
Data Augmentation par fastai v1

Cet article fait partie de la série “Deep Learning in practice”.
Résumé
Dans l’objectif d’améliorer la performance des réseaux de Deep Learning de type ConvNet par l’augmentation du nombre des images d’entraînement, cet article présente les 4 solutions les plus utilisées dans le monde académique et industriel: la collecte de davantage d’images, le Transfer Learning, l’utilisation des techniques de Data Augmentation (DA) et la génération de nouvelles images via les GANs. En particulier, cet article présente en détails la Data Augmentation, son intérêt à des fins de généralisation, ses techniques et ses conditions de mise en pratique. Afin de permettre au lecteur de reproduire les résultats présentés dans cet article, le code implémenté via la librairie fastai v1 est donnée dans un Jupyter Notebook. Cette librairie permet en effet d’appliquer très facilement toutes les techniques de Data Augmentation afin de multiplier les images d’entraînement et améliorer ainsi la performance des réseaux de Deep Learning. Par ailleurs, je rappelle au début de l’article ce qu’est aujourd’hui l’Intelligence Artificielle afin de remettre en contexte l’intérêt de connaître les techniques de Data Augmentation et je souligne également l’importance de choisir des images d’entraînement en fonction du contexte d’utilisation et de l’objectif du réseau à entraîner. J’insiste enfin sur le fait que les images d’entraînement (réelles, transformées ou générées) doivent être les mêmes que celles qui seraient utilisées par un humain pour atteindre le même objectif.
Note (30/01/19): dans l’article, le terme «algorithme» a été remplacé par «modèle» quand nécessaire. Ainsi, un réseau neuronal profond (ou réseau de Deep Learning ou architecture de Deep Learning) est appelé “modèle” (ou réseau) et la méthode d’apprentissage (BackPropagation du gradient) est appelée “algorithme”.
IA expliquée
Définition
L’expression Intelligence Artificielle (IA) peut avoir plusieurs interprétations mais de manière générale, l’IA a comme finalité la reproduction d’une action réalisée par des animaux ou des humains (note: avec la découverte des modèles génératifs comme en particulier les Generative Adversarial Networks ou GANs en 2014, l’IA peut dépasser aujourd’hui ce cap de la reproduction en étant capable de créer de nouveaux possibles comme des images semblant être réelles tel que décrit dans “Progressive Growing of GANs for Improved Quality, Stability, and Variation” en février 2018).
Deep Learning
Peut-être saurons nous un jour créer de l’IA “biologique” mais jusqu’à présent, l’IA est créée au moyen d’un programme informatique appelé Réseau Neuronal Artificiel dont le fonctionnement imite les processus cognitifs, cad les processus engagés par le cerveau pour acquérir une connaissance et décider d’une action. Les architectures les plus utilisées aujourd’hui sont les réseaux neuronaux profonds ou Deep Learning.
Note: dans cet article, nous utiliserons le terme général de “modèle” (ou réseau) pour désigner un réseau neuronal profond.
Apprentissage
Il ne s’agit pas de coder un ensemble de règles définies à l’avance. Il s’agit au contraire pour le modèle d’apprendre des règles par interaction avec l’environnement comme le ferait un animal ou un humain, c’est à dire à partir de données d’entraînement.
Par exemple, la création d’un classificateur visuel capable de distinguer des objets différents se fera en nourrissant le modèle d’images de ces objets et non pas en codant un ensemble de règles définies par des spécialistes et censées décrire parfaitement chacun des objets. L’état de l’art actuel est d’utiliser un modèle ConvNet (Convolutional Neural Network) pour ce type de tâche.
Note: en pratique, un algorithme d’apprentissage appelé “BackPropagation du gradient” permet de mettre à jour les valeurs des paramètres du modèle lors de son entraînement.
Données d’entraînement
Ce mimétisme par rapport à l’animal ou à l’homme dans la procédure d’apprentissage implique que vous devez fournir au modèle les mêmes données d’entraînement que celles que vous étudierez vous-même.
En gardant le même exemple du classificateur visuel, il faudra ainsi veiller au respect de cette règle lors de l’acquisition de la base d’images qui servira à l’entraînement du modèle et lorsqu’une série de transformations appelée Data Augmentation leur sera appliquée afin de multiplier leur nombre et augmenter la variance de représentation de leurs caractéristiques principales.
