
Criando um Data Pipeline do Zero
Um projeto iniciante de Engenharia de Dados, ponta-a-ponta.

Introdução
Engenharia de Dados sempre foi uma área de meu interesse, mas nunca tive tempo de criar um projeto porque preciso me dividir entre muitas coisas como trabalho, família e tudo mais que precisa do meu tempo e atenção. Então, me propus um grande desafio: criar um pipeline de dados do zero em apenas dois dias.
Nossa! — isso parece muito. Mas também parece factível.
Com apenas uma ideia em mente e mais experiência em navegar na área de Ciência de Dados do que em Engenharia de Dados, eu sabia que seria difícil, mas ainda assim: desafio aceito.
Então, neste post, abordaremos o seguinte projeto (GitHub):
Criar um pipeline de dados que:
(1) Obtém conjuntos de dados financeiros de ações de telecomunicações, indicadores econômicos e um índice Dow Jones para o setor de telecomunicações (Telco);
(2) Dar tratamento inicial para validar os dados;
(3) Limpar e organizar os dados;
(4) Prepará-lo para consumo de analistas e clientes em banco de dados PostgreSQL; e
(5) Apresenta um relatório do Power BI como resultado com alguns insights.
Vamos mergulhar no projeto.
Architecture
Este projeto foi pensado para ser processado na Databricks medallion lakehouse architecture, onde os dados são ingeridos para uma camada Raw (crua) inicial e, à medida que passam por mais refinamentos, passam para uma camada mais valiosa ( Raw > Bronze > Silver > Gold ).
O projeto, portanto, segue esta arquitetura mostrada na próxima figura.
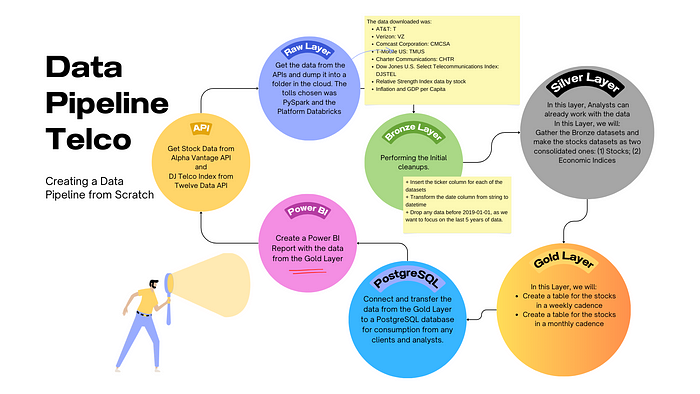
A arquitetura é basicamente:
Buscar dados de APIs >> Despejá-los na nuvem (pasta Databricks) >> Começar a limpar os dados, transformando de json em data frame, corrigindo tipos de dados, descartando observações indesejadas >> Reunir os diferentes datasets em um único conjunto de dados, juntando e calculando alguns indicadores como médias móveis e Índice de Força Relativa (RSI) >> Enviar os dados para um banco de dados PostgreSQL para consumo >> Conexão com Power BI e criação de um relatório final para insights.
Isso é muita informação de uma vez só. Portanto, vamos repassar o que está acontecendo nas próximas seções abaixo, explicando passo a passo cada peça desse quebra-cabeças.
Camadas e Passos
Agora, explicaremos como foram realizadas cada uma das etapas do projeto.
Ingestão de Dados e Camada Raw
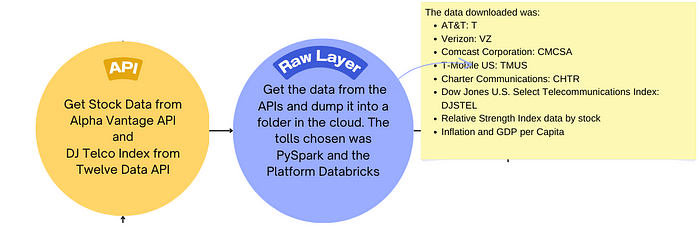
Todo projeto relacionado a dados começa com, bem… dados.
Portanto, a primeira etapa é a ingestão de dados. Decidi trabalhar com o setor de telecomunicações, então queria buscar dados financeiros de empresas de telecomunicações para poder fornecer aos analistas de dados e clientes uma boa fonte para comparar essas empresas ao final do projeto.
