. However, you should be aware of deployment systems and the integrity of your code as it moves through that system. Perhaps you can do something within your application and code to validate the integrity of your application when it gets deployed and while it is in use. You may not control the operating system to which your application gets deployed. But you can check the integrity of files and data as they move through your application and systems.
Checksums and Signatures
Attackers may try to manipulate code that your system uses. How can you ensure that code hasn’t changed? Different methods exist at the system or architecture level that an organization can use to validate files as they pass through processes. But what can an individual software engineer do to prevent modified code?
Let’s say your application uses a configuration file. You could design your code to make a hash of the configuration file when the application gets deployed. Store the configuration file hash in a database. Each time your application runs or your application reads the configuration file, you could check to see the hash in the database matches. For this to work, people who have access to change the configuration file should not have access to change data in the database. The application itself should not be able to alter the hash once created.
When you download software, sometimes the developer will provide what is known as a checksum. Software developers often provide checksums, a type of cryptographic hash, or signatures that allow you to validate that the software the original author wrote has not changed. When you download and use software from the Internet, ensure you obtain a hash in a secure manner and check to see that no one has altered the software before you use it. How could they do that? That’s another topic in my prior book. Just be aware that they can, and make sure you check the integrity of third-party code.
Checksums are often available for many different types of software. Here are some examples:
You can obtain the checksum, otherwise known as a digest, for a docker container using the following command:
docker image --digests [container]Once you obtain the digest compare it to the digest provided by the author. Some deployment systems will check this for you.
The Apache Software Foundation provides checksums for the software it maintains. They provide information about how to obtain the checksum here:
The MAC OS Notarization process tries to validate software downloaded from the Internet. It’s important to understand what this will and will not check as you are downloading applications and code.
I have been looking into how cloud SDKs are verified when you install them. For example, are you using an install from the cloud provider? Do you pull code from GitHub? Or do you download a library directly from the Internet? Maybe I’ll write more about this topic in the book along with some additional information on code signing.
While pentesting I see numerous third-party URLs embedded in applications. So many different services offer a mechanism to load code from a third party when the page is loaded and execute it. How do you know that someone has not altered it in transit? How do you know that the software developer that wrote the code has not changed it since you last tested it?
Ideally, you would host the code on your own systems. Instead of pulling code straight off the Internet, pull it into your own repository. Test it thoroughly and understand how it impacts the performance, security, and accuracy of your application. Once you have tested it, deploy it along with your own software in your normal deployment process.
Yes, you can do that with Google Fonts:
By doing so you will avoid one of the security problems I mentioned in my last post — inadvertently including sensitive data in the referrer sent to the third-party site. In addition, you can verify the integrity of the code. You know when it changes. More importantly, you can test it prior to serving it up to your customers.
With certain systems, you cannot host the code locally. They require you to include a URL in your webpage code to use the service. So let’s say you include do that. You test it as you normally would before deployment. Then you deploy your application as you normally do. How do you know that after that point the code delivered from the URL you tested hasn’t changed?
One of the checks I perform during penetration tests is to see if a subresource integrity (SRI) check exists for third-party code included in web pages. You can provide a cryptographic hash of the code you expect the third-party resource to deliver. That hash allows browsers to check the integrity of the code and determine whether or not the content should be downloaded and executed.
Integrity of files your application processes
When your application uses files you may want to check the integrity of those files as they pass through different systems or get stored in alternate locations. Let’s say you upload a file to an S3 bucket. You may want to check that the file upload occurred correctly and the file is intact. Once the file exists in the bucket you may want to verify that it has not changed. AWS S3 offers a way to check the integrity of uploads using an MD5 hash:
Glacier, Amazon’s long term storage service, also offers the ability to perform a checksum using SHA-256:
Any time you pass a file to another system over the Internet or even on your own network you might want to perform a file integrity check. That will help ensure the data has not been corrupted in transit or maliciously altered. I don’t know all the details about how the Solar Winds update process works, but it seems like additional file integrity checks during the update process might have helped prevent attackers from inserting malicious code into that process, in addition to tighter network security. I covered those points in part 3 of my series on the Solar Winds Breach.
