
Data Engineering : Challenges, Airflow, and the Rise of MageAI
The modern replacement for Airflow.
Data engineering has become an integral part of the modern business landscape. With the exponential growth of data and the increasing need for data-driven decision making, organisations are relying on data engineering to extract valuable insights from raw data. Data engineering involves the collection, transformation, and storage of data in a way that enables efficient analysis and reporting.
One of the key reasons why data engineering is important is that it allows organisations to gain a competitive edge. By effectively managing and utilising their data, businesses can make informed decisions, identify trends, and predict future outcomes. Data engineering also enables organisations to automate processes, improve operational efficiency, and enhance customer experiences.
Data arrives from every direction, growing in scale and complexity. Hidden in the data is knowledge and insight that is full of potential.
TLDR;
In this article, we explore the significance of data engineering in modern business, the challenges it presents, and the role of Apache Airflow as a widely recognized tool. While Airflow has proven effective, it comes with complexities and limitations. Enter MageAI, positioned as Airflow’s successor, offering a user-friendly interface, real-time visualisation, and tailored features for efficient data pipeline management. We delve into the strengths and limitations of both tools, highlighting MageAI’s potential to revolutionise data engineering with its focus on simplicity, and specific use cases like Data Pipelines.
Key Challenges in Data Engineering and Transformations:
- Large and Complex Datasets: Dealing with the ever-growing volume and variety of data poses a significant challenge. Data engineers must employ robust infrastructure and advanced algorithms to efficiently process and store massive amounts of data.
- Data Ingestion — Handling the Diversity of Data : Data engineering kicks off with the critical process of data ingestion, where information is gathered from various sources. However, the challenge lies in the diversity of data formats and structures. Diverse sources often necessitate data transformation before it can undergo further processing and analysis. This initial step sets the tone for the entire data engineering pipeline, demanding robust mechanisms for harmonizing disparate data sources.
- Data Integration -Bridging the Gap Between Systems : One of the primary objectives in any data engineering endeavor is to connect disparate information sources and integrate data from different systems. Legacy systems, often lacking built-in capabilities to seamlessly connect with modern software, pose a significant challenge. Overcoming this hurdle requires innovative solutions that ensure smooth interoperability and data flow across the entire ecosystem.
- Data Quality and Consistency: Ensuring the accuracy, completeness, and reliability of data is paramount. Data engineers engage in cleaning and validating data while implementing data governance policies to maintain data integrity.
- Data pipelines orchestration can be quite complex and involve multiple stages and dependencies. This can be a challenge as coordinating and managing the execution of various data processing tasks across different systems or components is not an easy feat. Data dependencies may exist between different processing stages or tasks, where the output of one task serves as the input for another. Thus managing these dependencies and ensuring the timely availability of required data inputs can be complex.
To address the challenges mentioned earlier, various tools have been explored, but only a select few have proven to make a significant impact, with one notable solution being the open-source platform Apache Airflow. Recognised for its versatility and effectiveness.
Apache Airflow has emerged as a powerful tool for designing, scheduling, and monitoring complex data workflows
The Landscape of Industry Giant: Airflow
Apache Airflow is an open-source platform for developing, scheduling, and monitoring batch-oriented workflows. Airflow’s extensible Python framework enables you to build workflows connecting with virtually any technology. A web interface helps manage the state of your workflows.
Apache Airflow, predominately based on DAG — or a Directed Acyclic Graph — is a collection of all the tasks you want to run, organised in a way that reflects their relationships and dependencies. A DAG is defined in a Python script, which represents the DAGs structure (tasks and their dependencies) as code.
