
Creating Mo-Cap Facial Animations of Virtual Characters with Deep Learning
Overview of the paper “First Order Motion Model for Image Animation” and exploring it’s application to the Game Animation Industry.
Motion Capture (Mo-Cap, for short) is the process of recording with camera real-life movements of people for the purpose of recreating those exact movements in a computer generated scene. As someone who is fascinated by the use of this tech in game development for creating animations, I was thrilled to see the massive improvements brought to this tech with the help of Deep Learning.
In this article, I want to share a quick overview of the recently published NeurIPS paper “First Order Motion Model for Image Animation” by A. Siarohin et. al. and demonstrate how its application to the Game Animation Industry will be “game-changing”.
MotionScan Technology
It was way back in 2011 when the game L.A. Noire came out with absolutely amazing life-like facial animations that seemed so ahead of every other game. Now, almost a decade later, we still haven’t seen many other games come anywhere close to matching its level in terms of delivering realistic facial expressions.



This is because the facial scanning technology used in the development of this game, called MotionScan, was extremely expensive and the file sizes of the captured animations was too big, which is why it made it impractical for most publishers to adopt this technology for their games.
However, this might change very soon thanks to the recent advancements in motion capture driven by Deep Learning.
First Order Motion Model for Image Animation

In this research work, the authors present a Deep Learning Framework to create animations from a source image of a face, by following the motion of another face in a driving video, similar to the MotionScan technology. They propose a self-supervised training method that can use unlabeled data-set of videos of a particular category to learn the important dynamics that define motion. Then, then show how these motion dynamics can be combined with a static image to generate a motion video.
Framework (Model Architecture)
Let’s take a look at the architecture of this Deep Learning Framework in the figure below. It consists of a Motion Module and an Appearance Module. The driving video is the input to the Motion Module and the Source Image is our target object which is the input to the Appearance Module.
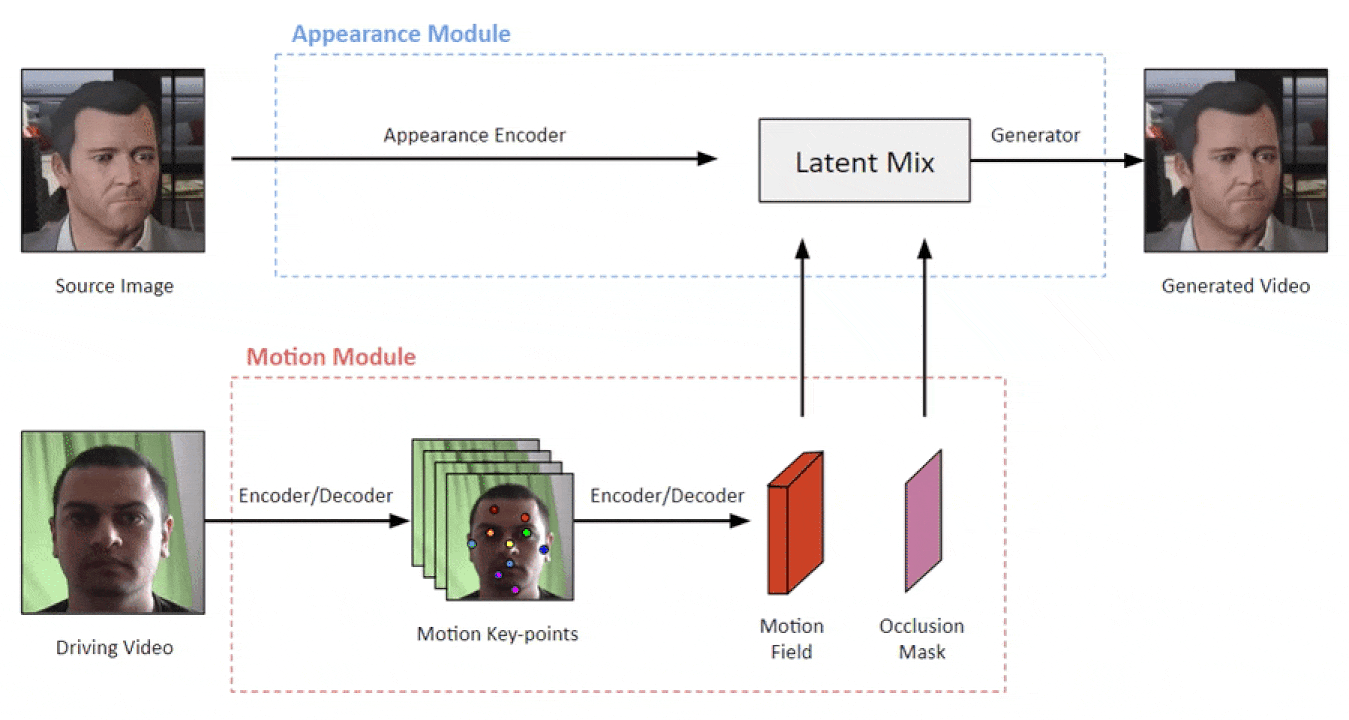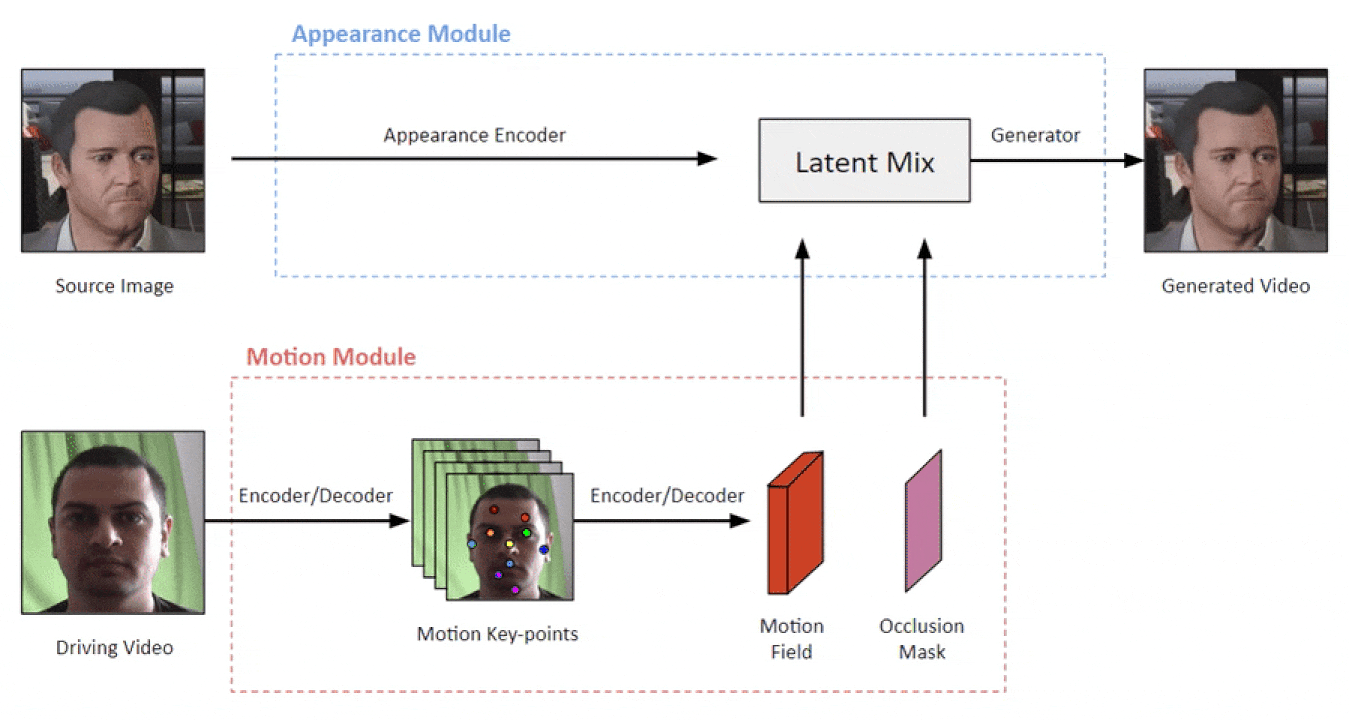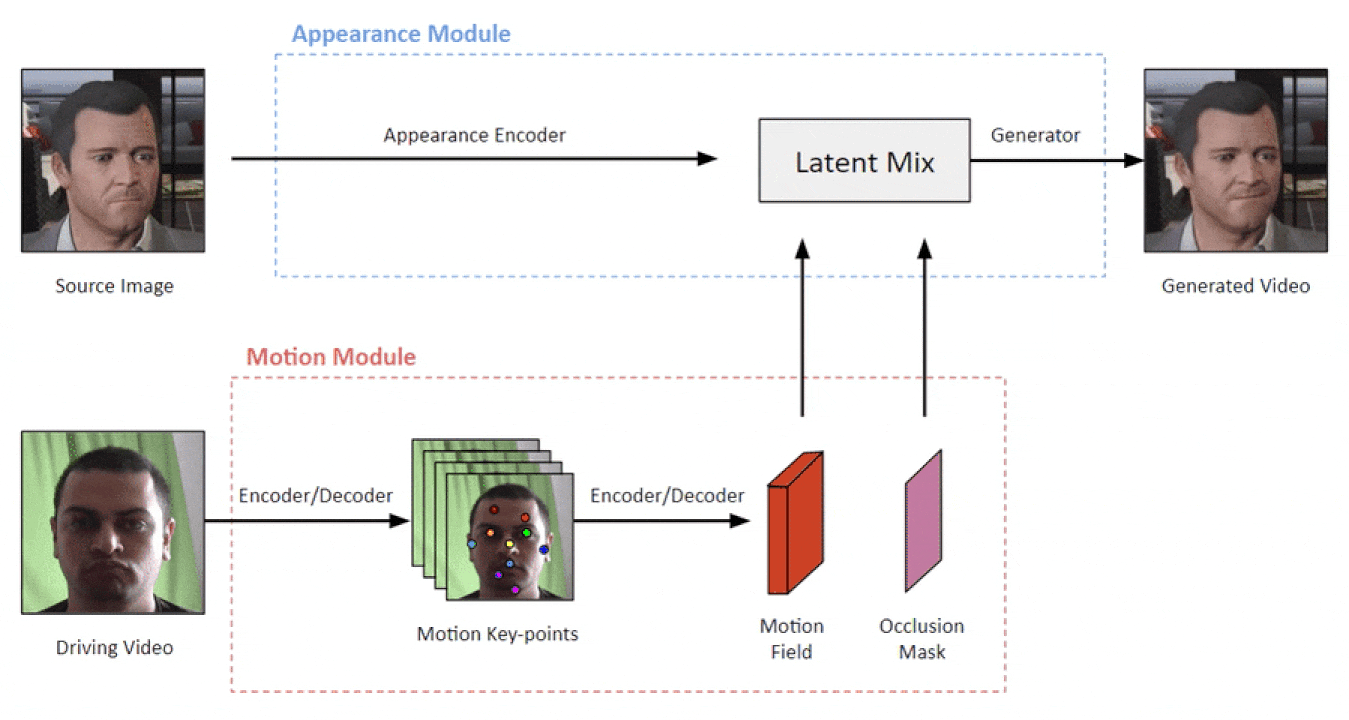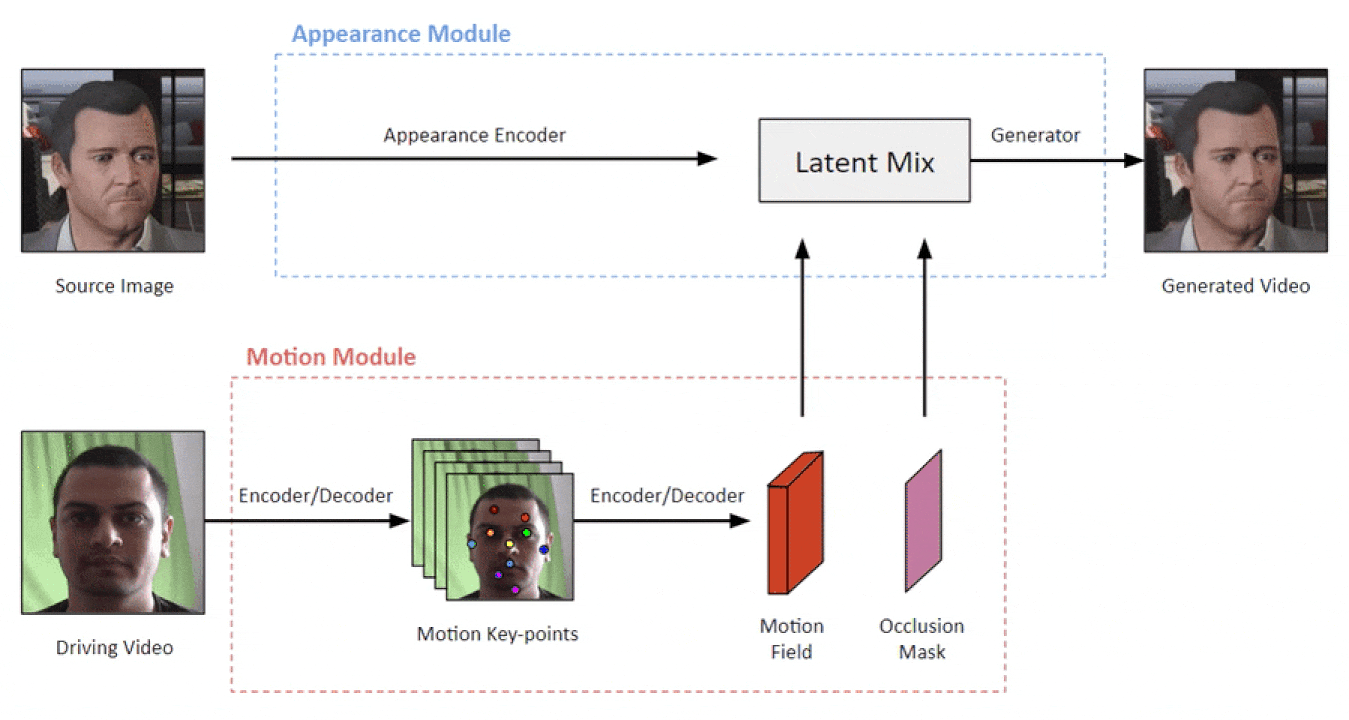
Motion Module
