
Contrastive Pre-training of Visual-Language Models
Fully leveraging supervision signals in contrastive perspectives

Contrastive pre-training has been widely applied in deep learning. One reason for this is that contrastive pre-training can improve the efficiency of labeled data. During unsupervised contrastive pre-training, the unlabeled images are clustered in the latent space, forming fairly good decision boundaries between different classes. Based on this clustering, the subsequent supervised fine-tuning will achieve better performance than random initialization.
Visual-Language Models
Visual-Language models started to catch the attention since the emergence of CLIP, mainly due to the excellent capacity in zero-shot learning.
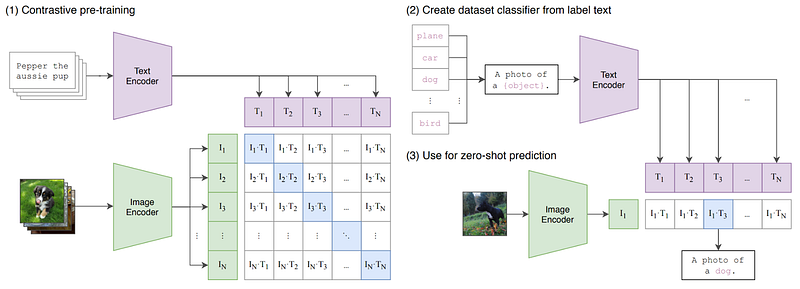
CLIP involves two encoders: image encoder and text encoder. During learning, the input is image-text pairs, such as images and their captions. As shown above, during training, the images and captions in a mini-batch are transformed to vectors of the same length by their corresponding encoders, respectively. After normalization, the image vectors are pulled closer to their corresponding text vectors, and pushed apart from the other text vectors. So are the text vectors.
Models trained with multimodal data like this can produce more robust features than trained with unimodal data. Many computer vision researchers leverage the pre-trained image encoder in CLIP for fine-tuning the downstream vision tasks, achieving better performances than pre-trained with only (unimodal) images.
Training CLIP is difficult as the model is very data-consuming. The authors used 400M image-text pairs collected from the internet to train the model. The dataset is collected by first constructing an allow-list of high-frequency visual concepts from Wikipedia and then curated. However, making such a large scale dataset is costly and will hinder the scaling of training in both dataset and model capacity perspectives.
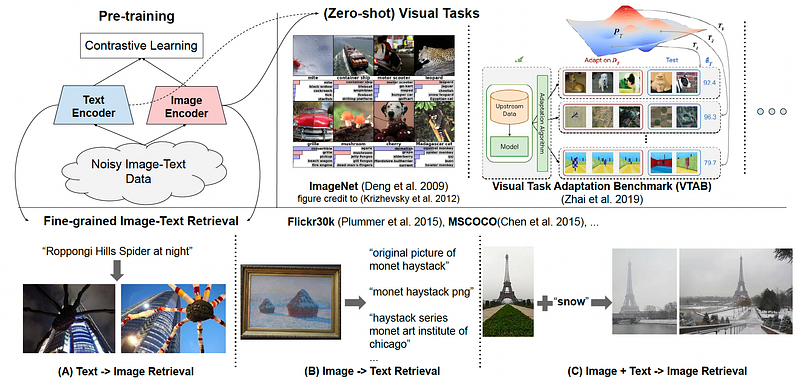
A follow-up work called ALIGN used 1B noisy image-text pairs to train an architecture similar to CLIP. The dataset is not curated or cleaned, and follows the natural distribution of raw image-text data. Thanks to its large size (2.5x more than the dataset used for training CLIP), it could make up the noise and achieved state-of-the-art performances on various downstream tasks.
Using big datasets for training can produce good models but not economic. We notice that CLIP and ALIGN are proposed by OpenAI and Google respectively. Such big techs are no worrying about financial support, which is unaffordable by small startups. Can we train a model with matching performance to CLIP and ALIGN with less image-text pairs in a data-efficient manner?