Assim, o desafio inicial foi obter dados do mercado de ações das empresas AT&T, T-Mobile, Comcast, Verizon e Charter Communications, além de um índice Dow Jones para o setor de telecomunicações.
Para isso, podemos utilizar o módulo Python requests para fazer solicitações para obter informações de uma API. A requisição é feita por uma função que recebe a URL, busca um arquivo json e transforma, limpa os metadados e transforma o resultado em um objeto data frame. A seguir, está uma das funções utilizadas.
Novamente, o código completo está no meu GitHub, neste repositório.
def get_data(ticker, size='compact', API_KEY = API_KEY):
'''
Function to get the stock daily historic data for a ticker from the Alpha Vantage API
Inputs:
* Ticker = Stock code: str
* size = 'full' for 20 years of historic data or 'compact' for the last 100 data points: str
Returns:
Data frame with the stock historic data
'''
# Get Data from Alpha Vantage Open API
url = f'https://www.alphavantage.co/query?function=TIME_SERIES_DAILY&symbol={ticker}&outputsize={size}&apikey={API_KEY}'
r = requests.get(url)
# Get only the json file output
data = r.json()
# Get only the time series, discarding the meta attribute
dtf = data['Time Series (Daily)']
# Transform JSON data into a list of Row objects
rows = [Row(date=key, **{k: float(v) if k != '5. volume' else int(v) for k, v in value.items()}) for key, value in dtf.items()]
# Define the schema for the DataFrame
schema = StructType([
StructField("date", StringType(), True),
StructField("open", DoubleType(), True),
StructField("high", DoubleType(), True),
StructField("low", DoubleType(), True),
StructField("close", DoubleType(), True),
StructField("volume", IntegerType(), True)
])
# Create a DataFrame
df = spark.createDataFrame(rows, schema)
return dfCamada Bronze
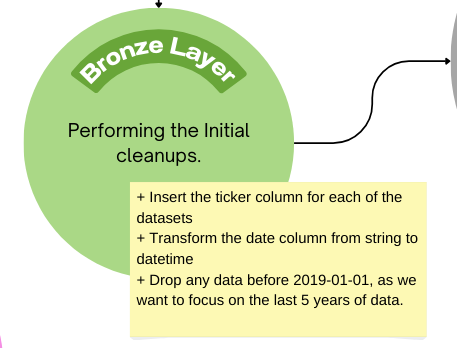
Uma vez obtidos os dados, o próximo passo na arquitetura é a Camada Bronze. Aqui, começamos a transformar e limpar os conjuntos de dados. Cada dado do mercado de ações e indicadores econômicos foram transferidos para pastas separadas em nossa casa do data lake como um arquivo json.
Os conjuntos de dados vêm da API com metadados que precisam ser limpos e também devem se tornar uma versão mais amigável para análise de dados, como um objeto de data frame.
Como os data frames não possuem o identificador da ação ou do indicador (também chamado de ticker), houve a necessidade de adicionar uma coluna com essa informação a cada data frame. Para facilitar nosso trabalho e tornar esse projeto algo replicável e escalável, podemos criar funções para ajudar a pavimentar o caminho. A função transform_data() pega o conjunto de dados e adiciona o ticker a ele, bem como transforma a coluna de data de string em um objeto datetime, de modo que a variável é aprimorada com recursos para extrair qualquer parte da data, como dia, mês, semana ou ano.