The Motion Module consists of an encoder that learns a latent representation containing sparse keypoints of high importance in relation to the motion of the object, which is a face in this scenario. The movement of these keypoints across the different frames of the driving video generate a motion field, which is driven by a function that we want our model to learn. The authors use Taylor Expansion to approximate this function to the first order that creates this motion field. According to the authors, this is the first time first order approximation has been used to model motion. Moreover, learned affine transformations of these keypoints are combined to produce Dense Motion Field. The dense motion field predicts the motion of every individual pixel of the frame, as opposed to focusing on just the keypoints in the sparse motion field. Next, the motion module also produces an Occlusion Map, which highlights the pixels of the frame that need to be in-painted, arising from the movements of the head w.r.t. the background.
Appearance Module
The Appearance Module uses an encoder to encode the source image, which is then combined with the Motion Field and the Occlusion Map to animate the source image. A Generator model is used for this purpose. During the self-supervised training process, a still frame from the driving video is used as the source image and the learned motion field is used to animate this source image. The actual frames of the video act as the ground truth for the generated motion, hence it is self-supervised training. During the testing/inference phase, this source image can be replaced with any other image from the same object category, and doesn’t have to arrive from the driving video.
Running the Trained Model on Game Characters
I wanted to explore how well this model works on some virtually designed faces of game characters. The authors have shared its code and an easy-to-use Google Colab notebook to test this out. Here’s how their trained model looks when tested on different characters from the game Grand Theft Auto.

As you can see, it is extremely easy to create life-like animations with this AI, and I think it will be used by almost every game artist for creating facial animations in games. Moreover, in order to perform Mo-Cap with this technique, all we need now is one camera and any average computer with a GPU and this AI will take care of the rest, making it extremely cheap and feasible for game animators to use this tech on a large scale. This is why I’m excited about the massive improvements that can be brought by this AI in the development of future games.
Useful Links:-
Thank you for reading. If you liked this article, you may follow more of my work on Medium, GitHub, or subscribe to my YouTube channel.




