
k-Means Clustering: Comparison of Initialization strategies.
k-Means is a data partitioning algorithm which is among the most immediate choices as a clustering algorithm. Some reasons for the popularity of k-Means are:
- Fast to Execute.
- Online and Mini-Batch Implementations are also available thus requiring less memory.
- Easy interpretation. The centroid of a cluster often gives a fair idea of the data present in the cluster. This cannot be said about some other clustering algorithms which are able to detect non-convex clusters where the centroid might not even lie within the cluster.
- Results of k-Means can be used as starting points for other algorithms. It is often a practice to Use the centroids of k-Means as starting points for Gaussian Mixture Models.
However, the results of k-Means depend heavily on the initialization. In the following article we will compare the results obtained through the following initialization strategies:
- Forgy Initialization
- Random Partition Initialization
- kmeans++ Initialization
It is a standard practice to start k-Means from different starting points and record the WSS(Within Sum of Squares) value for each initialization. We then accept the clustering solution that corresponds to the least WSS.
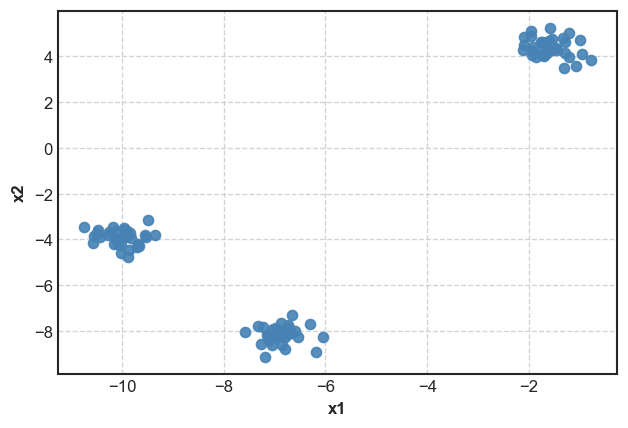
To compare the methods, we will choose an artificial data with 3 clusters and 2 variables. We will then repeat the initialization procedure 10 times with each method and visualize initial points chosen by the initialization strategies.
Please note that we are only comparing the results of various initialization methods. The final clusters after executing k-Means has not been discussed at full in this article.
Data used for the trials
Forgy Initialization
This method is one of the faster initialization methods for k-Means. If we choose to have k clusters, the Forgy method chooses any k points from the data at random as the initial points.
This method makes sense because the clusters detected through k-Means are more probable to be near the modes present in data. By randomly choosing points from data, we are making it more probable to get a point that lies close to the modes.
Following is an implementation of Forgy’s initialization in Python:
def forgy_initialize(X, k):
'''Return Randomly sampled points from the data''' return X[np.random.choice(range(X.shape[0]), replace = False, size = k), :]Let us take a look at 10 different initializations using Forgy’s method:
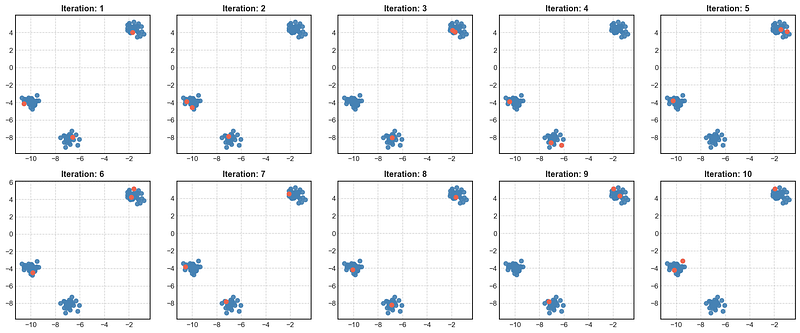
We can observe the following:
- In Iterations 1, 7, 8: Forgy’s method initialized one center inside each cluster. This is an indication of a good starting point to run k-Means because the starting points are already in the respective clusters and are hence close to the true centroids. k-Means is most likely to converge to the global optimum in a few iterations.
- In Iterations 2, 3, 4, 5, 6, 9, 10: Forgy’s Method initialized 2 points to lie inside the same cluster. This is not an ideal condition. This may result in the algorithm reaching a local optimum with a poor solution. To illustrate, here is what happened when I ran k-Means from this configuration:
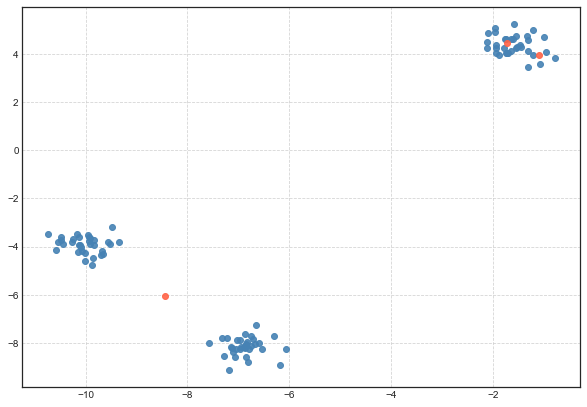
The above situation can be avoided if we remember to run k-Means from different initial configurations(we are then likely to get some good configurations as in Iterations 1, 7, 8) which will yield the global optimum.