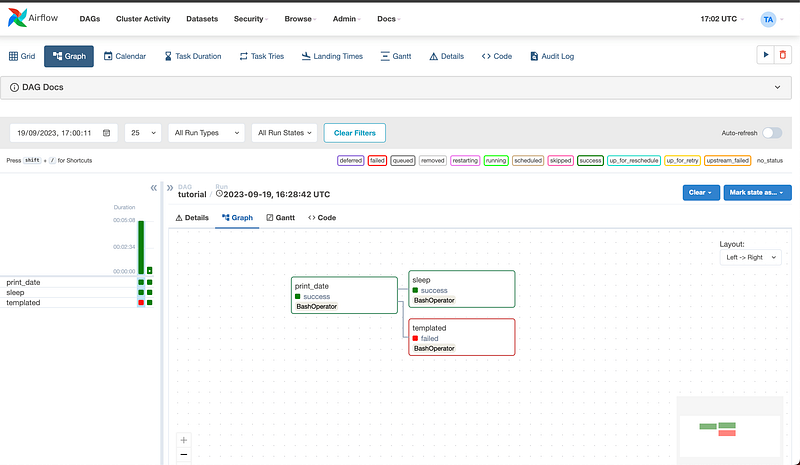
Overview of DAGs
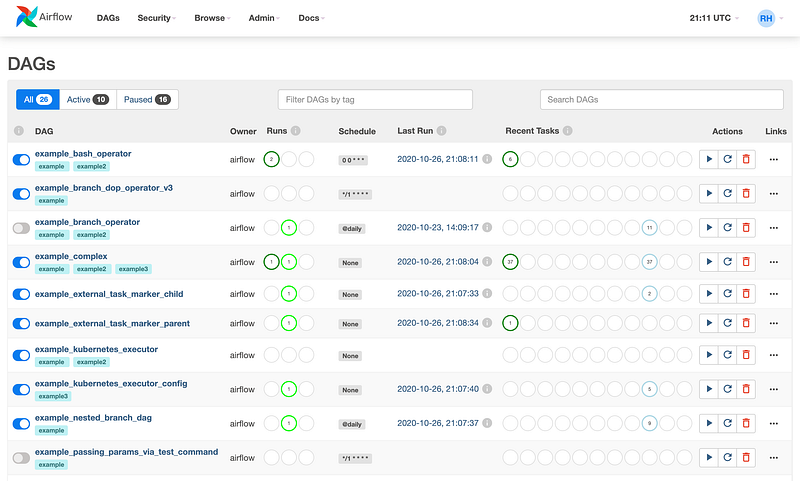
Visualisation : DAG’s dependencies and their current status
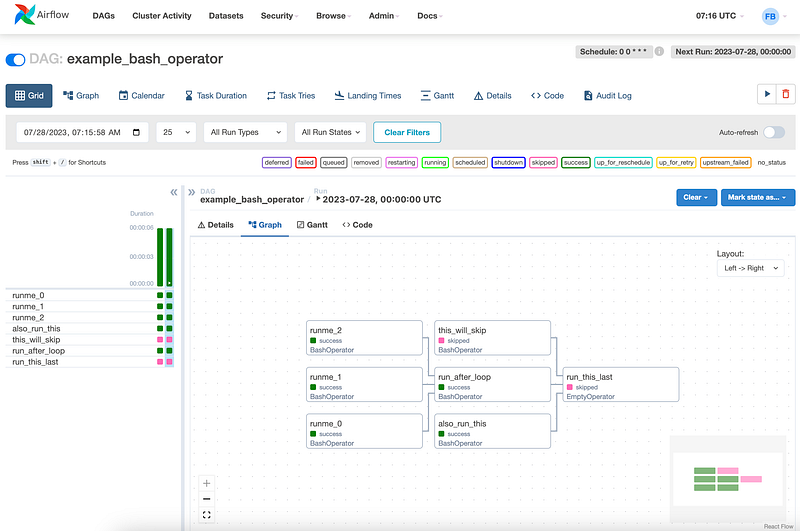
Benefits of Airflow
- DAGs for Workflow Definition: Utilizes Directed Acyclic Graphs for structured and clear workflow definition.
- Dynamic and Extensible: Highly extensible, allowing the integration of custom operators and dynamic configurations.
- Scheduling and Triggering: Powerful scheduling capabilities based on time, triggers, or data availability.
- Rich Set of Operators: Offers a diverse range of built-in operators for common tasks and seamless integration with external systems.
- Monitoring and Logging: Web-based interface facilitates easy monitoring, logging, and troubleshooting of workflows.
- Community and Ecosystem: Supported by an active open-source community and an expanding ecosystem of plugins and integrations.
While Apache Airflow is a well known player in the data engineering domain, it does have its own limitations. Lets discuss that in detail :
- Complexity: Setting up and configuring Airflow can be challenging, particularly for those new to data engineering. Its architecture and concepts require time and effort to grasp.
- Limited Native Support: Airflow may lack native support for specific data formats and transformations, necessitating custom code or plugins, which can be time-consuming and error-prone.