Integrity for authentication
Another problem I often find on penetration tests involves missing signature checks on JWT tokens. When I can manipulate the token and resubmit a successful request, that indicates the developer has not correctly checked the signature of the token. I should not be able to alter the token.
You cannot trust tokens accessible to clients (typically web browsers). Your web application may make several requests to the web server to carry out an action or display a page. I can capture every one of those requests and manipulate the data if I am running the application on my own system. If the request contains a JWT token and your application doesn’t check that the token hasn’t been altered, I can change a value in the token to whatever I want.
Let’s say your application includes scopes in the token that indicate what I’m allowed to access. Perhaps I’ll just insert my own new scope and change the token when sending it back to the server. If the application presumes the token I submit is accurate I might get access to data to be able to perform actions that the system should disallow.
How should you verify the signature of a JWT? Perhaps your application server does this for you. Confirm that your system follows the standards and guidance in the latest specification. At the time of this writing you can refer to the following JWT specification:
They provide current best practices here:
The recommended algorithm you should use may change over time so I’m not going to recommend one in this book. Rather, ensure that you know what the current standard and best practices are when using JWTs. Monitor for changes in guidance as attackers find new ways to access data. Perhaps JWT will not be the most popular means for checking website permissions in the future. Whatever mechanism you use, ensure that no one can tamper with the data used to perform authorization checks and insert their permissions of choice!
Data integrity in your database
As I mentioned before I have a lot of experience developing e-commerce and back-office banking systems. I wrote about relational databases (RDS) and NoSQL databases in a prior post in relation to eventual consistency. That’s not the only thing you need to worry about when it comes to data integrity.
When databases first came out (and to this day in Excel spreadsheets) data got stored in flat files. One file might have a list of customer contacts, along with the address of each contact. What if you have a number of contacts who work at the same company? What’s the problem with storing your data this way?
First of all, you’ll have to retype the address for each customer. Not only do you have to store data, you might make a mistake typing the address over and over. What if the company moves to a new address? Now you have to update each of those records to the new address.
Name Company AddressSanta Clause Santa's Workshop 123 Elf Road, North Pole
Rudolf Santa's Workshop 123 Elf Road, North Pole
Mrs. Clause Santa's Workshop 123 Elf Road, North Pole
Buddy the Elf Santa's Workshop 123 Elf Road, North PolkaMay reasons exist for relational database designs but one of the most important for banking systems is data integrity. We don’t want numbers to be out of sync across the database, like the last address in the above example. How can we fix that?
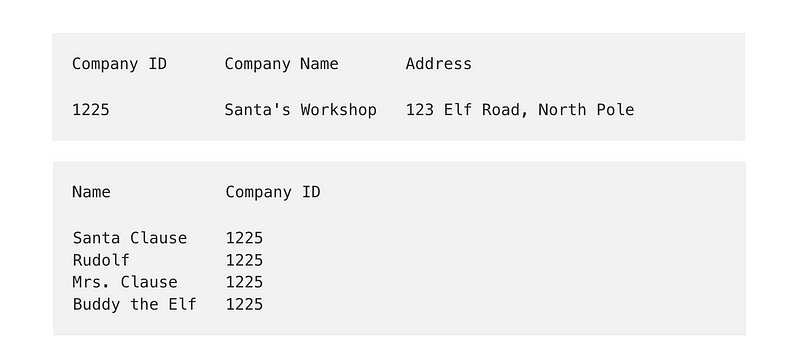
Let’s create a company table and add a record for Santa’s Workshop.
Company ID Company Name Address1225 Santa's Workshop 123 Elf Road, North PoleNow change the contact table to reference the company table.
Name Company ID Santa Clause 1225
Rudolf 1225
Mrs. Clause 1225
Buddy the Elf 1225Let’s say Santa’s workshop moves to Miami, Florida. We can update the address in the company table and there’s no need to change the contact table at all.
There are a few other things we need to worry about to ensure the integrity of our data. What if someone puts a value in the company ID field that doesn’t exist?
