
Choosing a CQRS Architecture That Works for You
A comparison between the different types of CQRS architecture and how to choose the right one for your problem
Command Query Responsibility Segregation (CQRS) is a vast ocean of deep topics within The World of Software Architecture. It is often stigmatised with huge complexity, and many engineers are reluctant to dip their toes in the water.
Some great articles talk through complex, eventually consistent, distributed CQRS system architectures that can handle massive scale. If you are just getting started with CQRS, then this can be a little daunting. In reality, there are also much simpler options that work well for most problems.
Command Query Responsibility Segregation (CQRS)
CQRS splits data access into Commands and Queries.
- Commands: Write data – Create/Update/Delete
- Queries: Read data
Each Command and Query class has a corresponding Handler class. Generally, Commands and Queries are dispatched to their Handler using a synchronous in-process Mediator. Sometimes asynchronous methods, such as a Message Bus, are used for handling Commands when there are high-scale requirements.
Splitting Write and Read operations means we can optimise each side independently. This might mean different Write and Read models. It might even mean completely different databases. That choice depends on the non-functional requirements of your app.
Let’s talk through some of the options and when they can be used.
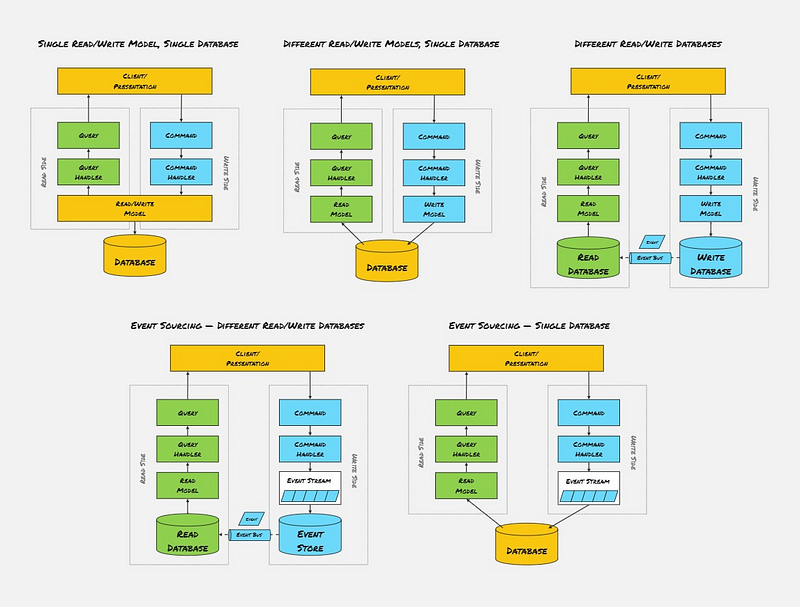
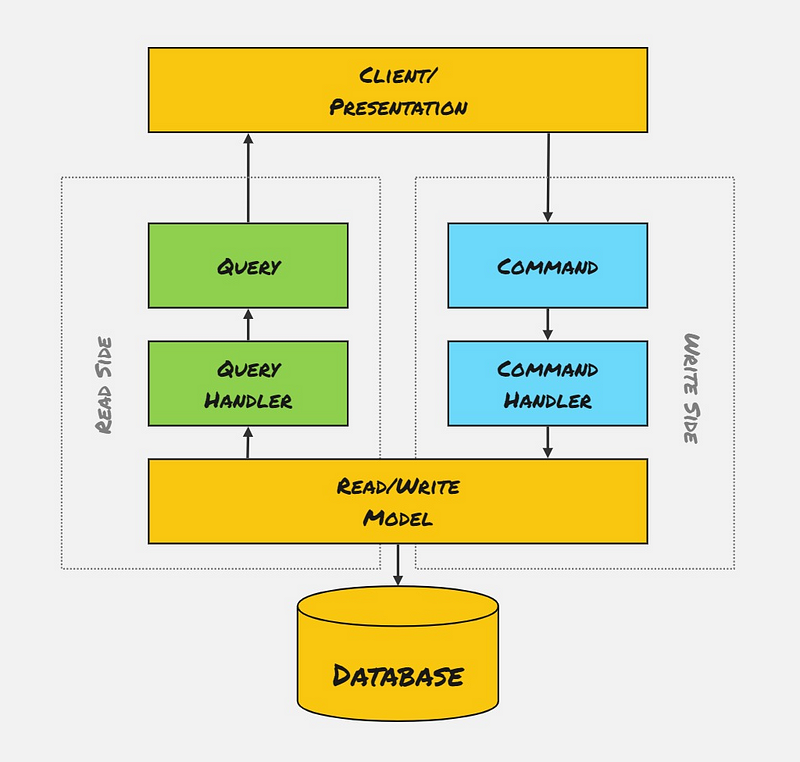
Single Read/Write Model, Single Database
This is the simplest flavour of CQRS, where our Commands and Queries use the same Model/Entity classes. For most small-to-medium-sized apps, this is generally fine!