def transform_data(ticker):
'''
Function that (1) loads a dataset;
(2) adds a ticker column for the stock dataset;
(3) Transform the column to datetime;
(4) Drop data before 2019-01-01
Inputs:
* ticker: str = code to be added to all obervations
'''
# File path to be loaded
path = f'/FileStore/tables/raw/{ticker}'
# As the dataset for the ETF "DJUSTL" was pulled from a different API, it has the column date named as datetime. It needs to be corrected
if ticker == "DJUSTL":
df = (
spark.read.parquet(path)
.withColumn('ticker', F.lit(ticker))
.withColumnRenamed('datetime', 'date')
)
else:
# (2) Add ticker column
df = (
spark.read.parquet(path)
.withColumn('ticker', F.lit(ticker))
)
# Steps (3) and (4)
# If working with economic indices, adapt for less columns
if ticker in ['INFLATION', 'REAL_GDP_PER_CAPITA', 'CPI']:
df = (df
.select( 'ticker', 'value',
F.to_date('date').alias('date') )
.filter( col('date') >= '2019-01-01' ) #data cleanup, drop data before 2019
)
else:
df = (df
.select( 'ticker', 'open', 'high', 'low', 'close', 'volume',
F.to_date('date').alias('date') )
.filter( col('date') >= '2019-01-01' ) #data cleanup, drop data before 2019
)
# Return transformed data
return dfA próxima função criada — add_RSI() — pega o conjunto de dados transformado e adiciona o Índice de Força Relativa (RSI), que é um indicador de movimento comumente usado em análises técnicas de ações. Como esse indicador é recuperado da API Alpha Vantage separadamente dos dados de estoque, ele precisa ser associado aos conjuntos de dados.
def add_RSI(df, ticker):
'''Function to add RSI column to the stocks
inputs:
ticker: str = stock code'''
# File path to be loaded
path = f'/FileStore/tables/raw/RSI/{ticker}'
rsi = spark.read.parquet(path)
# Transform date to datetime format
rsi = (rsi
.select( F.to_date('date').alias('date'),
col('value').alias('RSI') )
.filter( col('date') >= '2019-01-01' ) #data cleanup, drop data before 2019
)
# Add RSI to the dataset
df = (df
.join(rsi, on='date', how= 'inner')
)
# Return transformed data
return dfPor fim, também estamos descartando quaisquer dados anteriores a 1º de janeiro de 2019, pois nosso foco para este projeto está nos últimos 5 anos. Esta etapa também é importante para simular um trabalho com Big Data.
Quando lidamos com uma grande quantidade de dados, movimentá-los e, posteriormente, analisá-los pode se tornar um problema. Portanto, focar em uma parte dos dados é uma das maneiras de escapar dessa armadilha e trabalhar com dados menores, mas ainda representativos.
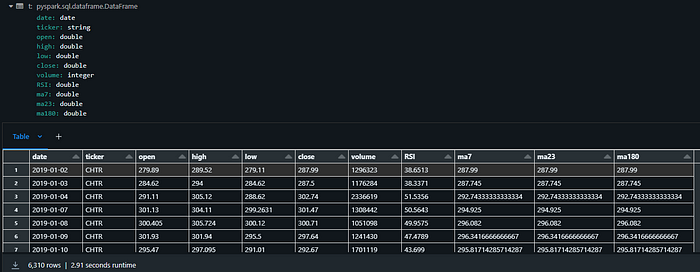
Aqui está uma figura que mostra como está a aparência dos dados até agora.
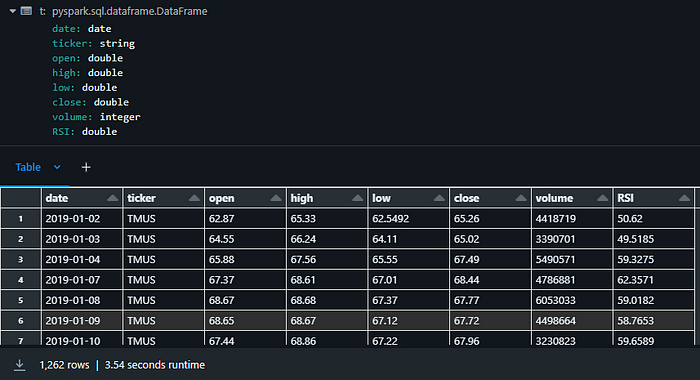
Camada Silver
Avançando em nossa arquitetura, o próximo passo é a camada Silver.
Aqui, os Analistas de Dados já podem ter acesso para começar a trabalhar com os conjuntos de dados, visto que já foram curados, passaram por uma primeira passagem de limpeza e tiveram os tipos de dados validados.
Nossa camada Silver é bastante simples: estamos obtendo vários conjuntos de dados limpos da camada Bronze e reunindo-os por similaridade. Ou seja, todos os dados do mercado de ações serão reunidos em um único conjunto de dados, os indicadores econômicos serão outro e o Índice Dow Jones também fará seu próprio conjunto de dados.
