
CogVLM Unveiled: Revolutionizing AI with Visual-Language Fusion
Discover How CogVLM is Redefining Multimodal AI Integration

“CogVLM: Visual Expert for Large Language Models” is a groundbreaking accomplishment that opens up new possibilities in Artificial Intelligence (AI). The open-source visual language foundation model CogVLM skillfully combines the domains of large language models (LLMs) with visual data processing. In the current AI landscape, where the synergy of visual and verbal understanding is not just an advantage but a need, this groundbreaking integration is essential. CogVLM establishes a new standard for intelligent systems and signals a change in how robots view and engage with the multimodal world.
Innovative Architecture of CogVLM
“Is it possible to retain the NLP capabilities of the LLM while adding top-notch visual understanding abilities to it?”
The innovative architecture of CogVLM is central to its ability to deeply and effectively integrate visual and linguistic data. CogVLM includes a trainable visual expert module within its architecture, in contrast to other systems that rely on shallow alignment techniques. This module is embedded in both the attention and Feedforward Neural Network (FFN) layers of the LLMs. The FFN, a standard component in neural networks, consists of fully connected layers that apply linear transformations and non-linear activations to the data. In CogVLM, this inclusion enhances the model’s capacity to process and integrate visual data more deeply with textual information, overcoming the limitations of previous models that struggled with effectively combining these different types of data. This deep fusion approach marks a significant advancement in the field of visual-language integration.
CogVLM’s architecture comprises of several sophisticated components:
- Vision Transformer (ViT) Encoder: CogVLM’s ViT encoder is a pretrained EVA2-CLIP-E. Since the main purpose of this encoder is to aggregate [CLS] features for contrastive learning, the last layer is left out. In order to analyze and encode visual data into a format that can be combined with written information, this encoder is essential.
- MLP Adapter: The objective of the Multi-Layer Perceptron (MLP) adapter in CogVLM is to map the output of the ViT into the same space as the text characteristics from word embedding. It is a two-layer MLP, namely a SwiGLU. Ensuring alignment between image and text characteristics in their representational space is crucial for efficient multimodal processing.
- Pretrained Large Language Model (GPT): Any commercially available GPT-style pretrained big language model can be used with CogVLM’s design. To enhance training, CogVLM-17B, for example, incorporates Vicuna-7B-v1.5. Processing textual data is the responsibility of this component, which has been modified to function in conjunction with visual data as well.
- Visual Expert Module: The visual expert module, which is introduced to each layer of the model to enable deep visual-language feature alignment, is arguably the most unique element of CogVLM. A Query-Key-Value (QKV) matrix and an MLP make up each visual expert module, which is structured similarly to the pretrained language model. Through the use of this architecture, a deeper and more meaningful merger of linguistic and visual data is made possible by the visual expert’s ability to alter image attributes to coincide with different attention heads in the language model.
When combined, these elements enable CogVLM to accomplish high-level visual and textual information integration, surpassing simple surface-level correlations to comprehend and provide outputs that are more semantically aligned and contextually rich. This technology is unique in that it can efficiently process and synthesize multimodal data.
Benchmarking CogVLM: A Leap in Performance
The paper “CogVLM: Visual Expert for Large Language Models” describes CogVLM’s remarkable performance in a number of cross-modal benchmarks.
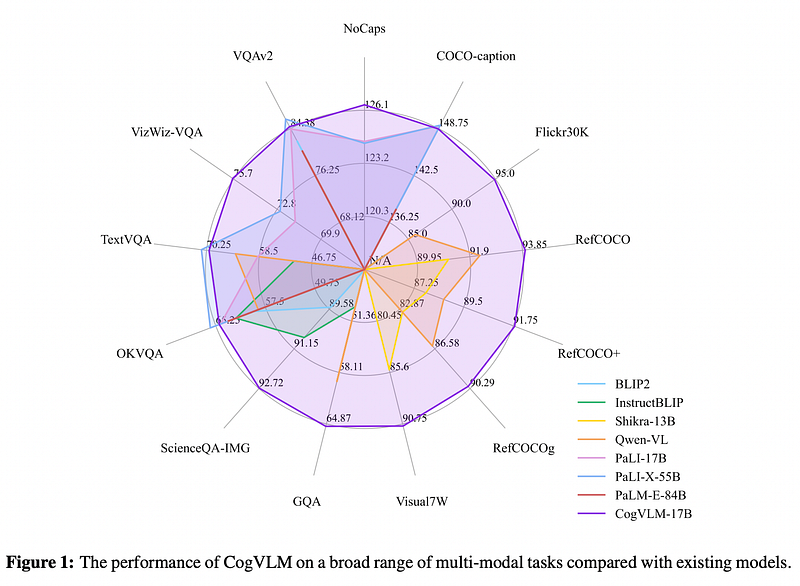
When it comes to activities like visual question answering, image captioning, and visual grounding, CogVLM performs better than current models. This reveals its sophisticated comprehension and interpretation of intricate visual-language contexts. The benchmarking results demonstrate how well CogVLM performs in precisely evaluating visual input and merging it with textual information — a major improvement over earlier models. These accomplishments highlight CogVLM’s potential as a flexible and effective AI tool.
Implications for Future Research and Open Source Impact
The creation of CogVLM and its open-source nature will have a significant impact on multimodal research and visual language models (VLMs) in the future. With this model, the method of VLM training has undergone a substantial change from shallow alignment to deep fusion of language and visual data. CogVLM has achieved state-of-the-art performance across a wide range of traditional multi-modal benchmarks because to this methodological innovation.
Being open-source has a particularly big impact on CogVLM. In the past, a large number of well-known VLMs were closed-source, which restricted access for developers and researchers. By being freely accessible, CogVLM opens the door to a wider range of advancements in the multi-modal AI space. With the ability to access and expand upon this sophisticated model, researchers and developers from a variety of fields, including academia and industry, can now promote creativity and cooperation in ways that were not achievable with closed-source models.
Additionally, the fact that CogVLM is open-source encourages research into novel VLM training domains. Research is needed in areas like improved supervised finetuning (SFT) alignment, RLHF (Reinforcement Learning from Human Feedback), and anti-hallucination methods. These topics are at the forefront of VLM research and development, and CogVLM offers a strong platform for their advancement.
A New Era in AI
The developments showcased in “CogVLM: Visual Expert for Large Language Models” mark a turning point in the development of artificial intelligence. Its ground-breaking methodology opens the door for more intelligent, contextually aware, and intuitive systems, indicating a time when AI will be able to see and interact with the world similarly to how humans do. Not only does CogVLM represent progress, but it also heralds a new era of AI invention and discovery by skillfully blending the lines between verbal and visual intelligence.
Life is Golden. — Adam D.
References
Cogvlm: Visual expert for pretrained language models W Wang, Q Lv, W Yu, W Hong, J Qi, Y Wang, J Ji… — arXiv preprint arXiv:2311.03079, 2023
Github Repo: CogVLM & CogAgent
Prompt: A minimalistic digital interface, highlighting the seamless integration of visual and textual data in a modern AI system. The design focuses on clarity and ease of understanding, reflecting the contemporary and efficient nature of COGVLM.

This story is published on Generative AI. Connect with us on LinkedIn and follow Zeniteq to stay in the loop with the latest AI stories. Let’s shape the future of AI together!