- Consistency: Strong
- Complexity: Low
- Performance/Scalability: Low
This is a great option if you are new to using CQRS; it still provides one of the biggest benefits that CQRS brings: clean code and separation of concerns. Splitting our code into granular Commands/Queries/Handlers ensures that the Single Responsibility Principle (SRP) is adhered to, which makes our solutions flexible for change and easy to test.
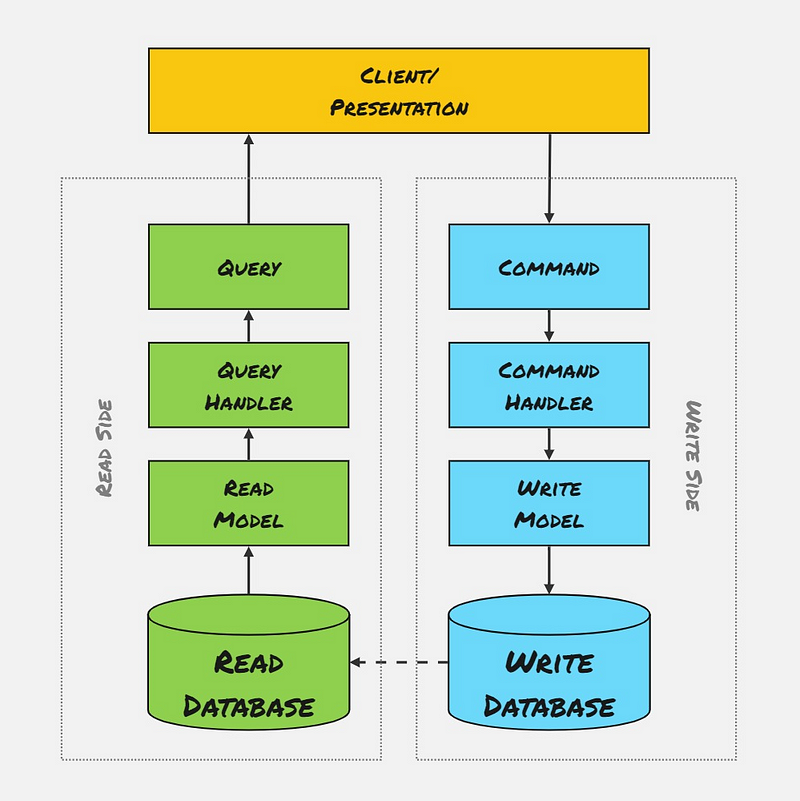
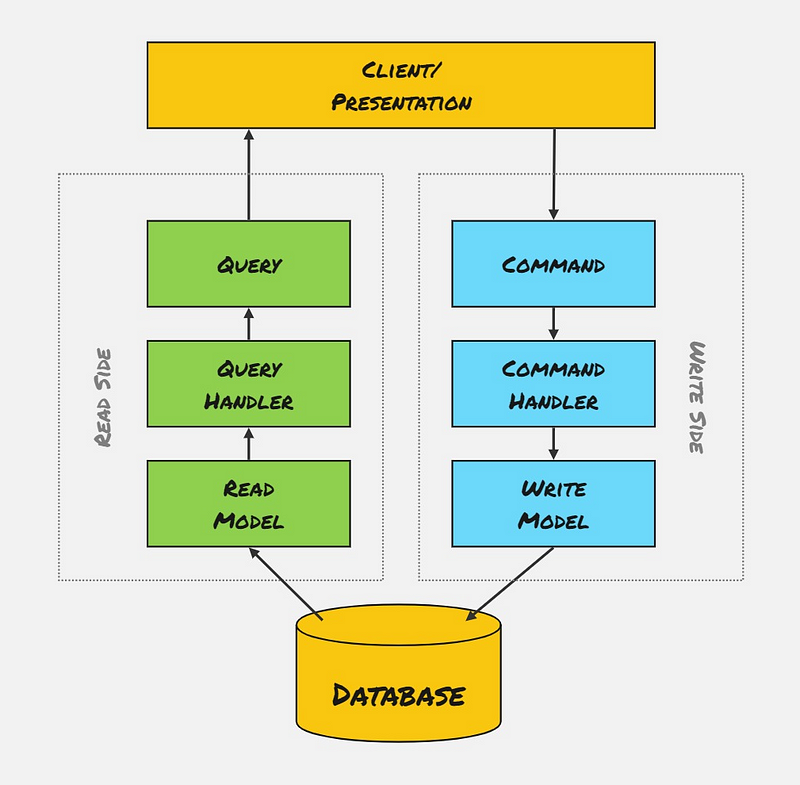
Different Read/Write Models, Single Database
Using different Read and Write Models allows us to optimise each side slightly differently, generally for performance. Our options on either side are fairly limited since we use the same database for Commands and Queries.
