
Chi Square Test — Intuition, Examples, and Step-by-Step Calculation
The best way to see if two variables are related
You’ve probably heard of the term “Chi square test” at least once in your life if you have ever studied for the SAT, or worked in some science-related field. Chi-square test is used a lot in corporations, especially when making decisions involving, for instance, medical, product design, engineering, and nearly all research projects.
For you to understand what the chi square test is, you need to first know what hypothesis testing is. Because the chi square test is one type of hypothesis test. I know it’s a little frustrating to have to know all these previous concepts before even talking about the chi-square test, but it’s impossible to learn math concepts without first understanding what came before them. But once you know what hypothesis testing is, you will be able to build on that foundation to understand many different kinds of hypothesis testing, for example, chi-square test, t-test, Z test, Wilcoxon’s test, etc.
I think all these fancy terms (e.g. null/alternative hypothesis, type 1 error, type 2 error, degrees of freedom, p-values, etc.) make the chi square test sound a lot more complicated than it is. But the basic idea of hypothesis testing is quite simple and straightforward.
What is Hypothesis Testing?
Hypothesis testing is a statistical analysis that looks at samples and sees if the test results from the samples can be applied to the whole population. Because samples are only a small part of the whole dataset, the test results based on them will always have some uncertainty. Meaning that any test results from the samples could be a complete coincidence due to the random nature of sampling. Hypothesis testing is an art of managing that random noise and still being able to draw conclusions with a certain amount of confidence.
Here are some terminologies: A sample is a smaller and therefore more manageable subset of a larger group, which is the population. A population is the entire data that you want to draw conclusions about.
Let’s try to make a picture story in our heads so we can recall this concept naturally later. When we have a good example in our head, we don’t have to try too hard to memorize the concept. And we will also remember it longer. We will learn all the formal terminologies along the way. So let’s put the terminologies aside and look at the idea first.
Hypothesis Testing — An example
You are Steve Jobs from 2007 and you are developing the first iPhone. (cool!) And you want to tell everyone that the iPhone battery lasts 24 hours. This is a serious promise to the customers, so you don’t want to be wrong.
You flew to China and started measuring the battery life of iPhones at the factory. Obviously, you can’t test every single iPhone on the assembly lines, so you sampled a few to test. Interestingly, the average battery life of the samples was different every day. Some days it was 24.5 hours, some days it was 23.7 hours, etc. Moreover, the number of samples varied from day to day as well. Because when the production volume was low, so was the sample size. And, as you may know, the mean is just a number, so when comparing yesterday’s mean to today’s mean, there’s no way to know how many samples were used to get that number. So when the average battery life looks really good, there is a chance that the sample size that day was just too small. And vice versa.
In this case, how can Steve Jobs (YOU) be sure of the battery life? How will you know that the mean is different today because of random sampling, and not because of the actual differences?
This is where we should use hypothesis testing.
Using hypothesis testing, we will be able to tell if the battery lasts for 24 hours or not, from the samples, with a certain amount of confidence. (e.g. 95%, 99%, etc.)
Hypothesis Testing — Details
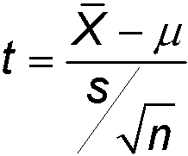
The example I just gave is a one-sample test. In a one-sample test, you compare a test statistic (such as Eq. 1 above) to a fixed number (e.g. 24 hours). Then you compute the p-value from this test statistic (if you don’t know what p-value is, please go ahead and read this blog. P-value is outside the scope of this post, but it is a foundation to understand the chi square test.) and decide whether or not the sample mean is equal to your hypothetical population mean.
If you look at Eq.1, the test statistic takes into account the number of samples (n). So, by using hypothesis testing, we can take into account the varying number of sample sizes every day.
Then, what would be a “two-sample test”? In a two-sample test, there will be literally two different samples. For example, you would compare the battery life of iPhones to that of Samsung Galaxies. Almost all hypothesis tests will have both one-sample and two-sample versions.
There are three essential steps in hypothesis testing that we haven’t gone into detail yet, and they are:
1. Set up the three things: Remember these three things. A null hypothesis, an alternative hypothesis and a significance level (α).
- i. Null hypothesis
First of all, why is it called a null hypothesis?
The term “Null hypothesis” comes from the nature of the scientific test. The null hypothesis assumes there is NO relationship between the two groups (in a two-sample test) or the population mean is NOT different from some predefined values (in a one-sample test). It’s set up this way because scientists must always be skeptical and careful about what they find. Scientists can’t get too excited about something that doesn’t have enough evidence and tell everyone that it works. It’s called a “NULL hypothesis” because it assumes any differences observed during an experiment are merely the result of random chance. That null is our default. So that’s why we start with the null hypothesis.
The null hypothesis is presumed to be true until the data shows enough evidence that it is not.