Data-efficient Visual-Language Models
In CLIP and ALIGN, the latent vectors from different modalities are jointly trained from scratch, neglecting the possibility of performance improvement via contrastive pre-training within each modality. It is interesting to ask if we pre-train both image and text encoders in their corresponding modality respectively in a contrastive manner, how will the model performance change?
Fortunately, a paper from ICLR 2022 conducted some experiments on this. In order to fully exploit the data potential, instead of using only image-text contrastive supervision as in CLIP, the authors proposed other three intrinsic supervision losses: 1) self-supervision within each modality (ISS and TSS); 2) multi-view supervision across modalities (MVS); 3) nearest-neighbor supervision from other similar pairs (NNS). With these losses, the model achieved matching performances in both zero-shot learning and transferred downstream tasks with 7.1x fewer data. The authors named the model data-efficient CLIP (DeCLIP) and the total loss function is shown below.
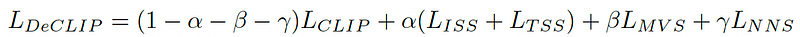
The CLIP loss is the same with the loss in CLIP. ISS is a self-supervised loss defined as negative cosine similarity in the framework of SimSiam, a contrastive learning method without negative pairs. I think it is a good choice because it eliminates the possibility of false negatives which might bring bias to the data. Similarly, TSS is also a self-supervised loss defined as cross-entropy loss in the framework of BERT, a masked language modeling method.
MVS is multi-view supervision across modalities, in which both the input image and text are augmented to two different views respectively, and image-text contrastive loss is calculated for all the 2x2 pairs. The contrastive pairs are 3x more than those used in training CLIP. NNS is the nearest-neighbor image-text contrastive loss, in which the nearest neighbors of text embedding vectors corresponding to the input images are used to form positive pairs. This approach is similar to NNCLR, which samples the nearest neighbors from latent space to form positive pairs. Since the nearest neighbors can provide more semantic variations than pre-defined augmentations, the performances of several experiments are improved in NNCLR. Like NNCLR, DeCLIP also maintains a queue to hold the embedding vectors representing the whole distribution.
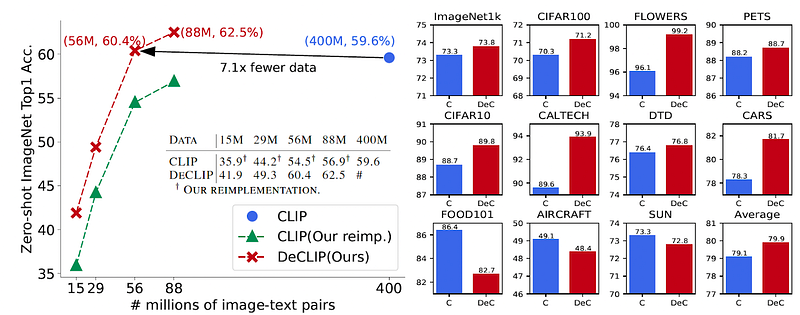
The performance results of DeCLIP are shown above. We can see that it exceeds the zero-shot performance of CLIP, and also transfers to better performances in linear probe verification for 8 out of 11 downstream tasks. Especially in the zero-shot accuracy curve, DeCLIP always performs better than CLIP. This consistency shows the robustness of DeCLIP.
Although DeCLIP achieves better performances with 7.1x fewer data, the dataset still contains 88M image-text pairs which is prohibitive for small startups. We have to notice that the room of improvement in both data-efficiency and parameter-efficiency still exists due to the redundancy in training data and model architectures. Will the methods like model pruning and parameter-efficient training reduce the necessity of training data to a greater extent? Or will there be some methods to reduce the redundancy of training data greatly without hurting performance? I think the answer will come shortly in this rapid development era of AI.
References
Exploring Simple Siamese Representation Learning, 2020
Learning Transferable Visual Models From Natural Language Supervision, 2021
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision, 2021