- Scheduling Constraints: The scheduling capabilities of Airflow may not align with the requirements of real-time or near-real-time data processing, limiting its application in certain scenarios.
- Limited UI Feedback : Apache Airflow’s web interface is designed to manage workflows efficiently, but it has limitations that may impact user experience, particularly for those who prefer a graphical interface over coding.
- Python Dependency : Apache Airflow, by default, operates within a single Python environment, potentially causing conflicts with dependencies in custom task code. While predefined Airflow Operators are designed to avoid issues, custom Python code or operators may introduce conflicts, necessitating careful dependency management for smooth workflow execution.
While exploring the top players in the market, let’s also shift our focus to new contenders with the potential to surpass the established leaders. One such noteworthy entrant is MageAI Data Engineering as a Service.
So, what exactly is MageAI?
MageAI is an open-source data pipeline tool designed for the transformation and integration of data. Offering the ability to build, run, and manage data pipelines efficiently for data integration and transformation.
It positions itself as the modern successor to Airflow. Lets watch 2 mins demo and decide yourself:
Quick Demonstration
Build with MageAI UI
Mage offers a robust end-to-end control experience for data pipelines through its rich user interface. It supports the entire workflow, from pipeline development to production launch, with seamless integration of version control tools. This makes Mage a versatile and user-friendly solution for efficient data engineering tasks.
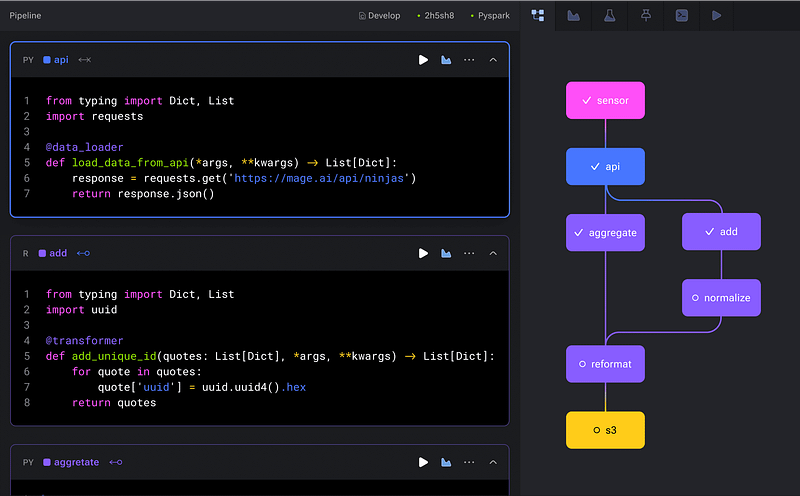
Real Time Run & Preview
Mage simplifies data pipeline development by handling most of the heavy lifting, including exception handling. Its intuitive user interface allows for easy creation of relationships between pipeline blocks without writing additional code. One standout feature is the ability to preview pipeline results during development, eliminating the need to wait for deployment to verify data. This preview option also enables visualization of data, streamlining the development process further.
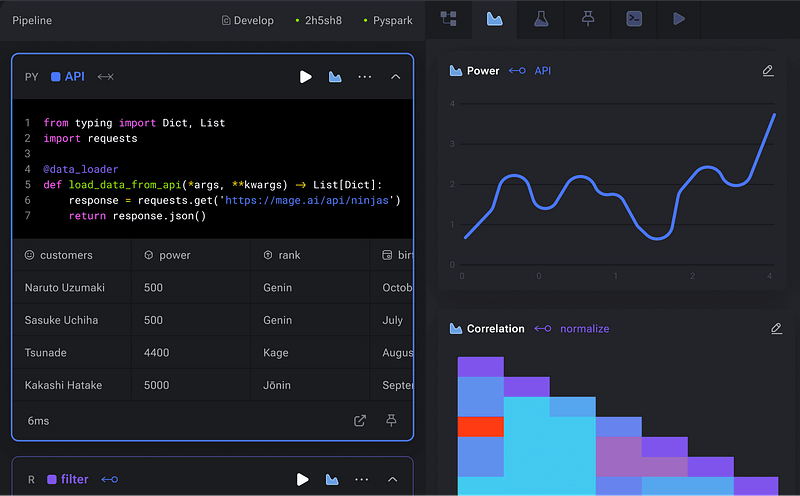
Supported pipeline integration:
Mage offers several types of data pipeline integration:
- Data Integration:
- Mage supports Data Integration with various third-party sources, including APIs, SaaS, databases, data warehouses, and data lakes.
