
Creating Word Embeddings: Coding the Word2Vec Algorithm in Python using Deep Learning
Understanding the intuition behind word embedding creation with deep learning
When I was writing another article that showcased how to use word embeddings in a text classification objective I realized that I always used pre-trained word embeddings downloaded from an external source (for example https://nlp.stanford.edu/projects/glove/). I started thinking about how to create word embeddings from scratch and thus this is how this article was born. My main goal is for people to read this article with my code snippets and to get an in-depth understanding of the logic behind the creation of vector representations of words.
The whole code can be found here:
https://github.com/Eligijus112/word-embedding-creation
The short version of the creation of the word embeddings can be summarized in the following pipeline:
Read the text -> Preprocess text -> Create (x, y) data points -> Create one hot encoded (X, Y) matrices -> train a neural network -> extract the weights from the input layer
In this article, I will briefly explain every step of the way.
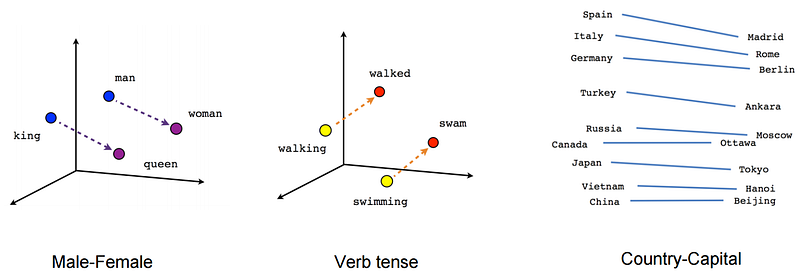
From wiki: Word embedding is the collective name for a set of language modeling and feature learning techniques in natural language processing (NLP) where words or phrases from the vocabulary are mapped to vectors of real numbers. The term word2vec literally translates to word to vector. For example,
“dad” = [0.1548, 0.4848, …, 1.864]
“mom” = [0.8785, 0.8974, …, 2.794]
The most important feature of word embeddings is that similar words in a semantic sense have a smaller distance (either Euclidean, cosine or other) between them than words that have no semantic relationship. For example, words like “mom” and “dad” should be closer together than the words “mom” and “ketchup” or “dad” and “butter”.
Word embeddings are created using a neural network with one input layer, one hidden layer and one output layer.

To create word embeddings the first thing that is needed is text. Let us create a simple example stating some well-known facts about a fictional royal family containing 12 sentences:
The future king is the princeDaughter is the princessSon is the princeOnly a man can be a kingOnly a woman can be a queenThe princess will be a queenQueen and king rule the realmThe prince is a strong manThe princess is a beautiful womanThe royal family is the king and queen and their childrenPrince is only a boy nowA boy will be a manThe computer does not understand that the words king, prince and man are closer together in a semantic sense than the words queen, princess, and daughter. All it sees are encoded characters to binary. So how do we make the computer understand the relationship between certain words? By creating X and Y matrices and using a neural network.
When creating the training matrices for word embeddings one of the hyperparameters is the window size of the context (w). The minimum value for this is 1 because without context the algorithm cannot work. Lets us take the first sentence and lets us assume that w = 2.
The future king is the princeThe bolded word the is called the focus word and 2 words to the left and 2 words to the right (because w = 2) are the so-called context words. So we can start building our data points:
(The, future), (The, king)Now if we scan the whole sentence we would get:
(The, future), (The, king),
(future, the), (future, king), (future, is)
(king, the), (king, future), (king, is), (king, the)
(is, future), (is, king), (is, the), (is, prince),
(the, king), (the, is), (the, prince)
(prince, is), (prince, the)From 6 words we are able to create 18 data points. In practice, we do some preprocessing of the text and remove stop words like is, the, a, etc. By scanning our whole text document and appending the data we create the initial input which we can then transform into a matrix form.
The full pipeline to create the (X, Y) word pairs given a list of strings texts:
The first entries of the created data points:
['future', 'king'],
['future', 'prince'],
['king', 'prince'],
['king', 'future'],
['prince', 'king'],
['prince', 'future'],
['daughter', 'princess'],
['princess', 'daughter'],
['son', 'prince']
...After the initial creation of the data points, we need to assign a unique integer (often called index) to each unique word of our vocabulary. This will be used further on when creating one-hot encoded vectors.