[Examples - How to make a Null/Alternative Hypothesis]
# One Sample Test
Research Question: Does the COVID vaccine prevent infections?
H0: The vaccine does NOT change the rate of infection. (Then set the infection rate at its current constant.)
H1: The infection rate ≠ The constant
# Two Sample Test
H0: There is NO difference in battery life between the iPhone and the Galaxy.
H1: there is a difference in battery life between the iPhone and the Galaxy.- ii. Alternative hypothesis
It’s also called a research hypothesis. If the alternative hypothesis is true, then it is considered a surprising discovery. So usually it’s an interesting idea that we secretly hope is true. But we downplay it by calling it just an “alternative”.
We structure the null and alternative hypotheses in a way that only one can be true.
- iii. Significance Level
It is also known as alpha (α). It is the value that YOU can specify, such as 1%, 5%, 10%, and so on. Think of it as how much you would favor the alternative hypothesis. More methodically, it is the probability of rejecting the null hypothesis when it is actually true. For example, if you set the alpha to 1%, you are not favorable to the alternative hypothesis. But if you set the alpha to 10%, you are more open to accepting the alternative hypothesis because you are rejecting the null hypothesis more easily.

2. Calculate the p-value from the test statistics
We’ll cover this in the next section.
3. Reject or fail to reject (notice I didn’t use the word “accept”) the null hypothesis based on the p-value and the significance level.
If your p-value falls within the significance level, you will be able to reject the null hypothesis.
The U.S. criminal justice system uses the same idea; “Innocent until proven guilty." The null hypothesis will never be proven true; you just fail to reject it.
Hypothesis testing is one of the most important concepts in statistics. It is used so frequently in everyday life, such as A/B testing of products, FDA drug approvals, clinical trials, etc., to help companies make sound decisions. Hypothesis testing gives us a solid framework to use smaller samples from a population in order to make decisions.
Why did they make the Chi Square test?
Ok. Now we know what hypothesis testing is. The chi square test is one type of hypothesis test. But why did this specific type of test (chi square) have to be invented?
In the above example of hypothesis testing, the goal was to see if the sample mean was equal to some constant (e.g. 24 hrs), which is the hypothetical population mean. The name for this test is “t-test,” and it is one of the simplest and most popular hypothesis tests.
The chi-square test is for another use. It is to see if one thing is related to another. For example, think about where people went to college and how much money they make. Are they related? What about voting preferences and age?
Step-by-Step Calculation of Chi-Square Test Statistics
Let’s get to the example with the data. I’ll use my favorite example, COVID data. And we will use the Chi-square test to see if certain COVID symptoms and admission to the ICU are related.
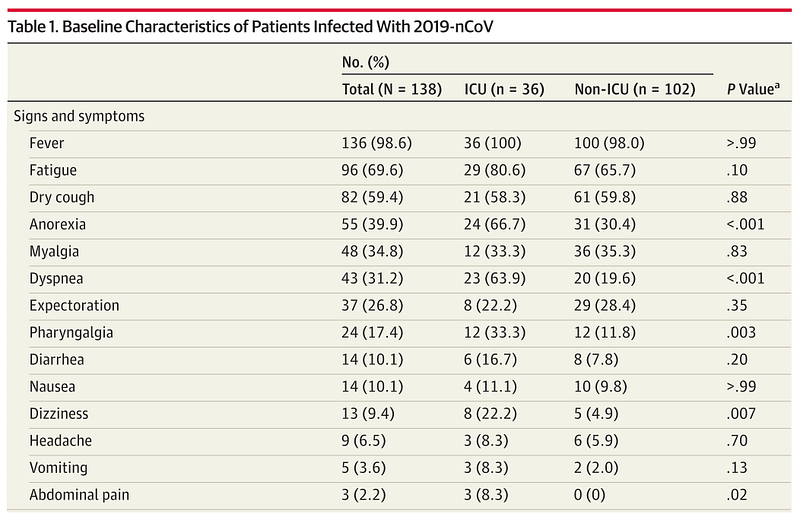
Chi Square Test — An Example

This table shows how many people with and without anorexia symptoms ended up in the ICU after getting COVID.
Let’s pause here and try to guess if they are related by just looking at these numbers in the table. What does your gut say? From a quick look, they seem to be related. Because out of total 36 people admitted to the ICU, 24 (67%) of them had anorexia. However, there are also people with anorexia (a total of 55) who did not get admitted to ICU (31, 56% of total anorexia). 🤔
So, how can we be sure that they are related?
We can be sure by using the Chi square test.
Chi Square Test — Details
So let’s chi-square test step by step.
As of January 2023, when I google “chi square test”, the first five results aren’t really what I’m looking for. They don’t help me get the gist of the idea. So I went to Wikipedia, but it doesn’t really answer my questions either.
So I ended up looking up my old textbook.
