
Cryptocurrency Predictions Using Machine Learning: Some New Toys and Ideas We Have Been Playing With
Some explanation about the role of AutoML and representation learning in predictive models for crypto-assets.
In a recent webinar, I explored some of the most ambitious ideas we are exploring in our journey of creating predictive models for crypto assets at IntoTheBlock. In general, we regularly evaluate modern deep learning ideas pioneered by large tech companies such as Microsoft, Google, Uber, Amazon and many others and apply those to create models that forecast the price of different crypto-assets. We believe that this type of deep learning models have the best opportunity to discover alpha in crypto-assets is going in the long-run.
Obviously, most of the things we try fails but we continue making incremental improvements and creating more efficient predictive models. Today, I would like to share two new ideas that we have adopted with decent success.
The Challenges
Among the many challenges of creating predictive models for crypto-assets, there are two that are particularly painful:
1. Model Selection: Which machine learning models to use? Data scientists spend a lot of time deciding which are the best machine learning models for a given predictive problems.
2. Feature Extraction: Which features or predictors to discover? The process of extracting and selecting features for predictive models can result incredibly expensive.
Lately we have been doubling down on a couple of ideas to address these challenges.
AutoML: Our Solution for Model Selection
Automated machine learning or AutoML is this modern method that enables the evaluation of a large number of models for a given problem. Let’s use an example. Imagine that we are trying to predict the price of Bitcoin using orderbooks datasets for the next hour. Instead of deciding which machine learning architecture to use, AutoML will simply evaluate hundreds of them and outputs some results. AutoML stacks are new and relatively limited so its unlikely that they will produce a predictive model that just works. However, the process of testing hundreds of hypotheses quickly accelerates our experimentation time and its great for discarding things that don’t work quickly.
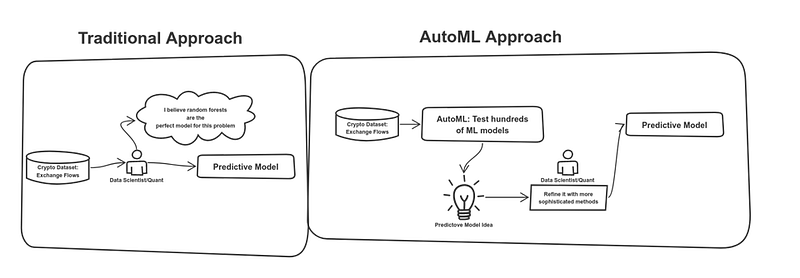
· What AutoML technologies do we like? In the current market, we think AutoML stacks such as Azure ML seem a bit ahead of the competition. More ambitious efforts such as AWS Research AutoGluon look incredibly promising.
Representation Learning: Our Solution to Feature Extraction/Selection
Representation learning is a machine learning discipline focused on learning features from a given dataset. Let’s continue with our example of predicting the price of Bitcoin in the next hour using an orderbook dataset. In a typical process, domain experts will argue whether metrics such as the spread or volume are effective predictors of price. However, there are hundreds of thousands of statistical computations in a dataset that can yield potential predictors and most of them are not trivial to the human eye. A representation learning approach will take our order book dataset and generate a large number of potential features ranging from simple averages to complex statistical functions, evaluate their importance and select the most effective ones.
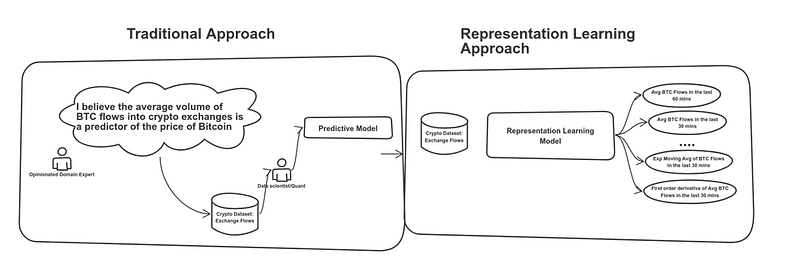
· What representation learning technologies we like? From the stacks in the market, we have become quite addicted to using tsfresh. Its incredibly simple and integrates well with most mainstream machine learning frameworks.
These are some of the new ideas we have been playing with at IntoTheBlock. More about this topic in a future post.