After using the above function on the text we get the dictionary:
unique_word_dict = {
'beautiful': 0,
'boy': 1,
'can': 2,
'children': 3,
'daughter': 4,
'family': 5,
'future': 6,
'king': 7,
'man': 8,
'now': 9,
'only': 10,
'prince': 11,
'princess': 12,
'queen': 13,
'realm': 14,
'royal': 15,
'rule': 16,
'son': 17,
'strong': 18,
'their': 19,
'woman': 20
}What we created up to this point is still not neural network friendly because what we have as data is the pairs of (focus word, context word). In order for the computer to start doing computations, we need a clever way to transform these data points into data points made up of numbers. One such clever way is the one-hot encoding technique.
One-hot encoding transforms a word into a vector that is made up of 0 with one coordinate, representing the string, equal to 1. The vector size is equal to the number of unique words in a document. For example, lets us define a simple list of strings:
a = ['blue', 'sky', 'blue', 'car']There are 3 unique words: blue, sky and car. One hot representation for each word:
'blue' = [1, 0, 0]
'car' = [0, 1, 0]
'sky' = [0, 0, 1]Thus the list can be converted into a matrix:
A =
[
1, 0, 0
0, 0, 1
1, 0, 0
0, 1, 0
]We will be creating two matrices, X and Y, with the exact same technique. The X matrix will be created using the focus words and the Y matrix will be created using the context words.
Recall the first three data points which we created given the texts about royalties:
['future', 'king'],
['future', 'prince'],
['king', 'prince']The one-hot encoded X matrix (words future, future, king) in python would be:
[array([0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.]),
array([0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.]),
array([0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.])]The one-hot encoded Y matrix (words king, prince, prince) in python would be:
[array([0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.]),
