Comparing Data Warehouses, Data Lakes and Data Lakehouses
Differences and Combination Opportunities

What is a Data Warehouse and how does it differ from a Data Lake or even a Data Lakehouse? In the latter case, they even build on each other — here is an overview for you.
The Data Warehouse
A Data Warehouse is a system used for reporting and Data Analysis and is considered a core component of business intelligence. Data Warehouses and classical OLAP BI Technologies have been the cornerstones of business intelligence for decades and probably still will but a few approaches begin to loose their relevance. New approaches, technologies and especially the cloud are changing the field a lot and offer new opportunities. Data Warehouses are classical relational systems that work with structured data. Exceptions are new cloud-based Data Warehouse technologies such as BigQuery or Snowflake which can also work with unstructured data and are column-based.
The Data Lake
A Data Lake on the other hand is a large pool of raw data for which no use has yet been determined [1]. In a Data Lake, the data is ingested into a storage layer with minimal transformation while maintaining the input format, structure and granularity. This contains structured and unstructured data. This results in several features, such as:
- Collection of multiple data sources such as bulk data, external data, real time data, etc.
- Control of ingested data and focus on documenting data structure.
- Generally useful for analytical reports and Data Science.
- But one can also include an integrated Data Warehouse to provide classic management reports and dashboards.
- A Data Lake is a data storage pattern that prioritizes availability over everything else, across the enterprise, across all departments, and for all users of the data.
- Easy integrability of the new data source.
Differences between a Data Lake and Data Warehouse
While Data Warehouses use the classic ETL process in combination with structured data in a relational database, a Data Lake uses paradigms such as ELT and a schema on read as well as often unstructured data [2].
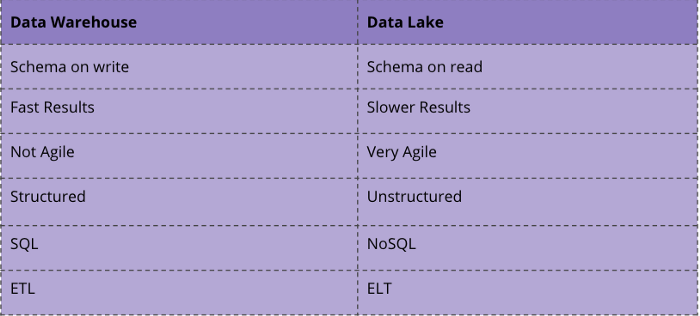
In the figure above, you can see the main differences. Also the technologies you use are quite different. For a Data Warehouse you will use SQL and relational databases while for data lakes you will probably use NoSQL or a mixture of both.
The Data Lakehouse
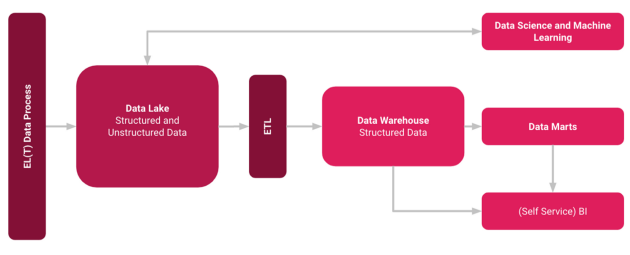
The Data Lakehouse combines the advantages of Data Lakes and Data Warehouses into a hybrid concept. The two systems are not operated side by side, but as a novel single system. The raw data is loaded into a flexible Data Lake data storage and when processed to via ETL process into the Data Warehouse. From there it can be used for Machine Learning, BI Tools or other services.
Summary
To make a long story short: The Data Lakehouse combines a Data Lake with a Data Warehouse. First, the data is loaded unformatted via ELT into a Data Lake. This is often the case because in the age of Big Data, so much data in so many different formats is generated that this approach makes real time provision possible at all. From here, the data can be made available for machine learning or for a Data Warehouse. For the latter, an ETL process is often used. In the Data Warehouse, the data is then available in a structured form for use cases such as dashboarding, reporting or ad-hoc analyses.
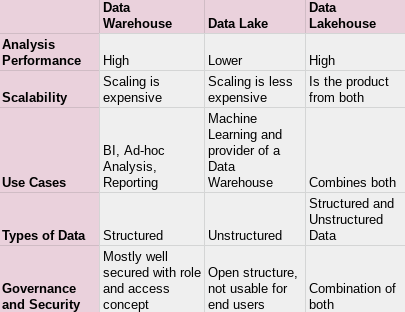
Finally, a brief overview of the approaches and their differences:
Sources and Further Readings
[1] talend, Data Lake vs. Data Warehouse
[2] IBM, Charting the data lake: Using the data models with schema-on-read and schema-on-write (2017)