Além disso, estamos adicionando algumas médias móveis ao conjunto de dados de ações. As médias móveis são amplamente utilizadas quando se trata de trabalhar com dados de séries temporais porque suavizam os movimentos, trazendo à luz as tendências por trás deles.
Gold Layer
A camada Gold é a última deste lago e é onde os dados ficam prontos para consumo de qualquer cliente, sejam Analistas, Cientistas de Dados ou qualquer pessoa que precise consumir dados dessa fonte. Nesta camada podemos criar tabelas de forma mais agregada, exibindo métricas solicitadas pelo negócio, tabelas construídas seguindo regras de negócio ou qualquer outro conjunto de dados que esteja pronto para consumo. Nosso projeto possui duas tabelas criadas para esta camada:
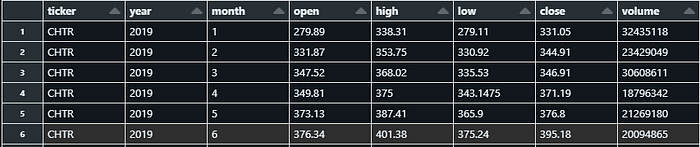
- Visualização mensal: conjunto de dados que traz dados de ações agregados por ação e por mês.
- Visualização semanal: conjunto de dados que traz dados de ações agregados por ação e por semana.
Conectandos com PostgreSQL

Muito bem. Agora que temos nosso data lakehouse pronto, é hora de disponibilizar os dados de outras formas para consumo. Em um ambiente real, muitas vezes o usuário final não técnico não terá acesso ao Databricks e ao próprio lakehouse, sabendo que é necessário mais habilidades para lidar com este ambiente.
Pensando nisso, foi criado um banco de dados PostgreSQL para disponibilizar os conjuntos de dados das camadas Gold e Silver para consultas utilizando uma ferramenta mais amigável, que é um banco de dados relacional para consultar os dados necessários.
Para instanciar um banco de dados PostgreSQL é fácil usando o site www.render.com. Com apenas alguns cliques temos uma instância pronta para receber novas tabelas.
A seguir, vamos conectar a camada Gold ao PostgreSQL. Podemos usar o módulo psycopg2 para fazer uma conexão com o servidor SQL, o que é bastante simples. Tudo o que precisamos é do endereço URL da conexão e fornecê-lo à função connect().
# Creating a connection
connection = psycopg2.connect(CONNECTION)
# Creating a cursor to execure SQL commands
cursor = connection.cursor()Então é hora de criar uma tabela em nosso banco de dados recém-instalado. Isso pode ser feito diretamente com uma ferramenta administradora de banco de dados, como PGAdmin ou DBeaver, ou pode ser feito via linguagem Python, utilizando o mesmo módulo psycopg2. Como estamos criando um pipeline de dados, acho que a última opção é a melhor.
O próximo trecho cria uma tabela no banco de dados SQL. Tudo o que precisamos fazer é fornecer um name para a tabela e um comando SQL para CREATE TABLE. A função irá abrir uma conexão com o banco de dados, criar um cursor para executar o comando SQL, enviá-lo ao banco de dados e fechar a conexão. Simples assim.
# Function to create table in PostgreSQL
def create_table(name, sql):
"This function opens a connection with PostgreSQL and creates
a table based on the sql command provided"
# Create a connection and cursor
conn = psycopg2.connect(CONNECTION)
cursor = conn.cursor()
# Execture SQL Commmands
cursor.execute(sql)
# Commit and close connection
conn.commit()
cursor.close()
conn.close()
return "Table created"
#----------------
# SQL command 1 for Monthly Data Table
sql = f'''
CREATE TABLE monthly (
ticker VARCHAR(255),
year INT,
month INT,
open DECIMAL(10,2),
high DECIMAL(10,2),
low DECIMAL(10,2),
close DECIMAL(10,2),
volume INT
);
'''
# Creating the table
create_table(name='monthly', sql= sql)Repetimos o processo quantas vezes forem necessárias para que as tabelas sejam criadas no banco de dados da Telco.
