
Clustering Financial News using BERTopic and GPT in 5 simple steps
Using Generative AI to understand and group complex domain-specific texts

Part 1: Clustering Financial News using BERTopic and GPT Part 2: Few-Shot Learning: A smart way to perform topic modeling using GPT (coming soon)
Welcome to part 1 of the series. There are several instances in our career as Data Scientists, where we have to uncover topics in large collections of texts. In this article, I will show you how to quickly cluster millions of financial news headlines using language models BERT and GPT. This can identify the main topics or themes that are discussed in the news, such as mergers and acquisitions, earnings reports, market trends, etc. It can also help investors and analysts to filter and prioritize the most relevant information for their needs.
I will be focusing on speed here to help you get a clustering model up and running asap.
A brief introduction to language models
BERT is a powerful pre-trained language model that can be fine-tuned for various natural language processing tasks. However, BERT may not perform well on some domains that have different vocabulary, syntax, or semantics from the general domain that BERT was trained on. To train BERT in finance domain, one needs to collect a large and representative corpus of financial texts, and then apply the same masked language modeling and next sentence prediction objectives that were used to pre-train BERT. This way, BERT can learn the domain-specific knowledge and adapt to financial jargon.
GPT is a language model that uses a deep neural network to learn from large amounts of text data. Unlike other language models that rely on fixed rules or predefined categories, GPT can generate natural and coherent text based on the context and the input. GPT understands more than other language models because it can capture the meaning, structure, and style of language at multiple levels, from words to sentences to paragraphs. GPT can also adapt to different domains, tasks, and genres, making it a versatile and powerful tool for natural language processing.
How does GPT differ from BERT?
GPT and BERT are two language models that use deep neural networks to learn from large amounts of text data. Both models can adapt to different domains, tasks, and genres, but they have different strengths and limitations. GPT is better at generating fluent and coherent text, while BERT is better at understanding the meaning and the relationships of words in a text.
Can we use both in conjunction?
BERTopic is a topic modeling framework that discover topics from large collections of text documents. It leverages the power of BERT to create topic embeddings, which are vectors that capture the semantic information of each topic. BERTopic can use OpenAI’s GPT-3 language model to generate topic representations that are more coherent and interpretable.
I will the daily financial news data for 6000 stocks from here.
Let’s get started!
Step 1 — Sanitize the data
Often the first step, and the most deterring one is preprocessing. This involves removing stop words and punctuations, changing case, stemming or lemmatization. Since this is repetitive, I had developed reusable modules for these tasks. Here I will use cleantext (source: https://pypi.org/project/cleantext/) as they have done it far better than I could.
Step 2 — Convert text to embeddings
FinBERT embeddings (source: https://pypi.org/project/finbert-embedding/) are trained on a large corpus of financial texts. They capture the semantic and syntactic information of words in the financial domain. I’m going to use them to convert news headlines into sentence embeddings (averaged across all words in the headline). You would find open-source embeddings in many domains; personally I have used fine-tuned embeddings mainly in the medical domain.
Step 3 — Configure and run BERTopic
BERTopic is not a model in itself — it uses four key components:
Embedding: We have already gone through this, I have used FinBert to convert headlines into vector representations. Dimensionality reduction: To reduce the high-dimensional embeddings into a lower-dimensional space, you can use PCA, t-SNE or the newest one which is UMAP. Clustering: This can be any model that groups documents into clusters, such as DBSCAN or K-Means. Cluster tagging: This component assigns a representative label to each cluster by using a class-based term frequency-inverse document frequency (c-TF-IDF) measure that ranks the most relevant words for each cluster.
You can provide a fixed number of topics or let the model uncover it from the data. The larger your data, the more chances of having noise. I almost always recommended starting with a fixed number here. Feel free to borrow contextual knowledge from your manager or business partners.
This takes a bit to run depending on your data size. By the end of it, we have the topics and a representative document for each topic. The representation is just a collection of words with highest c-TF-IDF scores. If you think these don’t look informative, wait until step 5.
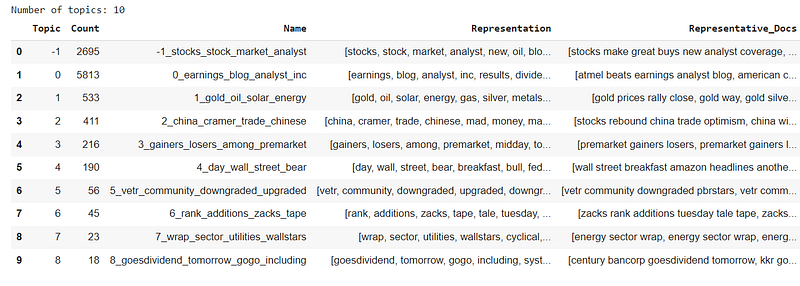
Step 4 — Analyze the topics
This is the part where we de-noise the results. There are several ways to do this and BERTopic provides a handful of visualizations that give you a kickstart.