- It adheres to the Singer spec, a community standard for data integrations.
- Mage standardises the spec and provides common classes and methods to simplify and expedite implementation.
2. Standard Batch:
- Mage allows the creation of custom code-based standard batch pipelines.
- Users can write code in Python, R, and SQL to tailor batch processes according to their specific requirements.
3. Streaming:
- For streaming pipelines, Mage currently supports integration with Kafka and Azure Event Hub.
- Users can build and manage streaming data pipelines seamlessly within Mage.
4. dbt Integration:
- Mage features built-in integration with dbt (data build tool).
- Users can write dbt code using Mage and deploy it along with the entire pipeline, streamlining the process of transforming and modeling data.
The Face-Off: MageAI vs. Airflow
As organisations traverse the landscape of data engineering solutions, the comparison between MageAI and Airflow becomes crucial for making informed decisions. Let’s delve into the intricacies of both tools to understand their strengths and limitations.
Airflow: The General-Purpose Workhorse
- Complexity and Generalisation:
- Airflow stands out as a more complex tool due to its nature as a general-purpose workflow management system.
- Its versatility allows automation of various types of workflows, making it a robust choice for diverse use cases.
2. Configuration Challenges:
- Airflow demands more configuration efforts compared to MageAI. Setting up and fine-tuning Airflow may be challenging, especially for those new to data engineering.
3. Workflow Representation:
- Airflow utilizes Directed Acyclic Graphs (DAGs) to represent workflows, which can be intricate and require a learning curve.
4. Code Handling and Relationships:
- Writing code in Airflow may involve more intricacies and a steeper learning curve.
- Relationships between different blocks of a pipeline in Airflow might require additional code, adding to the complexity.
5. Real-time Data Verification:
- Airflow may not provide real-time visualisation of pipeline results, necessitating deployment in the orchestration layer for data verification and analysis.
MageAI: Tailored Simplicity for Data Pipelines
Enter MageAI, a dynamic player designed explicitly for data pipelines. This innovative framework simplifies development, offering a user-friendly interactive notebook UI.
Let’s delve into other MageAI’s features and advantages:
- Simplicity: MageAI provides a simple developer experience, allowing local development with a single command or cloud deployment using Terraform.
- Language Flexibility: Developers can write code in Python, SQL, or R within the same pipeline, providing unmatched flexibility.
- Best Practices Built-in: MageAI incorporates engineering best practices with modular and reusable code, eliminating the complexities associated with DAGs.
- Interactive Code: An interactive notebook UI allows developers to see immediate results, enhancing the development experience.
- Real-time Preview and Visualisation: One of MageAI’s notable advantages is the ability to preview and visualize pipeline results in real-time, enhancing the verification and analysis process.
- Data Integration Capabilities: MageAI leverages the Singer spec, a community standard, for seamless data integration with third-party sources, simplifying connections across various platforms.
- Pipeline Customisation: In Standard Batch pipelines, MageAI empowers users to write their own code in Python, R, or SQL for creating custom batch processing pipelines.
- Streaming Capabilities: For Streaming pipelines, MageAI supports a variety of platforms including Kafka, Azure Event Hub, Google Cloud PubSub, Kinesis, and RabbitMQ, providing flexibility in real-time data processing.
- Collaborate on cloud : Develop collaboratively on cloud resources, version control with Git, and test pipelines without waiting for an available shared staging environment.
Personal Verdict: MageAI’s Tailored Excellence
While both Airflow and MageAI serve distinct purposes in the data engineering realm, MageAI’s tailored simplicity, user-friendly interface, and focus on data pipelines position it as a strong contender. The real-time visualisation, simplified code handling, and specific design for data engineering needs contribute to MageAI’s appeal.
As organisations seek efficient and streamlined data engineering solutions, MageAI emerges as a compelling option poised to revolutionise the data pipelines and orchestration. In the race between generalisation and specialisation, MageAI seems to have found its pace, promising a future where data engineering is both powerful and accessible.
References :
I hope you like this article. If you did, please share it with your friends And Don’t forget to clap and follow for future updates!
Thanks for reading!