Note: la recherche en Deep Learning sur les techniques pour améliorer en particulier la performance des modèles ConvNet s’intéresse depuis 2017 à la création d’images mixtes pour leur entraînement, images qui ne ressemblent en rien à des images de la vie réelle mais qui donnent des résultats surprenants voire meilleurs que les techniques classiques de Data Augmentation (crop, flip horizontal et changements de luminosité/contraste aléatoires). Cependant, comme l’indique le papier de recherche “Improved Mixed-Example Data Augmentation” du mois d’octobre 2018, les scientifiques ne pouvant pas pour l’instant en expliquer les raisons, nous resterons dans cet article sur la ligne communément admise que les modèles de Deep Learning doivent être entraînés avec le même type de données qui seraient utilisées par un humain pour effectuer la même tâche.
Apprendre à généraliser
Afin de pouvoir être utilisé sur de nouvelles données, un modèle de Deep Learning ne doit pas avoir été spécialisé lors de son entraînement (over-fitting). Il doit au contraire avoir appris à généraliser.
Données et Data Augmentation
Cela signifie que l’entraînement du modèle doit lui avoir permis d’apprendre les caractéristiques principales (features) d’un ensemble de données.
Pour cela, il est nécessaire que:
- (data space) l’espace des données d’apprentissage couvre le spectre des possibles, cad contiennent le plus grand nombre d’exemples différents correspondants au contexte d’utilisation du modèle,
- (features space) l’espace des caractéristiques des données d’apprentissage couvre également le spectre des possibles, cad contiennent le plus grand nombre possible de représentation de chaque caractéristique des données.
Pour satisfaire le premier point, il faut donc collecter la plus grande variété possibles d’images d’entraînement correspondantes au contexte d’utilisation et à l’objectif de notre modèle (cf. paragraphe “Des images!”). Des techniques de génération d’images par des GANs par exemple peuvent aussi être utilisées (cf. paragraphe “Génération d’images”).
Et pour satisfaire le second point, il faut appliquer des techniques de Data Augmentation aux images d’entraînement à notre disposition dont les plus courantes sont des transformations affines (le flip horizontal et/ou vertical, la rotation). Il existe également des transformations non affines comme par exemple la variation de luminosité et de contraste, le wrap (perspective), le redimensionnement, le crop aléatoire (partie aléatoire d’une image), le jitter (bruit aléatoire) ou le cutout (carrés noirs aléatoires).
Note: le dropout peut aussi être considéré comme une technique de DA (ajout de bruit) mais comme il s’applique dans les couches cachées du réseau et non directement sur les images en entrée du modèle, nous ne le considérons pas comme telle dans cet article.
Revenons à notre exemple de classificateur visuel via un modèle ConvNet pour mieux comprendre ces 2 points. Lors de son entraînement, les premières couches d’un ConvNet vont apprendre à détecter des formes géométriques basiques comme une ligne droite par exemple de manière invariante en translation et en rotation, alors que les dernières couches pourront détecter des formes plus complexes par combinaison des informations envoyées par les couches précédentes. La performance du ConvNet repose donc en grande partie sur celle des premières couches qui ne peuvent être elles-mêmes correctement entraînées que si les images d’entraînement présentent:
- (premier point) une variété suffisante de possibilités (par exemple, tout type de mangue, toutes les tailles, toutes les couleurs et dans toutes les situations possibles de l’arbre jusqu’à l’assiette si l’objectif est d’entraîner un classificateur visuel à reconnaître une mangue dans toutes les situations),
- (second point: Data Augmentation) et que toutes les variantes des caractéristiques principales soient également présentes dans les images d’entraînement (dans notre exemple, cela implique qu’une mangue doit être présentée dans toutes les orientations, selon tous les points de vue et selon différentes luminosités et contrastes, et pas seulement de côté par exemple).
Prenons encore un exemple pour bien comprendre notre second point. Si par exemple les objets à détecter dans les images sont des droites et que toutes les droites sont toutes dans la même position (disons verticale), avec la même taille, la même luminosité et contraste, le modèle ConvNet ne pourra pas apprendre qu’une droite peut avoir avoir plusieurs orientations (rotation), plusieurs tailles (longueur, largeur et épaisseur), plusieurs luminosités et contrastes (conditions différentes de prise de photos et qualités différentes des appareils photographiques). Ainsi, si nous n’appliquons pas des transformations de DA à ces images de droite (cf. figure ci-dessous) afin de diversifier les variantes de ce qu’est une droite, le ConvNet ne pourra pas l’apprendre et sa performance sera mauvaise lorsqu’il sera utilisé avec de nouvelles images présentant des situations différentes car il aura été spécialisé sur les images d’entraînement (over-fitting).
