
Comparing Word Embeddings for Text Classification: Word2Vec vs. GloVe vs. FastText

In the world of Natural Language Processing (NLP), word embeddings have transformed how we work with text data. They help us convert text into vectors, making it easier for machine-learning models to understand language. But with so many embedding techniques out there, how do you know which one to use?
Today, we’re going to compare three of the most widely used word embedding techniques: Word2Vec, GloVe, and FastText. By the end of this post, you’ll have a better understanding of each method’s strengths, weaknesses, and when to use them for your text classification projects.
What Are Word Embeddings?
Word embeddings are dense vector representations of words. Unlike traditional methods like Bag of Words or TF-IDF, embeddings capture semantic relationships between words. For example, in a good embedding space, “king” might be close to “queen,” and “man” might be close to “woman.” These vectors help machine learning models capture the contextual meaning of words, improving their ability to process text data.
Let’s dive into each of these popular embedding methods and see how they differ.
- Word2Vec: Learning Relationships from Context
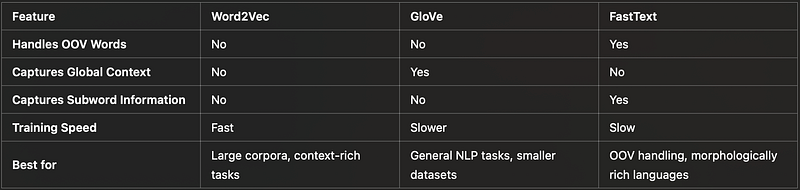
Developed by Google, Word2Vec represents words in a continuous vector space. It uses a shallow neural network to predict word relationships based on their context, learning from either a Skip-Gram or Continuous Bag of Words (CBOW) approach.
• Skip-Gram predicts the context words given a target word, focusing on capturing the meaning of rare words.
• CBOW predicts a target word based on its surrounding context, typically faster but better suited for frequent words.
Strengths:
• Captures both semantic and syntactic relationships.
• Works well with medium-sized datasets.
Weaknesses:
• Word2Vec cannot handle out-of-vocabulary (OOV) words, meaning words not seen during training have no vectors.
• Words are treated as single entities, which can miss morphological nuances (e.g., “running” vs. “run”).
When to Use:
Word2Vec is a good choice when you have a relatively large corpus and want to capture rich semantic relationships between words. It works well in many NLP tasks, such as sentiment analysis or topic classification, where understanding word meaning based on context is essential.
2. GloVe: Global Co-occurrence for Better Generalization
GloVe (Global Vectors for Word Representation) was developed by researchers at Stanford. Unlike Word2Vec, GloVe doesn’t rely on local context but instead leverages global word co-occurrence statistics across the entire corpus. It builds a word-word co-occurrence matrix and then factorizes it to generate embeddings.
Strengths:
• Captures global relationships between words, which can make it more robust in smaller datasets.
• Generates embeddings that work well across different domains, especially for generalized tasks.
Weaknesses:
• Like Word2Vec, it struggles with OOV words.
• GloVe training requires more computational resources due to the large co-occurrence matrix.
When to Use:
GloVe is excellent for tasks where capturing global word relationships is crucial, such as document similarity or when dealing with domain-specific data. It performs well when you have a smaller corpus or when you need embeddings pre-trained on large datasets (e.g., Wikipedia).
3. FastText: Handling Subword Information
Developed by Facebook, FastText extends Word2Vec by taking into account subword information. Instead of treating each word as a single entity, FastText breaks words down into n-grams (subword units). This allows it to generate embeddings for words not seen during training by combining the n-grams that make up the word.
Strengths:
• Handles OOV words by generating embeddings based on subword components.
• Better performance for morphologically rich languages (e.g., German, Finnish).
Weaknesses:
• FastText can generate noisier embeddings because subword information might not always reflect meaning (e.g., “apple” and “applesauce”).
• Slower training compared to Word2Vec due to the increased number of parameters from subword information.
When to Use:
FastText shines in tasks where you need to handle OOV words or work with languages with complex morphology. It’s especially useful in text classification tasks where you might encounter variations of the same word or need to work with domain-specific terms.
Comparing Word Embeddings: Which One Should You Use?
Conclusion
Choosing the right word embedding depends on your task, dataset, and specific needs. If you’re dealing with a large, diverse corpus and want to capture complex semantic relationships, Word2Vec is a solid choice. GloVe is better suited for general-purpose embeddings where global context is essential, and FastText is your go-to when handling OOV words or working with highly inflected languages.
Each embedding technique has its unique strengths, so it’s worth experimenting with different methods to see which one works best for your project. Hopefully, this comparison has given you a clearer idea of when to use Word2Vec, GloVe, or FastText for your text classification needs.
I hope you learned something new! Please consider following for more such blogs!
Cheers!