A seguir, precisamos de uma função para fazer inserção em massa na tabela. Para cada linha em um quadro de dados, iremos INSERT esses valores na tabela escolhida. Mas como nossa ferramenta preferida foi o PySpark no Databricks, o objeto data frame precisa ser transformado em uma lista de tuplas que serão inseridas na tabela SQL. Então aqui está uma função para fazer essa transformação. Fornecemos a ele um objeto de quadro de dados, então a função o converte em um objeto RDD, cria uma lista de tuplas e a retorna.
# Dataframe to list of tuples for SQL INSERT
def df_to_tuple(df):
"Convert a Spark dataframe to a list of tuples"
# convert dataframe to rdd
rdd = df.rdd
# convert rdd to tuple
to_tuple = rdd.map(tuple).collect()
return to_tupleFinalmente, a função de inserção em massa é a seguinte. Tem muita coisa aí, mas o resumo é que ele abre uma conexão, avalia o nome da tabela para poder inserir os valores de acordo com o comando SQL correto, insere as linhas, faz commit e fecha a conexão.
# Creating a function for bulk insertion in SQL PostgreSQL
def bulk_insert(table, records):
try:
# Create a connection to the database
connection = psycopg2.connect(CONNECTION)
cursor = connection.cursor()
if table == 'monthly':
sql_insert_query = f""" INSERT INTO {table} (ticker, year, month, open, high, low, close, volume)
VALUES (%s,%s,%s,%s,%s,%s,%s,%s) """
elif table == 'weekly':
sql_insert_query = f""" INSERT INTO {table} (ticker, year, week, open, high, low, close, volume)
VALUES (%s,%s,%s,%s,%s,%s,%s,%s) """
elif table == 'indicators':
sql_insert_query = f""" INSERT INTO {table} (indicator, value, date)
VALUES (%s,%s,%s) """
elif table == 'stocks':
sql_insert_query = f""" INSERT INTO {table} (date, ticker, open, high, low, close, volume, RSI, ma7, ma23, ma180)
VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) """
else:
sql_insert_query = f""" INSERT INTO {table} (date, ticker, open, high, low, close, volume, RSI)
VALUES (%s,%s,%s,%s,%s,%s,%s,%s) """
# executemany() to insert multiple rows
result = cursor.executemany(sql_insert_query, records)
connection.commit()
print(cursor.rowcount, "Record inserted successfully into mobile table")
except (Exception, psycopg2.Error) as error:
print(f"Failed inserting record into the table {error}")
finally:
# closing database connection.
if connection:
cursor.close()
connection.close()
print("PostgreSQL connection is closed")Segue uma imagem do banco de dados já preenchido.
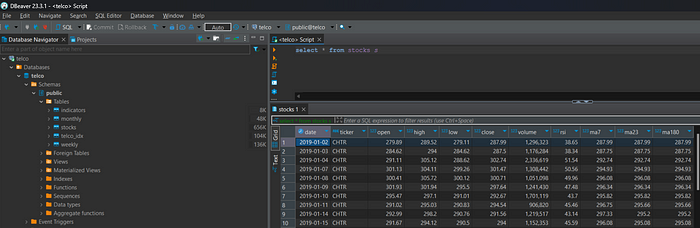
Agora podemos consumir esses dados. Por exemplo, podemos executar esta consulta para verificar o valor mais alto de 2023.
SELECT ticker, MAX(high) as high
FROM weekly
WHERE "year" = 2023
GROUP BY ticker
----------------------
CHTR 458.30
CMCSA 47.46
T 21.53
TMUS 161.19
VZ 42.58Ou esta outra consulta para verificar a progressão dos valores mais elevados da T-Mobile (TMUS) nos últimos 5 anos.
select ticker, year, MAX(high) as high
from weekly
where ticker = 'TMUS'
group by ticker, year
order by ticker, year
----------------------
TMUS 2019 85.22
TMUS 2020 135.00
TMUS 2021 150.20
TMUS 2022 154.38
TMUS 2023 161.19
TMUS 2024 164.50Ou ainda, se quisermos obter o menor valor de fechamento em 52 semanas a partir da data atual mais a informação de qual percentil ele se enquadra, podemos usar esta consulta.