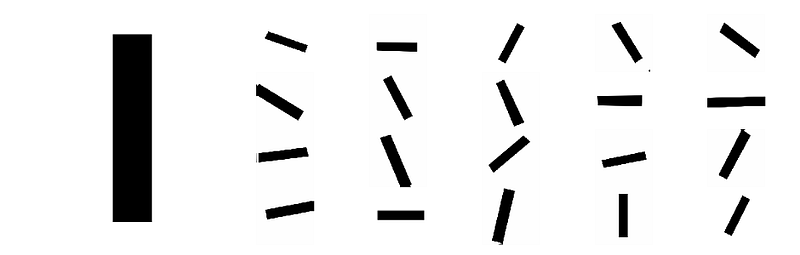
Ainsi, si disposer d’un nombre important d’images d’entraînement est (souvent) une condition nécessaire pour obtenir un modèle performant de Deep Learning, appliquer des techniques appropriées (il n’est pas toujours opportun d’appliquer un flip vertical) de Data Augmentation afin de présenter au modèle le plus grand nombre possibles de variantes des caractéristiques principales qu’il doit apprendre est une condition OBLIGATOIRE.
Des images!
Revenons dans ce paragraphe sur le premier point évoqué précédemment: le nombre des données d’entraînement appliqué au cas des images.
2012 | 1000 images par catégorie
Si les modèles de Deep Learning ont commencé à produire des résultats disruptifs à partir de 2012 dans la reconnaissance visuelle (homme, voiture, chat, fleur…), c’était grâce à l’utilisation en masse d’images labellisées.
En effet, si le réseau de neurones artificiels AlexNet, vainqueur de l’édition 2012 de la compétition ImageNet, a alors réussi à diminuer l’erreur de classification d’images de 26.2% à 15.3%, c’est parce que ses créateurs (en particulier, Alex Krizhevsky et Geoffrey Hinton) ont disposé de 1.2 millions d’images labellisées appartenant à 1000 catégories pour l’entraîner.
Sans cette quantité importante d’images et également l’utilisation — déjà — de techniques de Data Augmentation comme du redimensionnement, du crop et du flip horizontal aléatoires ainsi que des modifications d’intensité de couleurs RGB, le modèle AlexNet, ses 7 couches et ses 60 millions de paramètres n’auraient pas atteint ce niveau de performance malgré ses 6 jours d’entraînement (…).
2019 | 100 images par catégorie
Et en 2019? Est-il toujours nécessaire de disposer d’un nombre important d’images (et de 6 jours d’entraînement…) pour entraîner un modèle de Deep Learning à atteindre des performances autour de 90% à 95% dans la reconnaissance visuelle?
La réponse est non (note: pour obtenir une performance supérieure proche de 100%, il vous faudra cependant à la fois beaucoup plus d’images, une architecture plus profonde de réseau neuronal type ResNet152 et plus de capacités de calcul via plusieurs GPU en parallèle comme l’a démontré la recherche de Google publiée en juillet 2017 “Revisiting Unreasonable Effectiveness of Data in Deep Learning Era”: la performance d’un modèle ConvNet est logarithmiquement lié au nombre des images d’entraînement).
Pourquoi? La raison principale tient au Transfer Learning, cad à la réutilisation de modèles déjà entraînés. En effet, chaque modèle vainqueur de la compétition ImageNet a mis jusqu’à présent en téléchargement les valeurs de ses paramètres après entraînement. Une personne souhaitant développer un classificateur visuel par exemple ne part donc plus de zéro. Elle va spécialiser avec quelques dizaines ou centaires d’images un modèle déjà entraîné (fine-tuning).
Enfin, afin de multiplier ses images d’entraînement et d’augmenter la variance de présentation des caractéristiques principales des objets à détecter (cf. paragraphe “Data Augmentation expliquée”), elle va utiliser des techniques de Data Augmentation.
Ainsi, grâce au Transfer Learning et aux techniques de Data Augmentation, il n’est plus utile de disposer de milliers d’images d’entraînement par catégorie. Une centaine d’images par catégorie suffit (ou même moins si les catégories sont très différentes visuellement).
Génération d’images
Après la collecte de davantage d’images et l’utilisation des techniques de Data Augmentation, une troisième solution existe pour obtenir plus d’images d’entraînement: les Generative Adversarial Networks (GAN) qui permettent de générer de nouvelles images.
