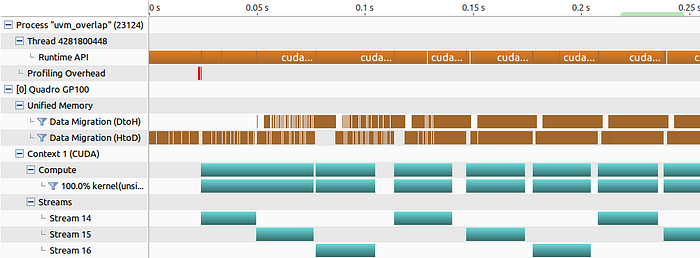
CUDA Pipeline — Prefetch and Poststore
Extract this part from https://readmedium.com/good-blogs-about-matmul-kernel-5e0de6413b57
This is a fun read from Scott’s https://github.com/NervanaSystems/maxas/wiki/SGEMM
The following is the prefetch code
readAs = ((tid >> 1) & 7) << 4;
readBs = (((tid & 0x30) >> 3) | (tid & 1)) << 4 + 2048;
while (track0 < end)
{
// Process each of our 8 lines from shared
for (j = 0; j < 8; j++)
{
// We fetch one line ahead while calculating the current line.
// Wrap the last line around to the first.
prefetch = (j + 1) % 8;
// Use even/odd rows to implement our double buffer.
if (j & 1)
{
ld.shared.v4.f32 j0Ax00, [readAs + 4*(prefetch*64 + 0)];
ld.shared.v4.f32 j0By00, [readBs + 4*(prefetch*64 + 0)];
ld.shared.v4.f32 j0Ax32, [readAs + 4*(prefetch*64 + 32)];
ld.shared.v4.f32 j0By32, [readBs + 4*(prefetch*64 + 32)];
}
else
{
ld.shared.v4.f32 j1Ax00, [readAs + 4*(prefetch*64 + 0)];
ld.shared.v4.f32 j1By00, [readBs + 4*(prefetch*64 + 0)];
ld.shared.v4.f32 j1Ax32, [readAs + 4*(prefetch*64 + 32)];
ld.shared.v4.f32 j1By32, [readBs + 4*(prefetch*64 + 32)];
}
}
// swap our shared memory buffers after reading out 8 lines
readAs ^= 4*16*64;
readBs ^= 4*16*64;
// Additional loop code omitted for clarity.
}There are two-way prefetch, usually I call the DtoH part “post-store” (from accelerator standpoint). The following is the one-way prefetch from the blog
for (int i = 0; i < num_tiles; i++) { // offload previous tile to the cpu if (i > 0)
cudaMemPrefetchAsync(a + tile_size * (i-1), tile_size * sizeof(size_t),
cudaCpuDeviceId, s1); // run multiple kernels on current tile
for (int j = 0; j < num_kernels; j++)
kernel<<<1024, 1024, 0, s2>>>(tile_size, a + tile_size * i); // prefetch next tile to the gpu
if (i < num_tiles)
cudaMemPrefetchAsync(a + tile_size * (i+1), tile_size * sizeof(size_t),
0, s3); // sync all streams
cudaDeviceSynchronize();
}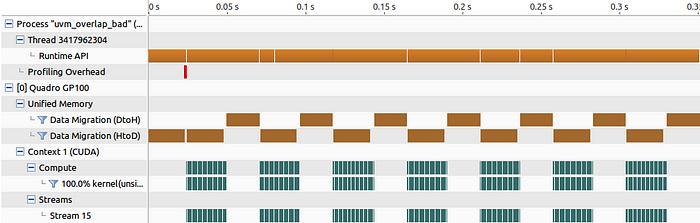
you see the blocking DtoH. to unlock this
for (int i = 0; i < num_tiles; i++) {
// make sure previous kernel and current tile copy both completed
cudaEventSynchronize(e1);
cudaEventSynchronize(e2); // run multiple kernels on current tile
for (int j = 0; j < num_kernels; j++)
kernel<<<1024, 1024, 0, s1>>>(tile_size, a + tile_size * i);
cudaEventRecord(e1, s1); // prefetch next tile to the gpu in a separate stream
if (i < num_tiles-1) {
// make sure the stream is idle to force non-deferred HtoD prefetches first
cudaStreamSynchronize(s2);
cudaMemPrefetchAsync(a + tile_size * (i+1),
tile_size * sizeof(size_t),
0, s2);
cudaEventRecord(e2, s2);
} // offload current tile to the cpu after the kernel is completed using the deferred path
cudaMemPrefetchAsync(a + tile_size * i, tile_size * sizeof(size_t),
cudaCpuDeviceId, s1); // rotate streams and swap events
st = s1; s1 = s2; s2 = st;
st = s2; s2 = s3; s3 = st;
et = e1; e1 = e2; e2 = et;
}