Basically, the steps are:
Step 1. Create the table, aka "Contingency Table" or "Observation O", from given data.
Step 2. Calculate the "Expected Value E" for each data point. (The intuition of chi square coming from this step.)
Step 3. Calculate (O − E)^2 / E.
Step 4. You get χ^2 (chi square) by adding up the values in Step 3.
Step 5. Get your "Degrees of Freedom".
Step 6. Calculate the P-value with Python or a calculator, or look up the test-statistic from the Chi-square probability table.Let’s get our hands dirty and see if these steps make sense.
Step 1. Create the table, aka “Contingency Table” or “Observation O”, from given data.
Step 1. Done.
Step 2. Calculate the “Expected Value E” for each data point. (The intuition of chi square coming from this step.)
How do I calculate the expected value? And what do we mean by “expected value”?
The Intuition of Chi Square Test
In the Chi-Square test, you compute the expected value for EACH data point. (This is important!)
How?
Like below.
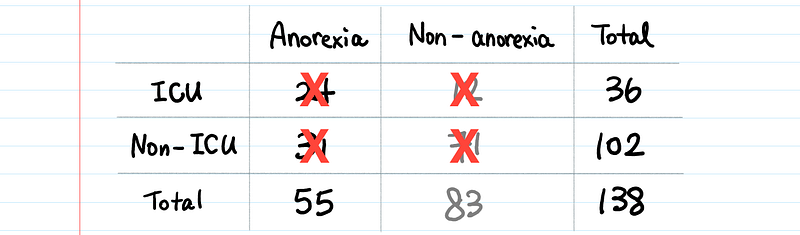

You will ignore the actual counts and use the “Total” columns and rows (ICU (36), Non-ICU (102), Anorexia (55), and Non-Anorexia (83)) to proportionately calculate the expected values.
In this example, by simply proportionating the totals, you can get the expected value of the cell [ICU, Anorexia] as follows: Out of a total of 36 ICU patients, 36 * (55/138) patients are expected to have anorexia.
Why do we calculate the E table?
Because if the actual observation (e.g., 24 for [ICU, Anorexia]) is a whole lot different than the expected value (36*55/138 = 14.35), then there is probably something going on between anorexia and ICU. On the other hand, when the observation is similar to what was expected, the percentage of patients with anorexia will be the same regardless of ICU or non-ICU. Then, it is likely that anorexia doesn’t have much of an effect on ICU admission.
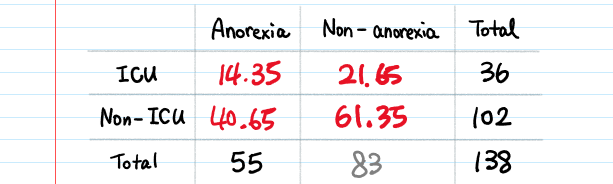
If you select some other symptoms from Table 1, for example, dry cough, the expected value won’t be too different from the observation. Try it out yourself.
Step 3. Calculate (O − E)² / E.
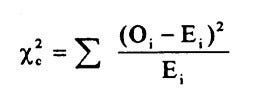
What does this equation mean? and why is this formula the test statistic for the chi square test?
HINT: The test statistic looks similar to a variance formula Σ(Xi-µ)²/n.
The chi square test statistic is basically the standardized sum of the squared differences between the observed and the expected values. It is standardized because it divides the squared differences by the expected values like any typical standardization. Basically, this test statistic tells you how much the observation deviates from what was expected.
You might say, "Okay, now I get the test statistic formula."
[❗Important❗] “But why do we use the chi square distribution to compute the P-value from the test statistic?”
Why do we believe that the test statistic will follow a chi-square distribution?
This, in my opinion, is the biggest missing piece from all of these Google/Bing/Youtube search results. Then, without explanation, this complicated distribution is thrown at us, and we have to use it blindly. 🤷🏽♀️
Here is the reason. 🤓
When Xᵢ is an independent standard normal variable, then the sum of those random variables X²
X² = X₁² + X₂² + … + Xᵥ²
follows the chi-square distribution with mean v and standard deviation of sqrt(2v).
Wait, Are our observation numbers (24, 12, 31, 71, etc.) independent standard normal variables?
They can be IF they follow a normal distribution. Because Any point (x) from a normal distribution can be converted to the standard normal distribution (z) with the formula z = (x-mean) / standard deviation.
Ok. Do our observation numbers (24, 12, 31, 71, etc.) then follow a normal distribution?
According to the Central Limit Theorem (CLT), if you take sufficiently large samples from a population (Sample sizes greater than 30 are generally considered sufficient for the CLT to hold.), the samples’ MEANS will be normally distributed, even though the population isn’t normally distributed.
Ok. Our obersvations (Xi’s: 24, 12, 31, 71, etc.) don’t seem to be an average of some other numbers. They are the data themselves. If that’s the case, why do we assume this will follow a normal distribution?
