CountVectorizer vs TfidfVectorizer
Introduction to Text Feature Extraction
Machine learning models such as linear regression, logistic regression, and k-nearest neighbours take in an X and a y variable.
Xis a matrix/dataframe of real numbers.yis a vector/series of real numbers.
Text data is not already organised as a matrix or vector of real numbers. We say that this data is unstructured.
- A collection of text is a document. Think of a document as a row in your feature matrix.
- A collection of documents is a corpus. Think of the full dataframe as a corpus.
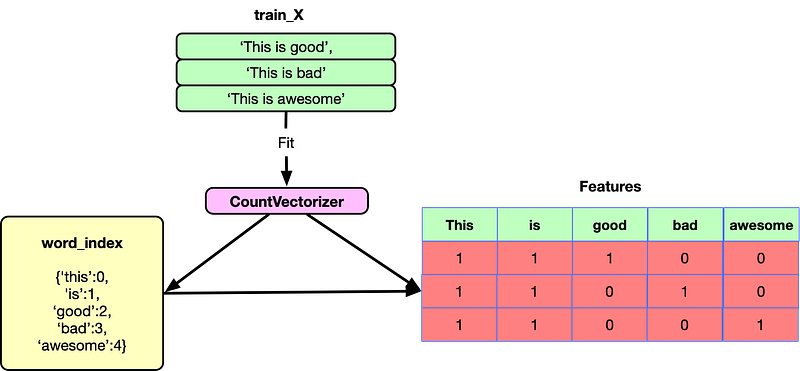
1. CountVectorizer
CountVectorizer converts text into fixed-length vectors by counting how many times each word appears. The tokens are now stored as a bag-of-words.
Limitations:
- Unable to identify words that are more or less significant for analysis
- It will just consider words that are abundant in a corpus as the most statistically significant word
- Does not take linguistic similarity between words into account
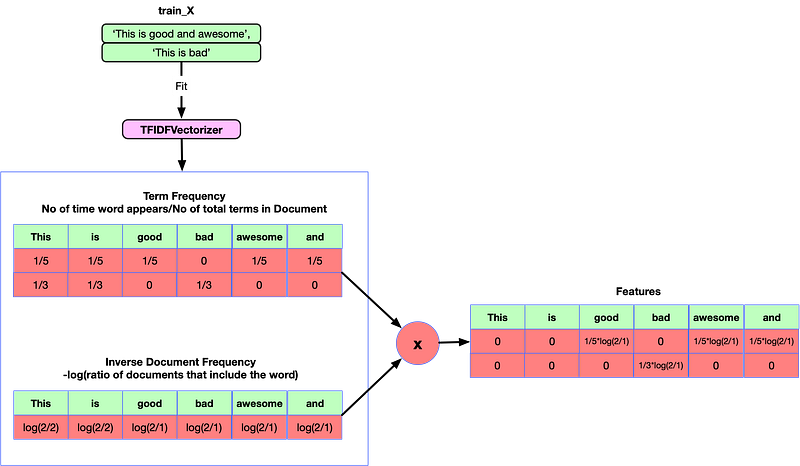
2. TfidVectorizer
Tfidf works better than CountVectorizer as it also takes the importance of a words into account account.
Formula → The tf-idf weight is composed by two terms: the first computes the normalized Term Frequency (TF) which refers to the the number of times a word appears in a document divided by the total number of words in that document. The second term is the Inverse Document Frequency (IDF) which is calculated as the logarithm of the number of the documents in the corpus divided by the number of documents where the specific term appears.
- TF: Term Frequency measures how frequently a term occurs in a document. As every document is different in length, it is possible that a term would appear much more times in long documents than shorter ones. Hence, the term frequency is often divided by the document length to normalise the data → TF(t) = (Number of times term x appears in a document) / (Total number of terms in the document).
- IDF: Inverse Document Frequency measures the significance of a word. In calculating TF, all terms are considered equally significant. However it is known that certain terms, such as “and”, “the” may appear a lot of times but have little importance. Therefore, we need to weigh down the frequent terms while scale up the rare ones → IDF(t) = log_e(Total number of documents / Number of documents with term x in it).
Limitations:
- It computes document similarity directly in the word-count space, which could be slow for larger vocabularies
- It assumes that the counts of different words provide independent evidence of similarity
- It makes no use of semantic similarities between words