Inventés en 2014 par Ian GoodFellow, les GAN ont été utilisés dans de nombreuses applications de création de textes (VGANs) ou d’images (DCGANs). Ils permettent également de transférer le style d’une image vers une autre (CycleGAN), créant ainsi une nouvelle image. Ces images générées pourraient être utilisées par exemple pour entraîner une voiture à conduire de nuit ou sous la pluie en utilisant uniquement les données collectées lors de journées ensoleillées. Dans le cas de la reconnaissance de lieux, nous pourrions de la même manière générer des images de nuit à partir des images de jour à des fins d’entraînement de notre modèle.
Il a été démontré qu’une telle utilisation des GANs, même avec des ensembles de données relativement petits, est efficace dans le cadre de l’entraînement d’un réseau de Deep Learning (“DeLiGAN : Generative Adversarial Networks for Diverse and Limited Data” en juin 2017). Ils se sont ainsi révélés extrêmement efficaces pour augmenter les ensembles de données comme l’utilisation des CycleGANs présentée dans cet autre projet “ The Effectiveness of Data Augmentation in Image Classification using Deep Learning” en décembre 2017.
Attention à la “sélection” des images!
Encore un point avant de voir le code des techniques de Data Augmentation: il faut que les images d’entraînement correspondent au contexte d’utilisation et à l’objectif du réseau visuel à entraîner (par exemple, s’il s’agit d’un classificateur de fruits en supermarché, il n’est pas utile de télécharger des images de fruits accrochés aux arbres) mais à l’inverse, il ne faut pas trop restreindre/sélectionner le type d’images (par exemple, pour un classificateur de fruits en supermarché, il faut garder aussi les images des étalages par exemple et ne pas garder uniquement les images avec le fruit en gros plan).
C’est la nature et la force d’un réseau neuronal visuel profond: si les images d’entraînement couvrent un large spectre de possibilités, il va apprendre à reconnaître l’objet en question dans de multiples situations et sera ainsi d’autant plus efficace en mode utilisation. Il ne sera ainsi pas nécessaire de restreindre un utilisateur futur de ce réseau dans le type d’images à lui présenter pour obtenir une prédiction.

Pas n’importe quelle technique de Data Augmentation!
Revenons dans ce paragraphe sur le second point évoqué précédemment: les techniques de Data Augmentation et leur utilisation opportune.
Exemple 1: classifier des images de livres suivant la langue
Si je vous demande d’apprendre à classifier des images de livres suivant la langue utilisée sur la page de couverture, il est naturel de vous fournir des images sous la forme visuelle suivante:

Mais pour l’entraînement de notre modèle d’IA dont l’objectif est également de classifier des images de livres suivant la langue, les transformations suivantes vous semblent-elles pertinentes pour multiplier les images d’entraînement?

Non. En tant qu’humain, ces transformations ne feraient que créer des images apportant de la confusion dans votre apprentissage. Il en est de même pour notre modèle d’IA.
Exemple 2: classifier des images de fruits
Si je vous demande à présent d’apprendre à classifier des images de fruits, il est naturel de vous fournir des images sous la forme visuelle suivante:

Et si nous appliquons les mêmes transformations à ces images de fruits que celles appliquées précédemment aux images de livres, quel sera à présent votre avis sur leur pertinence dans le cadre de l’entraînement de notre modèle d’IA dont l’objectif est à présent de classifier des images fruits?

Aucun problème. Une pomme, une mangue ou une orange garde exactement les mêmes caractéristiques visuelles après des transformations de flip horizontal/vertical ou de rotation. Ces transformations qui n’étaient pas pertinentes dans le cas précédent le sont ici autant pour un humain que pour un modèle d’IA.
(Easy) Data Augmentation avec fastai v1
Comme l’équipe d’AlexNet nous l’a montré dès 2012, le monde n’a pas attendu la librairie fastai v1 sortie en octobre 2018 pour pouvoir faire de la Data Augmentation sur les images mais ce qui marque une rupture, c’est la facilité d’utilisation des outils fastai pour la création d’images potentiellement en nombre infini: 2 lignes de code suffisent! (1 ligne de définition des transformations et 1 ligne pour appliquer ces transformations aux images). Il est à noter que nous pouvons moduler l’application de ces transformations par une probabilité p (cf. Randomness dans fastai v1).
Note: video de Jeremy Howard à propos de Data Augmentation (lesson 6, 2019)
Prenons l’exemple de la photo ci-après de la Tour Eiffel à Paris et regardons les possibilités de transformation par fastai v1.

