
CNNs from different viewpoints
Prerequisite: Basic neural networks
The theme of this post

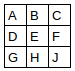
The image
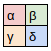
The filter
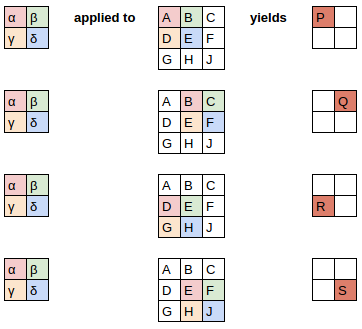
Since the filter fits in the image four times, we have four results
Here’s how we applied the filter to each section of the image to yield each result
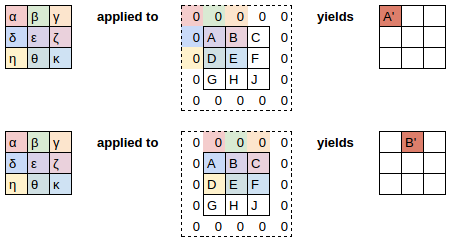
The equation view
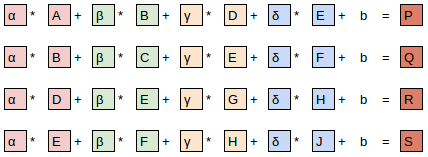
Notice that the bias term, b, is the same for each section of the image. You can consider the bias as part of the filter, just like the weights (α, β, γ, δ) are part of the filter.
The compact equation view
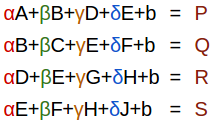
The neural network view
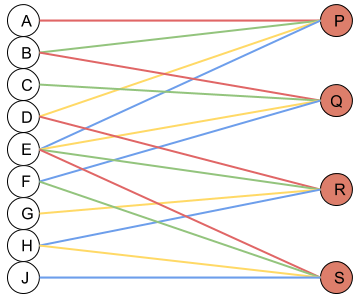
The matrix multiplication view
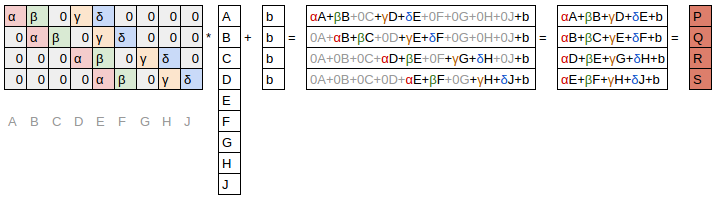
The matrix above is a weight matrix, just like the ones from traditional neural networks. However, this weight matrix has two special properties:
- The zeros shown in gray are untrainable. This means that they’ll stay zero throughout the optimization process.
- Some of the weights are equal, and while they are trainable (i.e. changeable), they must remain equal. These are called “shared weights”.
The zeros correspond to the pixels that the filter didn’t touch. Each row of the weight matrix corresponds to one application of the filter.
The dense neural network view
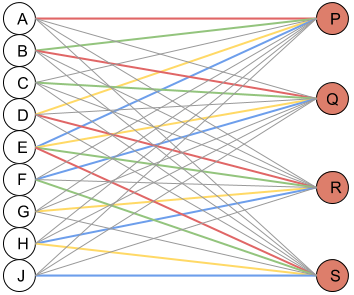
The gray connections correspond to the untrainable zeros. This graph is the same as the previous graph, except that it shows the untrainable zeros. This view helped me see the connection between traditional neural networks and CNNs.
A familiar diagram
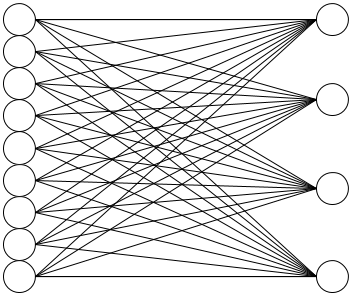
How did I learn this?
- Jeremy Howard’s deep learning course, especially his CNN spreadsheet and the corresponding video (0:00 to 14:00)
- Michael Nielsen’s deep learning book, especially chapter 1 (NNs) and chapter 6 (CNNs)
I found out about Michael Nielsen’s book from Jeremy’s suggested readings for NNs and readings for CNNs.
Bonus: Preserving the image size with zero-padding and a 3x3 filter
Notice that we went from a 3x3 image to a 2x2 image.

With zero-padding and a 3x3 filter, we can preserve the image size.
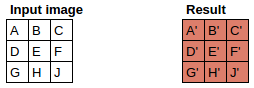
Here’s what zero-padding with a 3x3 filter looks like:
The 3x3 filter allows us to center the filter on each pixel, so that each original pixel corresponds to a pixel in the result. Although, without zero-padding, our filter would get stuck in the corners, unable to center on any pixel except pixel E, and the result would be a 1x1 image.

Important things that I didn’t talk about or diagram
- Activation functions
- Pooling
- Multiple filters
- Multiple convolutional layers
- Dense layers (without shared weights or untrainable zeros)
- The output layer
- The optimization process (i.e. gradient descent via backpropagation)
- How to do useful things with CNNs
Important views I didn’t show
- Code views (e.g. a Python view or a Keras view)
- Realistic views (i.e. with real images)
- Many-filter views (here and here)
- Interactive views (here and here)





{kind=link}