
Converting nested JSON structures to Pandas DataFrames
The Problem
APIs and document databases sometimes return nested JSON objects and you’re trying to promote some of those nested keys into column headers but loading the data into pandas gives you something like this:
df = pd.DataFrame.from_records(results["issues"], columns=["key", "fields"])
The problem is that the API returned a nested JSON structure and the keys that we care about are at different levels in the object.
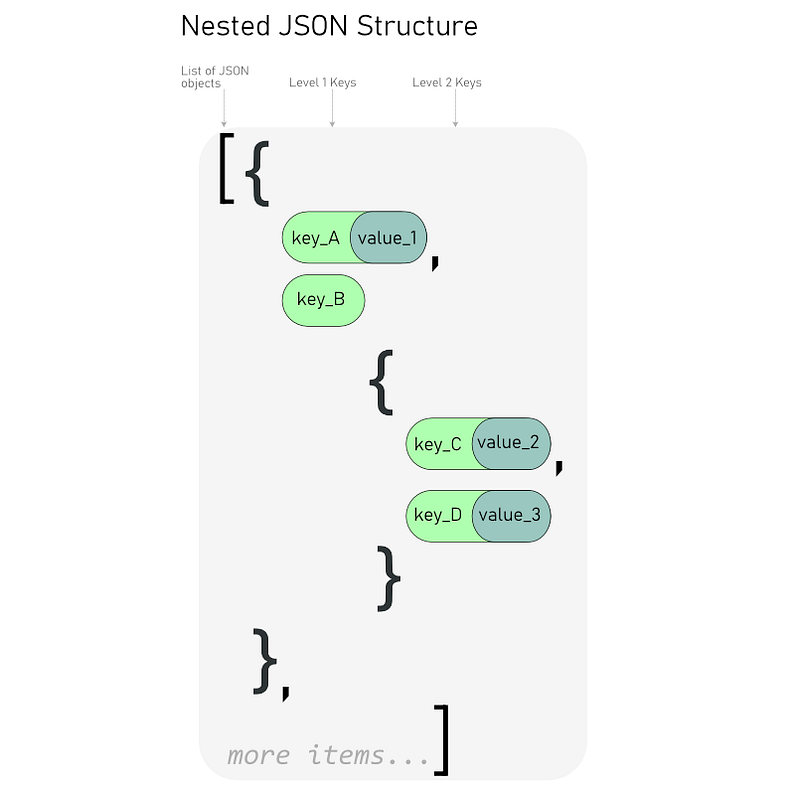
What we want is this:
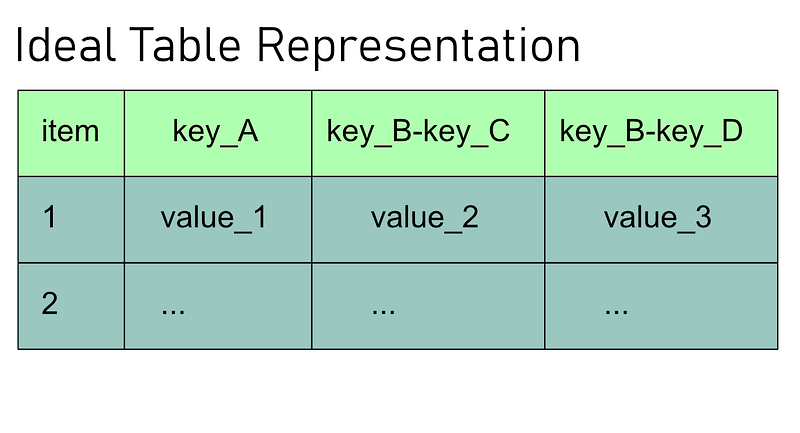
An example
We’re going to use data returned from the Jira API as an example. The Jira API often includes metadata about fields. Let’s say these are the fields we care about
- key: Within the list of issue records this is a top-level JSON key so no problem pulling it into its own column.