Code
Dans le reste de cet article et dans le notebook associé, nous utiliserons la function get_img() afin d’accéder aux images, plots_of_one_image() afin de les afficher après transformations par la fonction apply_tfms() de fastai v1 (credit: les codes utilisés ci-dessous et dans le notebook sont issus ou inspirés par ceux de “Images transforms” de fastai v1).
Après avoir installé fastai v1, voici le code à insérer au début de votre notebook:
# No need to reload the notebook if any change in the fastai library
%reload_ext autoreload
%autoreload 2# Display images in the notebook
%matplotlib inline# Import the vision library from fastai
from fastai.vision import *# Function that returns an image from its url
def get_img(img_url): return open_image(img_url)# Function that displays many transformations of an image
def plots_of_one_image(img_url, tfms, rows=1, cols=3, width=15, height=5, **kwargs):
img = get_img(img_url)
[img.apply_tfms(tfms, **kwargs).show(ax=ax)
for i,ax in enumerate(plt.subplots(
rows,cols,
figsize=(width,height)[1].flatten())]Application des transformations (apply_tfms)
[ apply_tfms() dans fastai_v1 ]
La fonction qui applique les transformations aux images est apply_tfms(). Elle les applique dans l’ordre suivant:
- redimensionnement: si une taille est donnée (
size), elle redimensionne l’image de telle manière que le côté avec la plus petite taille soit redimensionné selonsize. - coordonnées (TfmCoord): transformations non affines comme jitter, skew, tilt, symmetric_warp.
- affines (TfmAffine): dihedral_affine, flip_affine, rotate, squish, zoom.
- luminosité (TfmLighting): brightness, contrast.
- pixels (TfmPixel): crop, crop_pad, rand_crop, dihedral, flip_lr, pad, cutout.
Transformations par défaut (get_transforms)
[ get_transforms() dans fastai v1 ]
Fastai v1 possède une fonction get_transforms() qui applique des transformations par défaut et de manière aléatoire avec une probabilité de 75%: crop, flip horizontal, zoom jusqu’à 1.1, luminosité et contraste, wrap (perspective). Elle renvoie 2 ensembles de transformations, un pour les images d’entraînement (get_transforms()[0]), et l’autre pour celles de validation (get_transforms()[1]).
tfms = get_transforms()
plots_of_one_image(img_url,tfms[0])
Changement de la taille (size)
Les images d’entraînement étant rarement de taille identique, il est possible en utilisant l’argument size dans la fonction apply_tfms() de générer des images de même taille carrée ou rectangle qui permettront ainsi de bénéficier de la puissance de calcul du GPU lors de l’entraînement du réseau neuronal.
tfms = get_transforms()
plots_of_one_image(img_url,tfms[0],size=224)
Translation (rand_crop)
[ rand_crop() dans fastai v1 ]
Fastai v1 possède une fonction rand_crop() qui applique des crops de manière aléatoire (selon une probabilité p) pour une taille définie par l’argumentsize dans la fonction apply_tfms(). Le résultat revient à appliquer des translations aléatoires à l’image.
Note: rand_crop() est la transformation minimale par défaut qui est appliquée par fastai v1 aux batchs du dataset de train. L’ensemble des autres transformations par défaut à l’attention des images d’entraînement est contenu dans get_transforms()[0].
tfms = [rand_crop(p=1.)]
plots_of_one_image(img_url,tfms,size=224)
Crop centré (crop_pad)
Fastai v1 possède une fonction crop_pad() qui applique des crops de manière centrée pour une taille définie par l’argumentsize dans la fonction apply_tfms().
Note: crop_pad() (renvoyée par get_transforms()[1]) est la transformation par défaut qui est appliquée par fastai v1 aux batchs du dataset de validation.
tfms = [crop_pad()]
get_img(img_url).apply_tfms(tfms,size=224).show(figsize=(15,5))
Compléter les pixels manquants (padding_mode)
[ padding_mode dans fastai v1 ]
Lors de la rotation d’une image par exemple, il peut avoir des pixels manquants (pixels en noir dans photo ci-après): l’argumentpadding_mode='reflection' (par défaut) ou padding_mode='border' dans la fonction apply_tfms() permet de les compléter.
tfms = get_transforms()
plots_of_one_image(img_url,tfms[0],size=224,padding_mode='reflection')
Rotation (rotate)
Fastai v1 possède une fonction rotate() qui applique des rotations de manière aléatoire (selon une probabilité p) d’un angle compris entre degree_min et degree_max (si degree_max=degree_min, l’angle de rotation est toujours le même).