- Consistency: Strong
- Complexity: Low/Medium
- Performance/Scalability: Medium
We have a few options on each side now. We could use a heavier ORM for writing data and something lightweight for querying data. Here, we use different classes to represent our Write/Read sides, and we could even use completely different database tables or views if we like.
Generally, something more involved, like Domain-Driven Design, would be used on the Write side, and much simpler DTOs with no business logic would be used on the Read side. The Read models should be optimised for faster serialization and querying, so there should be little or no mapping being performed.
Since we still use a single database, we can commit Write and Read model changes in a single atomic transaction to ensure consistency. This style still keeps things simple but lets us optimise our Queries slightly better.
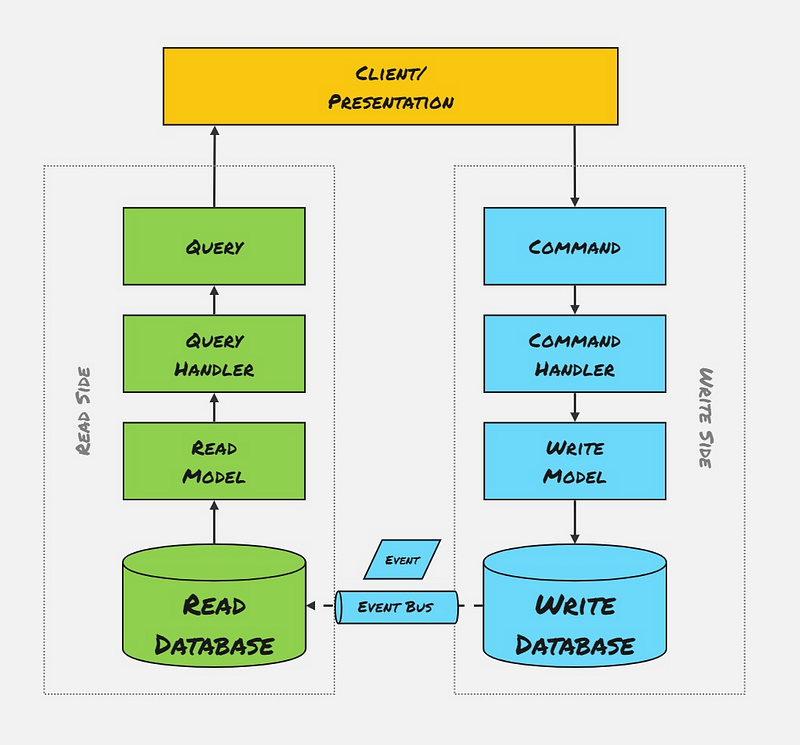
Different Read/Write Databases
This is where things get really interesting, and a lot more complicated! This setup is also what people generally think of when they talk about CQRS.
Using different databases for Read and Write means we can use a Polyglot Architecture, where we pick a database that perfectly fits the problem on each side. The choice of databases will completely depend on your team and app requirements.
You might want to use something simple and cheap like S3 Buckets for the Write side and something with better query support on the Read side, such as Elastic Search. A relational SQL database may fit better on one side and a NoSQL database on the other. Depending on data access patterns, we can also scale each side completely independently.
- Consistency: Eventual Consistency
- Complexity: High
- Performance/Scalability: High
Whilst this may seem like The Holy Grail of Architectures, the price we pay is huge complexity and weak consistency. Since different databases are being used, we cannot commit changes to our Write and Read models in a single atomic transaction. Generally, changes to the Write models are propagated to the Read Models using asynchronous messaging/events, providing Eventual Consistency.
We must contend with problems like: What happens if events propagate out of order? What if we lose events? What if our Read Models become out of sync? What if saving the Read Model fails? How does the UI know when Read Models have been updated after a write so they can be queried?