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.,
0., 0., 0., 0.]),
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.,
0., 0., 0., 0.])]The final sizes of these matrices will be n x m, where
n - number of created data points (pairs of focus words and context words)
m - number of unique words
We now have X and Y matrices built from the focus word and context word pairs. The next step is to choose the embedding dimension. I will choose the dimension to be equal to 2 in order to later plot the words and see whether similar words form clusters.
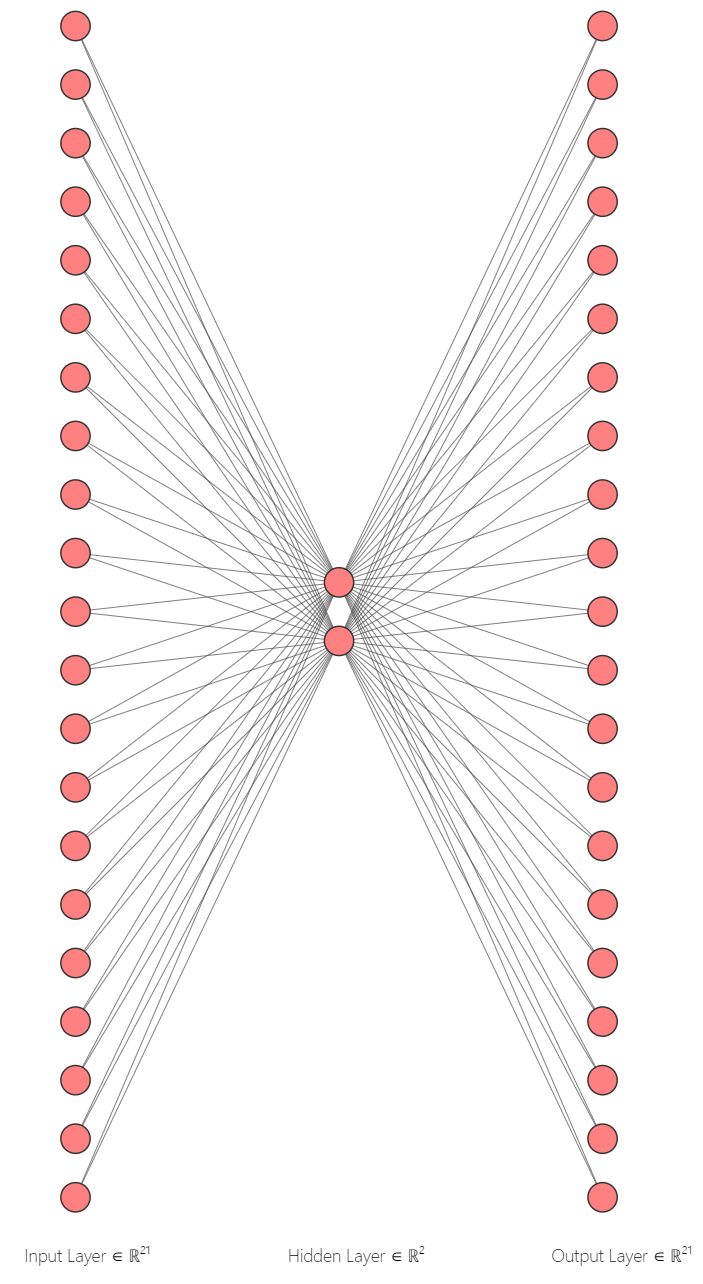
The hidden layer dimension is the size of our word embedding. The output layers activation function is softmax. The activation function of the hidden layer is linear. The input dimension is equal to the total number of unique words (remember, our X matrix is of the dimension n x 21). Each input node will have two weights connecting it to the hidden layer. These weights are the word embeddings! After the training of the network, we extract these weights and remove all the rest. We do not necessarily care about the output.
For the training of the network, we will use keras and tensorflow:
After the training of the network, we can obtain the weights and plot the results:
import matplotlib.pyplot as pltplt.figure(figsize=(10, 10))for word in list(unique_word_dict.keys()):
coord = embedding_dict.get(word)
plt.scatter(coord[0], coord[1])
plt.annotate(word, (coord[0], coord[1]))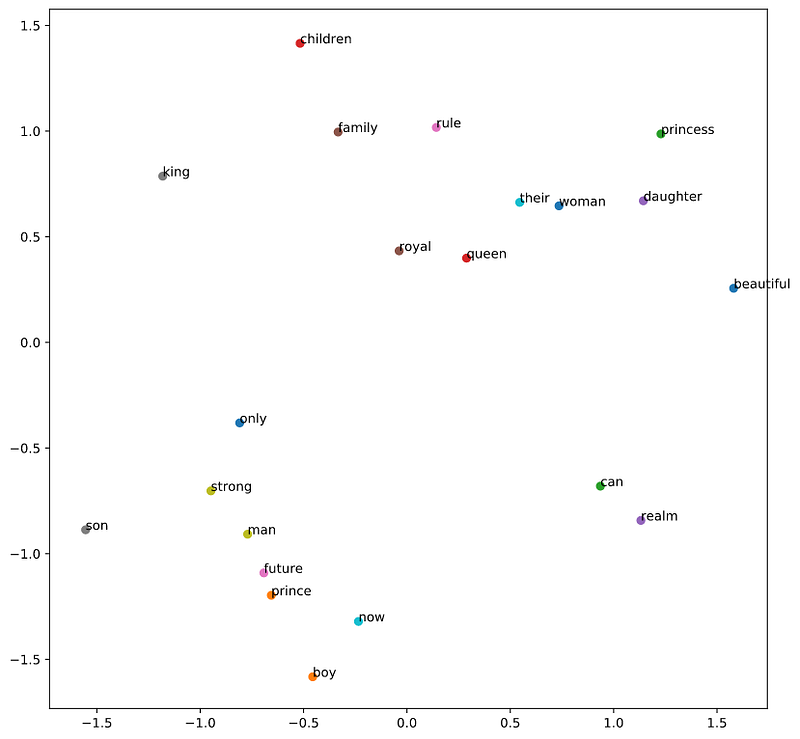
As we can see, there are the words ‘man’, ‘future’, ‘prince’, ‘boy’ and ‘daughter’, ‘woman’, ‘princess’ in separate corners of the plot and form clusters. All this was achieved from just 21 unique words and 12 sentences.
Often in practice, pre-trained word embeddings are used with typical word embedding dimensions being either 100, 200 or 300. I personally use the embeddings stored here: \https://nlp.stanford.edu/projects/glove/.