- summary: This is at the second level, inside the “fields” object.
- status name: What we care about is the name of the status but it also includes fields for the status description, status id, etc. This is at the 3rd level.
- issuetype: Again, what we care about here is the name not any of the metadata.
- statusCategory name: This is actually a sub-object included in the status field for each issue returned by the API. What we care about is the name of the statusCategory, which is at the 4th nested level.
Example of data returned by the Jira API. Note that the fields we want to extract (bolded) are at 4 different levels in the JSON structure inside the
issueslist.
{
"expand": "schema,names",
"issues": [
{
"fields": {
"issuetype": {
"avatarId": 10300,
"description": "",
"id": "10005",
"name": "New Feature",
"subtask": False
},
"status": {
"description": "A resolution has been taken, and it is awaiting verification by reporter. From here issues are either reopened, or are closed.",
"id": "5",
"name": "Resolved",
"statusCategory": {
"colorName": "green",
"id": 3,
"key": "done",
"name": "Done",
}
},
"summary": "Recovered data collection Defraglar $MFT problem"
},
"id": "11861",
"key": "CAE-160",
},
{
"fields": {
... more issues],
"maxResults": 5,
"startAt": 0,
"total": 160
}A not-so-good solution
One option would be to write some code that goes in and looks for a specific field but then you have to call this function for each nested field that you’re interested in and .apply it to a new column in the DataFrame.
First, we would extract the objects inside the fields key up to columns:
df = (
df["fields"]
.apply(pd.Series)
.merge(df, left_index=True, right_index = True)
)
Now we have the summary, but issue type, status, and status category are still buried in nested objects. Here’s a way to extract the issue type name.
# Extract the issue type name to a new column called "issue_type"df_issue_type = (
df["issuetype"]
.apply(pd.Series)
.rename(columns={"name": "issue_type_name"})["issue_type_name"]
)df = df.assign(issue_type_name = df_issue_type)
We could move this code into a function that took in the parent object name, key that we are looking forand new column name but would still need to call this for each field that we want. Not ideal.
A built-in solution, .json_normalize to the rescue
Thanks to the folks at pandas we can use the built-in .json_normalize function. From the pandas documentation:
Normalize[s] semi-structured JSON data into a flat table.
All that code above turns into 3 lines.
- Identify the fields we care about using
.notation for nested objects. - Pass our list of issues to
.json_normalize - Filter the columns
FIELDS = ["key", "fields.summary", "fields.issuetype.name", "fields.status.name", "fields.status.statusCategory.name"]df = pd.json_normalize(results["issues"])df[FIELDS]
Some extras
Record Path
Instead of passing in the list of issues with results["issues"] we can use the record_path argument and specify the path to the issue list in the JSON object.
# Use record_path instead of passing the list contained in results["issues"]pd.json_normalize(results, record_path="issues")[FIELDS]Custom Separator
To separate column names with something other than the default . use the separgument.
# Separate level prefixes with a "-" instead of the default "."FIELDS = ["key", "fields-summary", "fields-issuetype-name", "fields-status-name", "fields-status-statusCategory-name"]pd.json_normalize(results["issues"], sep = "-")[FIELDS]Control Recursion
If you don’t want to dig all the way down into each sub-object use the max_level argument. In this case, since the statusCategory.name field was at the 4th level in the JSON object it won't be included in the resulting DataFrame.
# Only recurse down to the second level
pd.json_normalize(results, record_path="issues", max_level = 2)References
- Sample code is available here: https://gist.github.com/dmort-ca/73719647d2fbe50cb0c695d38e8d5ee6
- For more info on using the Jira API see here— https://levelup.gitconnected.com/jira-api-with-python-and-pandas-c1226fd41219
- Thanks to http://jumble.expium.com/ for making a sample Jira data generator.
- Pandas .json_normalize documentation is available here: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.json_normalize.html