This style of CQRS is compelling but extremely complex to build and manage. Battling with the CAP Theorem and managing distributed transactions is one of the hardest problems in software engineering! This option should only be chosen if the non-functional requirements of your app require it.
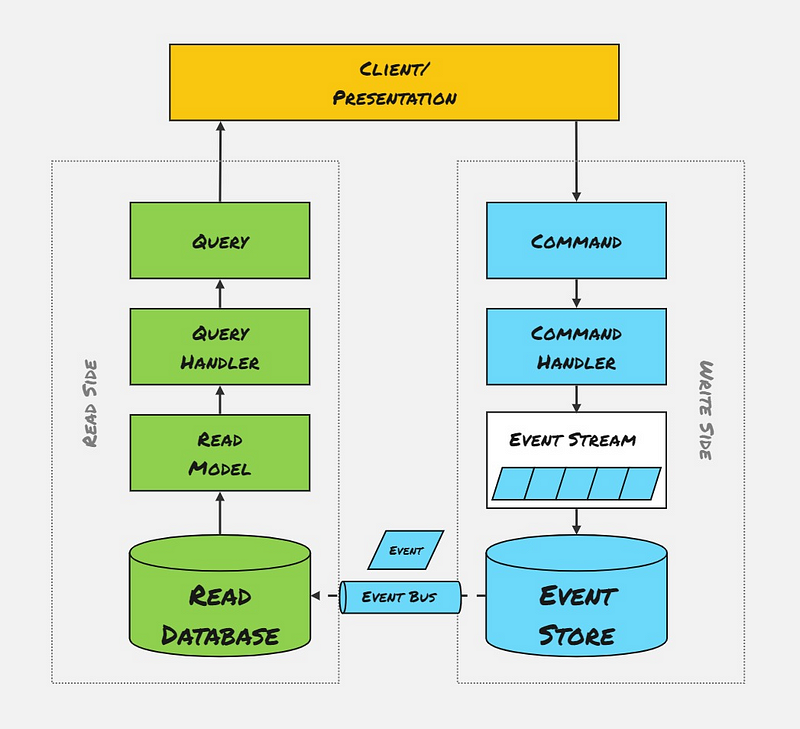
Event Sourcing — Different Read/Write Databases
It can be challenging to keep everything in sync when using separate Read/Write databases and Eventual Consistency. The order of events published from the Write to the Read side becomes really important.
Imagine that the same Write Model instance is updated twice in close succession. If the first update event is delivered after the second event, our Read model may be updated with stale data.
Unfortunately, most asynchronous Message Buses are built to be highly available and performant — this means they do not guarantee that messages will be delivered in the same order they are published. Event Sourcing can help us with this problem by taking a completely different approach to storing our Write Models.
- Consistency: Eventual Consistency
- Complexity: High
- Performance/Scalability: High
Instead of storing the current state of a model, append-only event stores are used to record the full series of actions taken on a model. When a new Command occurs, the current state of the Model/Entity is ‘rehydrated’ by replaying all of the events that have ever happened for that instance.
Each model instance on the Write side is stored as its own independent ‘Event Stream.’ The stream of events can be replayed at any time to materialise different views of the data. If the Read side gets out of sync, we can query all of the events from the Write side and rebuild our models.
As well as helping manage the consistency problem, Event Sourcing also provides some other benefits. We don’t need to implement complex audit processes anymore since our Event Streams already contain everything that has ever happened to each Model/Entity instance. If we decide that additional Read Models are needed in the future, we can replay the events to generate them.
Event Sourcing provides a really powerful and flexible way to model your data, but it is, again, even more complex to take on. If you have never used CQRS, Event Sourcing, or distributed architectures, then starting here is very ambitious.
Event Sourcing — Single Database
If you want to leverage the benefits of CQRS and Event Sourcing but don’t have huge scale requirements, then this can be a great place to start! Using the same database to store your Event Streams and materialised Read Models means we can eliminate all our consistency woes by committing both in a single transaction.

- Consistency: Strong
- Complexity: Medium
- Performance/Scalability: Medium
If you are using a schemaless NoSQL database, then storing the Event Streams and Read Models is easy. If you are using a relational database, you can store your Event Streams as text in a JSON format.
No matter what type of problem you are solving, there is a flavour of CQRS that can work well for you. The non-functional requirements of your system should drive the decision on which to use. Start simple and change if your scale requires it. As with most software problems, it is best not to optimise too early.