Name Company IDSanta Clause 1225
Rudolf 1225
Mrs. Clause 1225
Buddy the Elf 1325 << OOPSTo prevent that databases let you create something called foreign key constraints. These constraints ensure that you can only enter data from a particular field in another table. In this case, we would add a foreign key constraint for Company ID in the contacts and reference the Company ID field in the company table. Now someone can only enter a record that exists in that other table.
What could go wrong without a foreign key constraint? Perhaps a developer accidentally inserts a null value into the table instead of a numeric value when one is required. That could lead to some of the null errors I mentioned in regards to data types and references.
Consider an online trading system that has a reference to a customer that is supposed to receive some kind of payment. The developer adds a customer ID value of one plus the last customer ID in the database. The developer then visits the trading system website and signs up as a new customer. Now that customer will have the next ID (last ID + 1). The payout that was supposed to go to an existing customer goes to this new customer instead. With a foreign key constraint, the developer would have been required to enter an existing and valid customer ID.
Databases can have all types of other constraints to maintain the integrity of the data. If you are creating a database, ensure you study database design so you understand how to properly maintain the integrity of your data. Data integrity involves not only the design of your indexes and tables but other topics I covered in my posts on transactions, data types and references.
Audit tables in databases
Financial systems often make use of audit tables to monitor systems for inappropriate actions, whether accidental or malicious. Each time a record gets created in a table, a record gets inserted into an audit table that mostly matches the layout of the table that got updated. That way the system can store a copy of the record in the audit table in addition before updating the record.
Often the audit table will have an incremental ID. That way, as I mentioned before, you can see if a record got deleted because a gap in numbers will exist. In other words, if the IDs in the table are 1, 2, 3 and someone deletes the record with ID 2, the ids in the table will be 1, 3. You’ll be able to tell someone deleted a record.
When designing audit tables it is important to give applications the ability to write a new record in the table, but not delete or update any records. That will help ensure the integrity of your audit table. Audit tables need to be periodically truncated in most cases. That process needs to have permissions to delete, but not write to the audit tables.
Audit tables will also usually include the username that made the change, a timestamp, and other useful information. Perhaps the update was related to a particular process name. Any failures or anomalies related to your audit tables should be logged and immediately investigated.
The concept of audit tables in financial applications has applications for many other types of applications that process sensitive data. In some systems, you might log the data to a file instead of a database. The same principles apply.
Next Steps
- Check the integrity of software you download so no one tampered with it before you install it.
- Host third-party code instead of downloading it from the Internet to ensure the code you are running matches what you tested.
- Use subresource integrity checks to verify third-party code coming from a remote site matches what you tested.
- Consider at what points in your application you should check the integrity of the files you process to ensure they are not corrupted and or altered
- Check the integrity of JWT tokens with signature verification before granting access to data or allowing an action in an HTTP request.
- Use proper database design and proper data types to ensure users can only add, update, or delete data in a valid manner.
- Use audit tables in databases storing sensitive information and design them to prevent manipulation.
- Log any anomalies or errors related to audit tables and investigate immediately.
Follow for updates.
Teri Radichel | © 2nd Sight Lab 2022
About Teri Radichel:
~~~~~~~~~~~~~~~~~~~~
⭐️ Author: Cybersecurity Books
⭐️ Presentations: Presentations by Teri Radichel
⭐️ Recognition: SANS Award, AWS Security Hero, IANS Faculty
⭐️ Certifications: SANS ~ GSE 240
⭐️ Education: BA Business, Master of Software Engineering, Master of Infosec
⭐️ Company: Penetration Tests, Assessments, Phone Consulting ~ 2nd Sight LabNeed Help With Cybersecurity, Cloud, or Application Security?
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
🔒 Request a penetration test or security assessment
🔒 Schedule a consulting call
🔒 Cybersecurity Speaker for PresentationFollow for more stories like this:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
❤️ Sign Up my Medium Email List
❤️ Twitter: @teriradichel
❤️ LinkedIn: https://www.linkedin.com/in/teriradichel
❤️ Mastodon: @teriradichel@infosec.exchange
❤️ Facebook: 2nd Sight Lab
❤️ YouTube: @2ndsightlab





