
Contrastive Learning in 3 Minutes
The exponential progress of contrastive learning in self-supervised tasks
Deep learning research has been steered towards the supervised domain of image recognition tasks, many have now turned to a much more unexplored territory: performing the same tasks through a self-supervised learning manner. One of the cornerstones that lead to the dramatic advancements in this seemingly impossible task is the introduction of contrastive learning losses. This article dives into some of the recently proposed contrastive losses that have pushed the results of unsupervised learning to heights similar to supervised learning.
InfoNCE Loss
One of the earliest contrastive learning losses proposed was the InfoNCE loss by Oord et al. Their paper Representation Learning with Contrastive Predictive Coding proposed the following loss:
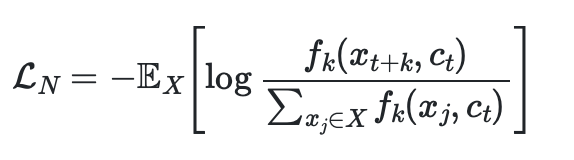
where the numerator is essentially the output of a positive pair, and the denominator is the sum of all value of positive and negative pairs. Ultimately, this simple loss forces the positive pairs to have a greater value (pushing the log term to 1 and hence less to 0) and negative pairs further apart.
SimCLR
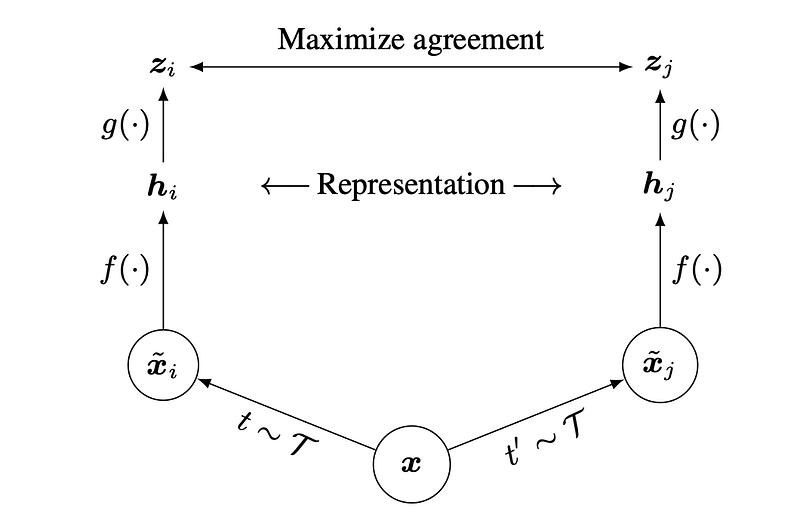
SimCLR is the first paper to suggest using contrastive loss for self-supervised image recognition learning through image augmentations.
By generating positive pairs by doing data augmentation on the same image and vice versa, we can allow models to learn features to distinguish between images without explicitly providing any ground truths.
Momentum Contrast (MoCo)
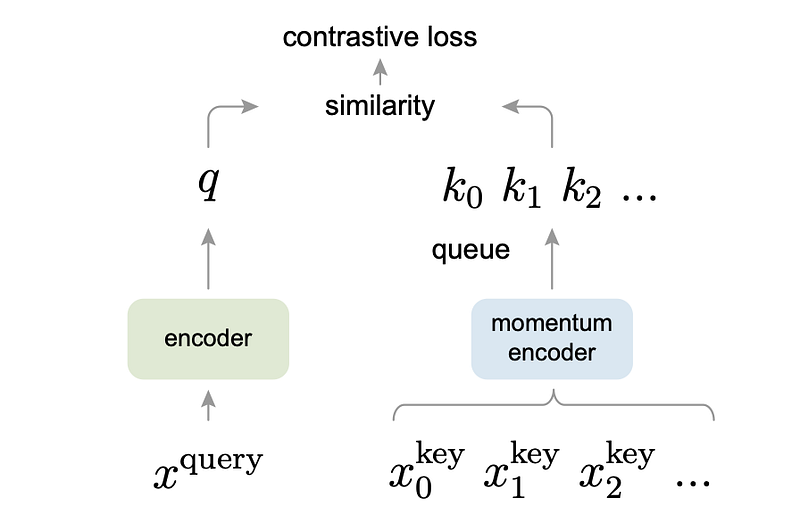
The previous InfoNCE loss is proposed on a mini-batch of one positive and a number of negatives. He et al. extended this concept by portraying the contrastive learning as analogous to learning to match the best key with a given queue. The intuition led to the foundation of momentum contrast (MoCo), which is essentially a dictionary/memory network of key and values with key stored across multiple batches and slowly eliminating the oldest batch in a queue-like manner. This allows the training to be more stable as it is similar to a momentum where the change in keys is less drastic.
Decoupled Contrastive Learning
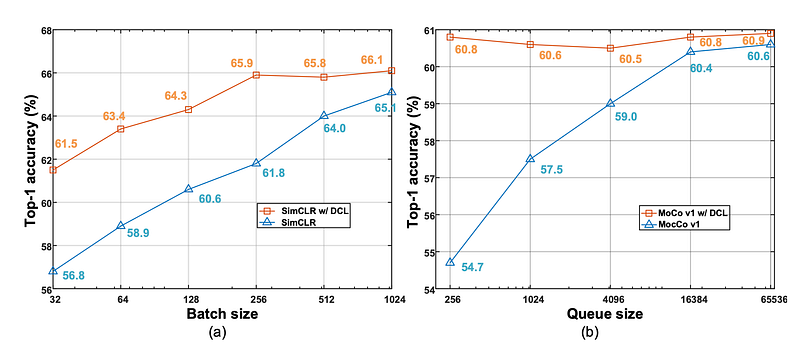
Previous papers in contrastive learning either required large batch sizes or a momentum mechanism. The recent paper decoupled contrastive learning (DCL) hope to change this by bringing a simple change to the original InfoNCE loss: simply removing the positive pair from the denominator.
While seemingly simple, DCL actually allows better convergence and ultimately formed a even better baseline compared to previous papers SimCLR and MoCo.
Testing Each Concept
Codes of the papers above have been provided by the authors. To test these concepts, one can simply download different datasets to see how well the unsupervised learning method works.
It is important to keep note that these tasks often require your own dataloaders instead of using the ones given by PyTorch. One place you can retrieve datasets such as ImageNet, CIFAR100, and other notable image datasets is here.
End Note
And there you have it! A short article on the recent advances of contrastive learning papers in unsupervised learning for image recognition. This article only covers some of the work under this scope. Many great papers such as NNCLR and MoCo v2 are also worth a read. Hopefully you had fun in understanding these elegant yet effective concepts!
Thank you for making it this far 🙏! I will be posting more on different areas of computer vision/deep learning, so join and subscribe if you are interested to know more!