Random Partition Method
In this method, we randomly assign each point in the data to a random cluster ID. Then, we group the points by their cluster ID and take the average (per cluster ID) to yield the initial points. Random Partition method is known to yield initial points close to the mean of the Data.
Here is the code to generate Initial points using Random Partition method:
def random_partition(X, k):
'''Assign each point randomly to a cluster. Then calculate the Average data in each cluster to get the centers'''
indices = np.random.choice(range(0, k), replace = True, size = X.shape[0])
mean = []
for count in range(k):
mean.append(X[indices == count].mean(axis=0))
return np.concatenate([val[ None, :] for val in mean], axis = 0)Let us take a look at 10 different initializations using Random Partition method:
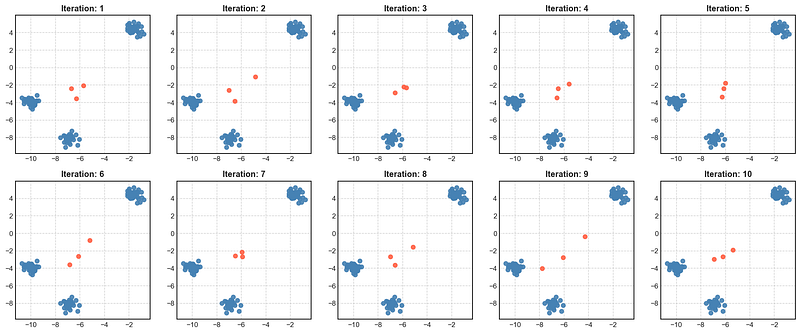
As we can see, the initial points chosen lie very close to the global mean of the data. This is not the recommended method to initialize for k-Means. Please refer to the Conclusion section of: https://dl.acm.org/doi/10.1145/584792.584890 for a summary of clustering algorithms for which random partition works relatively well.
k-Means is more likely to get stuck in Local Optima if initialized using this method.
kmeans++
This is a standard method and which generally works better than Forgy’s method and the Random Partition method for initializing k-Means.
The method is described in details in: http://ilpubs.stanford.edu:8090/778/1/2006-13.pdf
Here, the idea is to choose initial points which are as far apart from each other as possible.
- We begin by choosing a random point from the data.
- Then, we choose the next point such that is more probable to lie at a large distance from the first point. We do so by sampling a point from a probability distribution that is proportional to the squared distance of a point from the first center.
- The remaining points are generated by a probability distribution that is proportional to the squared distance of each point from its closest center. So, a point having a large distance from its closest center is more likely to be sampled.
Here is the code to generate initial points using kmeans++
def dist(data, centers):
distance = np.sum((np.array(centers) - data[:, None, :])**2, axis = 2)
return distancedef kmeans_plus_plus(X, k, pdf_method = True):
'''Initialize one point at random.
loop for k - 1 iterations:
Next, calculate for each point the distance of the point from its nearest center. Sample a point with a
probability proportional to the square of the distance of the point from its nearest center.'''
centers = []
X = np.array(X)
# Sample the first point
initial_index = np.random.choice(range(X.shape[0]), )
centers.append(X[initial_index, :].tolist())
print('max: ', np.max(np.sum((X - np.array(centers))**2)))
# Loop and select the remaining points
for i in range(k - 1):
print(i)
distance = dist(X, np.array(centers))
if i == 0:
pdf = distance/np.sum(distance)
centroid_new = X[np.random.choice(range(X.shape[0]), replace = False, p = pdf.flatten())]
else:
# Calculate the distance of each point from its nearest centroid
dist_min = np.min(distance, axis = 1)if pdf_method == True:
pdf = dist_min/np.sum(dist_min)# Sample one point from the given distribution
centroid_new = X[np.random.choice(range(X.shape[0]), replace = False, p = pdf)]
else:
index_max = np.argmax(dist_min, axis = 0)
centroid_new = X[index_max, :]
centers.append(centroid_new.tolist())
return np.array(centers)Let us take a look at 10 different initializations using kmeans++ method:
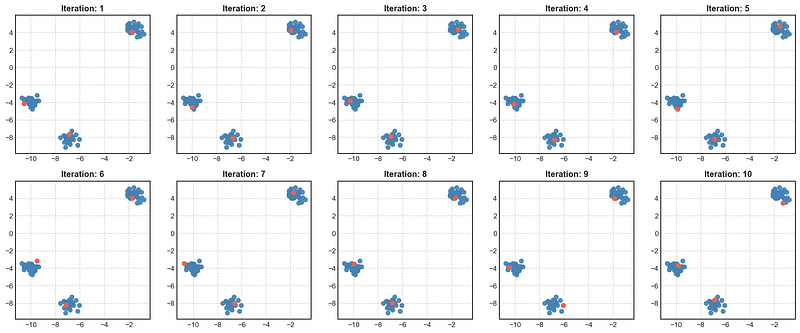
As we can see, in all 10 cases, all the initial points are inside the respective clusters. This method of generating initial points helps k-Means converge to the Global Minimum in just a few iterations. This is the recommended method to generate initial points for k-Means Algorithm.
Conclusion
Overall, we saw that the method for initializing k-Means that gave the best initial points was kmeans++. Even though we got great initial points by running kmeans++, it is still recommended to run k-Means from different starting points.
Even though k-Means is a relatively simple algorithm that makes a lot of assumptions, it is still very useful in a variety of settings due to its speed, scalability and ease of interpretation.