
Cyclical Learning Rates for Training Neural Networks
Learning rate is one of the most important hyper parameters when it comes to training a neural network. It determines the magnitude of weights (or parameters) updates. It is also the trickiest parameters to set because it can significantly impact model performance.
This blog post aims to provide readers an intuitive understanding of learning rate and a systematic method to find an optimal learning rate, which involves using a technique developed in the paper Cyclical Learning Rates for Training Neural Networks by Leslie Smith.
Find optimal starting learning rate
First, we need to select a “good” starting learning rate. If learning rate is set too low, training progress is inefficiently time-consuming due to small weights updates. If learning rate is set too high, it can lead to divergent behaviors in loss function.
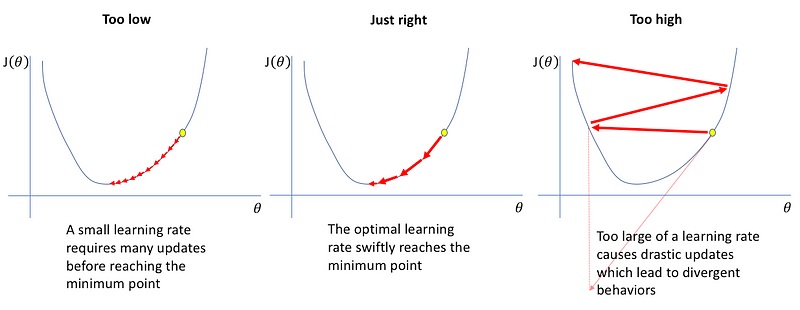
There is no universal optimal learning rate. Ideally, we want to set a learning rate which yields significant decreases in the loss function. A systematic approach in finding such learning rate is by observing the magnitudes of loss change with different learning rates. First, we need to gradually increase the learning rate either linearly (suggested by Leslie Smith) or exponentially (suggested by Jeremy Howard) as shown below,
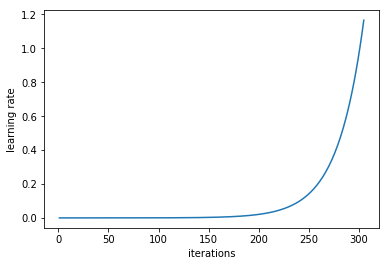
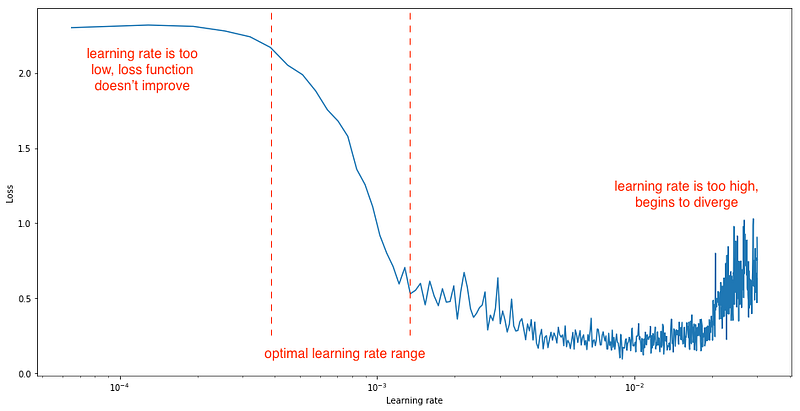
and after each mini batch, record the loss at each increment as shown below. The learning rate should be set within the range where the occurrence of loss decreases drastically.
Learning rate annealing
Selecting a good starting learning rate is merely the first step. In order to efficiently train a robust model, we will need to gradually decrease the learning rate during training. If learning rate remains unchanged during the course of training, it might be too large to converge and cause the loss function fluctuate around the local minimum. The approach is to use a higher learning rate to quickly reach the regions of (local) minima during the initial training stage, and set a smaller learning rate as training progresses in order to explore “deeper and more thoroughly” in the region to find the minimum.