-- Creating a temp view to calculate the percent rank over a window
create or replace view pct as SELECT ticker, close, "date",
percent_rank() OVER (PARTITION BY ticker ORDER BY close asc) as percentile_
FROM stocks
where ticker = 'TMUS';
-- Query the Lowest close in 52 weeks with percent rank
-- Select columns
SELECT s.ticker, s.close, s."date", p.percentile_
FROM stocks s
-- Join the pct view
join pct p on s.ticker = p.ticker and s."close" = p."close" and s."date" = p."date"
where s.ticker = 'TMUS'
-- Filter between today and 365 days in the past
and s."date" between current_date - 365 and current_date
-- Match date with the lowest value
and s.close =(
SELECT MIN(close)
FROM stocks s2
where ticker = 'TMUS'
and "date" between current_date - 365 and current_date
group by ticker )
;
--------------------------
TMUS 126.55 2023-06-07 0.5091Conectando com o Power BI

Por fim, a última parte deste projeto é criar um relatório do Power BI que possa ajudar os tomadores de decisão a extrair rapidamente insights desses dados, capacitando-os a tomar decisões baseadas em dados. Portanto, criamos uma conexão do PostgreSQL com o Power BI.
Isso tornará ainda mais fácil o consumo dos dados, sem a necessidade sequer de saber SQL. Com os dados no Power BI, qualquer cliente pode criar relatórios rapidamente e extrair insights com o estilo padrão de arrastar e soltar da Microsoft, e é por isso que esta última etapa é importante.
O painel final a ser apresentado aos usuários está a seguir.
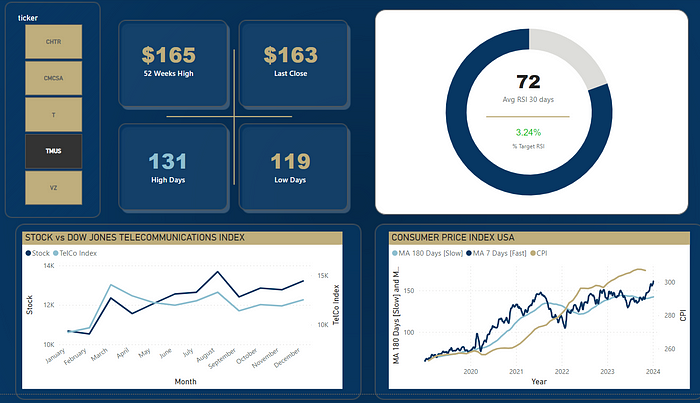
E, assim, chegamos ao final deste projeto.
Antes de você ir
Neste projeto, passamos por muita coisa. Foram muitos desafios a serem superados, mas o resultado final foi bom para um pequeno projeto de Engenharia de Dados.
Começamos com dados financeiros obtidos de APIs e armazenados na nuvem — em pastas Databricks. Em seguida validamos, transformamos e limpamos nossos dados na camada Bronze, preparando-os para a camada Silver, que serve para consolidar os conjuntos de dados. Em seguida os dados seguem para tratamento final e agregação de acordo com as necessidades do negócio na Camada Gold. Em seguida, ele passa no pipeline para um banco de dados PostgreSQL para consumo dos clientes e para uma conexão final com o Power BI, alimentando um relatório para os tomadores de decisão.
Obviamente, há muito mais que pode ser feito. Por exemplo, todo esse processo pode ser automatizado como um pipeline no Databricks, mas a edição Community gratuita não nos permite criar fluxos de trabalho (Workflow). Porém, todos os notebooks foram pensados em uma sequência lógica que nos permite criar um fluxo de trabalho que faria com que esse pipeline fosse atualizado com muita facilidade.
Outras melhorias podem ser feitas no código, para deixá-lo mais otimizado, mas como o prazo para construir todo esse projeto era apenas dois dias, acredito que esteja bom o suficiente por enquanto.
Foi divertido construir este projeto do zero. Com certeza aprendi muito e levarei esse conhecimento comigo em minha carreira.
GitHub Repository
Referências
Também usei conhecimentos do meu curso online PySpark. Confira e aprenda como transformar Big Data usando PySpark em Databricks.