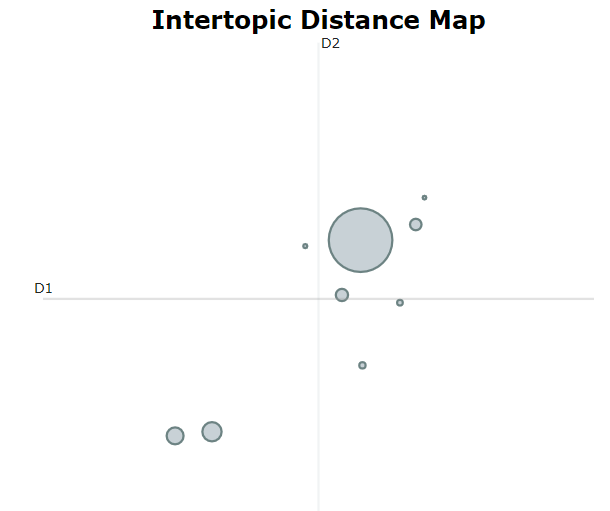
The interactive intertopic distance map helps you combine similar topics. The 4 to 5 topics in top right quadrant talk about company earnings and results. One of the topics in bottom left quadrant talk about commodities like gold, oil and energy. The other one captures headlines about trade relations with China. Pretty interesting stuff, in about 5 minutes we have a fair idea about 1 million news headlines.
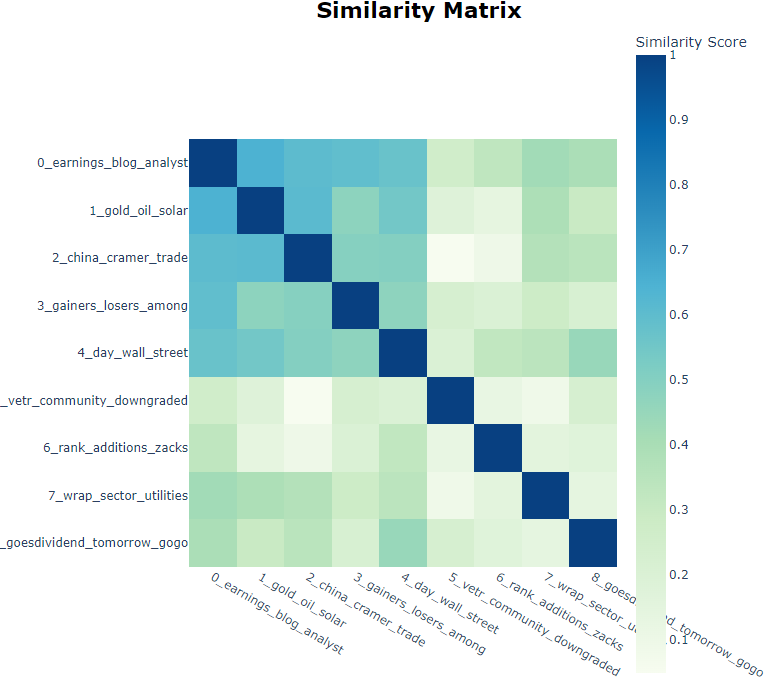
We can also create the traditional heatmap to identify similar topics.
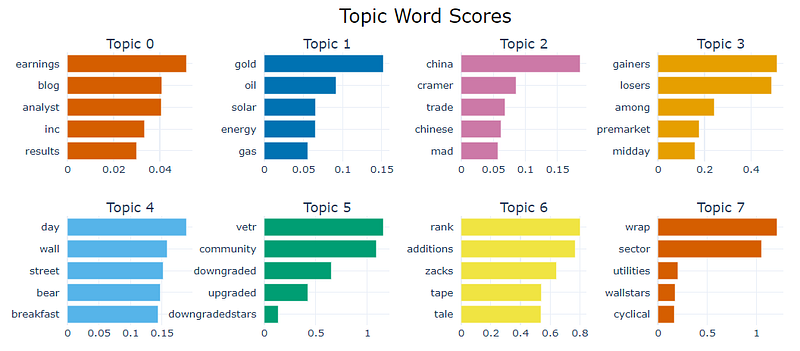
We can take a quick look at topic words and their c-TF-IDF scores.
Step 5 — Refine topic representations with GPT
Now we’ve reached the fun part — enter GPT. Continuing on our speed streak, we can use generative AI models to create summarized noise-free representations of topics. In other words, we can provide a set of candidate headlines to GPT and ask it to summarize the topic within them in plain old English.
Before: [‘earnings’, ‘blog’, ‘analyst’, ‘inc’, ‘results’, ‘dividend’, ‘buys’, ‘stocks’, ‘call’, ‘stock’]
After: Financial Analysis and Investments in Stocks
Before: [‘gold’, ‘oil’, ‘solar’, ‘energy’, ‘gas’, ‘silver’, ‘metals’, ‘natural’, ‘crude’, ‘precious’]
After: Financial and Energy Sector Wrap
Conclusion
As you’ve seen, we have clustered every news headline under a topic. On many occasions, text documents contain more than one themes. That’s where we have to switch from topic modeling to multi-aspect modeling. In Part 2, I will show how this can be done.
Stay tuned! 😋