There is an array of methods for learning rate annealing: step-wise annealing, exponential decay, cosine annealing(strongly suggest by Jeremy Howard), etc. More details on annealing learning rate at Stanford’s CS231 course website.
Cyclical Learning Rates
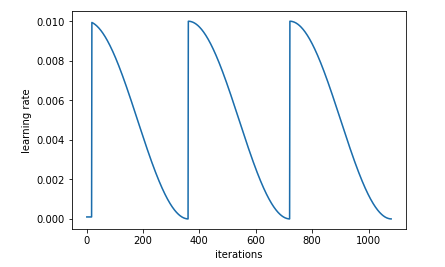
Cyclical Learning Rate is the main idea discussed in the paper Cyclical Learning Rates for Training Neural Networks. It is a recent variant of learning rate annealing. In the paper, Smith proposes a new idea to increase the learning rate from time to time. Below is an example of resetting learning rate for three evenly spaced intervals with cosine annealing.
The rationale is that increasing the learning rate will force the model to jump to a different part of the weight space if the current area is “spikey”. Below is a picture of three same minima with different opening width (or robustness).
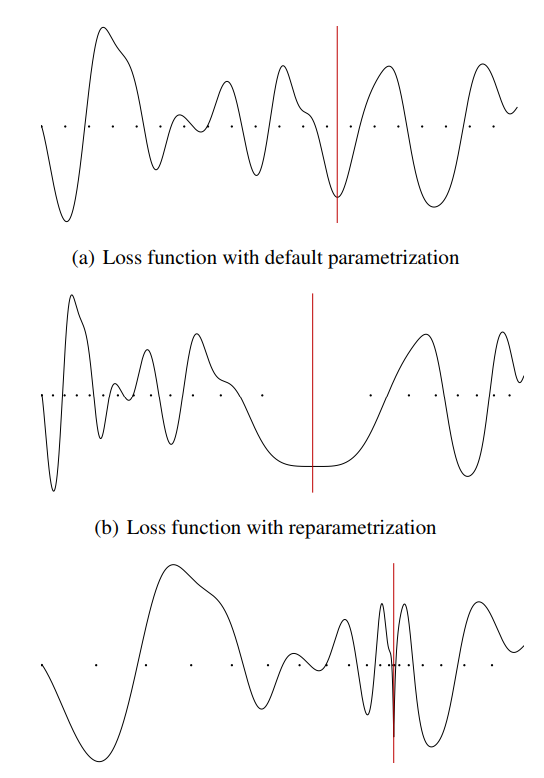
In other word, it will force to find another local minimum if the current minimum is not robust, and make the model generalize better to unseen data. Below is an illustration of cyclic LR schedule with three resets.
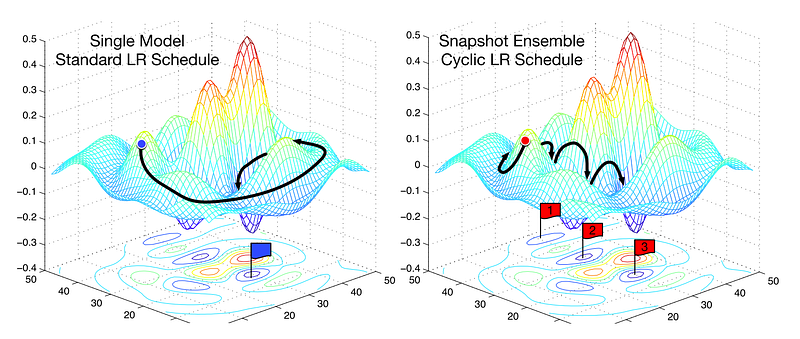
Smith also presents a number of experiments of a loss function evolution which, in short term, deviates to higher losses while, in long term, converging to a lower loss when compared with a benchmark fixed learning rate.