tfms = [rotate(degrees=(-30,30), p=1.0)]
plots_of_one_image(img_url,tfms)
Luminosité (brightness)
[ brightness() dans fastai v1 ]
Fastai v1 possède une fonction brightness() qui applique des changements de luminosité de manière aléatoire (selon une probabilité p) compris entre change_min et change_max (change=0 transforme l’image en noir, change=1 en blanc et change=0.5 n’applique pas de transformation). D’une certaine manière, cette transformation (comme celle de contraste) permet de simuler la différence de qualité entre les appareils de photos numériques comme les smartphones.
tfms = [brightness(change=(0.1, 0.9), p=1.0)]
plots_of_one_image(img_url,tfms)
Contraste (contrast)
Fastai v1 possède une fonction contrast() qui applique des changements de contraste de manière aléatoire (selon une probabilité p) compris entre scale_min et scale_max (scale=0 transforme l’image en gris, scale>1 en image très contrastée et scale=1 n’applique pas de transformation). D’une certaine manière, cette transformation (comme celle de luminosité) permet de simuler la différence de qualité entre les appareils de photos numériques comme les smartphones.
tfms = [contrast(scale=(0.5, 2.), p=1.)]
plots_of_one_image(img_url,tfms)
Bruit (jitter)
Fastai v1 possède une fonction jitter() qui introduit du bruit d’un certain niveau de magnitude de manière aléatoire (selon une probabilité p).
fig, axs = plt.subplots(1,3,figsize=(20,5))
for magnitude, ax in zip(np.linspace(-0.05,0.05,5), axs):
tfms = [jitter(magnitude=magnitude, p=1.)]
get_img(img_url).apply_tfms(tfms)
.show(ax=ax,title=f’magnitude={magnitude:.2f}’)
Perspective (symmetric_wrap)
[ symmetric_wrap() dans fastai v1 ]
Fastai v1 possède une fonction symmetric_wrap() qui introduit de la perspective de manière aléatoire (selon une probabilité p).
tfms = [symmetric_warp(magnitude=(-0.2,0.2), p=1.)]
plots_of_one_image(img_url,tfms,padding_mode='zeros')
Zoom (zoom)
Fastai v1 possède une fonction zoom() qui permet de zoomer de manière aléatoire (selon une probabilité p).
fig, axs = plt.subplots(1,3,figsize=(20,5))
for scale, ax in zip(np.linspace(1.,2.5,3), axs):
tfms = [zoom(scale=scale, p=1.)]
get_img(img_url).apply_tfms(tfms)
.show(ax=ax,title=f'scale={scale:.2f}')
Cutout (cutout)
Une fonction de cutout() permet d’afficher de manière aléatoire (selon une probabilité p) des carrés noirs dans une image (nombre et taille aléatoires entre un min et un max), ce qui oblige le réseau ConvNet à prendre en compte le contexte et pas seulement à apprendre à reconnaître des caractéristiques (features) de manière isolée (lire “Improved Regularization of Convolutional Neural Networks with Cutout”, novembre 2017). Elle permet ainsi d’entraîner un réseau neuronal avec des informations manquantes le forçant par conséquent à généraliser.
tfms = [cutout(n_holes=(1,4), length=(10, 160), p=1.)]
plots_of_one_image(img_url,tfms)
Utilisation de la DA pour le Deep Learning
Maintenant que nous savons choisir et utiliser les techniques de Data Augmentation (DA) dans la librairie fastai v1, il ne nous reste plus qu’à les appliquer à nos images d’entraînement et de validation de notre modèle de Deep Learning (par exemple, ConvNet) dans le but de l’entraîner.
Rien de plus facile! Il vous suffit de 2 lignes de code pour définir puis appliquer les transformations (tfms) afin de créer l’ImageDataBunch (data) des données d’entraînement et de validation, cad l’objet dans fastai v1 qui regroupe le dataset et le dataloader de Pytorch (rappel: fastai v1 est construit sur Pytorch). Ensuite, la fonction show_batch() permet d’afficher un batch d’images d’entraînement ou de validation pour vérification des transformations appliquées (les transformations seront appliquées aléatoirement et uniquement quand un batch sera appelé; ainsi une même image ne sera jamais présentée de manière identique au réseau lors de son entraînement).
Note: par défaut, fastai v1 applique seulement la transformationcrop_pad() aux images de validation.
# Get transformations
tfms = get_transforms()# Create ImageDataBunch with transformations
data = ImageDataBunch.from_folder(path,ds_tfms=tfms,size=224)# Show a train batch
data.show_batch()