What if we could show the data points as a mean?
Let’s look at our contingency table. Give it a hard look. 🧐
Can you see a hint of Bernoulli’s trial here?
Yes. Because each variable (Anorexia and ICU) has exactly two possible outcomes, “Success” and “Failure”.
From a Binomial distribution standpoint, the total number of patients is n, and each ratio (36/138 for ICU success, 55/138 for Anorexia success) will be p.
And as n gets larger in the Binomial distribution, the Xi’s will follow a normal distribution with mean μ = np and standard deviation σ = sqrt(n*p*(1-p)).
This is called Normal Approximation to Binomial Distributions.
For the large enough n, the binomial distribution with n trials and probability p of success gets closer and closer to a normal distribution. The normal distribution will have the same mean μ = np and standard deviation σ = sqrt(n*p*(1-p)) as the binomial distribution.
Ok. Let’s connect the dots.
Now we know that the samples are taken from a normal distribution. Then, the (Observation — Expectation) value will also follow the normal distribution because E is a constant. Then it makes perfect sense to use Chi square distribution for the test statistic, since the chi square distribution is the sum of the squares of the k standard normal distribution.
This normal distribution assumption is often left out when the chi square test is taught, but this assumption is what makes the chi-squared test possible.
Step 4. You get χ² (chi square) by adding up the values in Step 3.

Chi-square test statistic: 6.49 +4.3 +2.29+1.52 = 14.6
Step 5. Get your “Degrees of Freedom”.
Every distribution has parameters. For example, the Normal distribution’s parameters are mean and standard deviation. The binomial distribution’s parameter is n & p, etc.
What parameter does the chi square distribution have?
It has the degrees of freedom, k.
What does the “degrees of freedom” mean? How does it work? Does it mean how much freedom I have? What a strange and confusing name…
To give you an easy-to-remember example, let’s say there are three random variables, x, y, z, and their mean is 5.
In this case, out of the three random variables x, y, and z, how many of them are actually random?
Only Two.
Why? Let’s say x and y have the freedom to vary. But then, in order for their mean to be 5, z has to be 15 — x — y. Therefore, z doesn’t have the freedom to vary.
Now let’s apply this to the chi square’s degrees of freedom.
You can think of the degrees of freedom as the number of independent pieces of information that are used to calculate the test statistic.
In our case, we have a 2 by 2 contingency table. And we know the total number of samples (fill it). What is the df in this case? It’s 1. Why? Because once you know one number in a 2 by 2 table, the rest of the cells in the table are set, GIVEN THE TOTAL.
Let us turn this concept into a formula.
For a contingency table with r rows and c columns, the formula for calculating degrees of freedom for the chi-square test is:
Degrees of Freedom = (# of rows − 1) × (# of columns − 1)Is this a reasonable generalization? I believe so.
Why do we need to take degrees of freedom into account?
Because the degrees of freedom affect the shape of the chi square distribution. So, it affects your decision about whether or not to reject your null hypothesis.
Step 6. Calculate the P-value with Python or a calculator, or look up the test-statistic from the Chi-square probability table.
The final step is to calculate the P-value. Many p-value calculators are available online. One good example is: https://www.di-mgt.com.au/chisquare-calculator.html
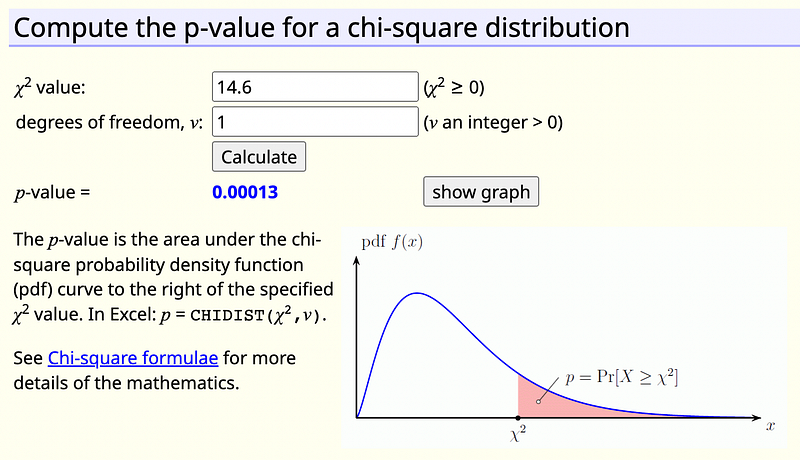
Or, using Python, it only takes a few lines to compute the P-value.
from scipy.stats import chi2_contingency
table = [[24, 12], [31, 71]]
alpha = 0.05
test_statistic, p_value, dof, expected = chi2_contingency(table)
if p_value <= alpha:
print('Variables are not independent (reject H0)')
else:
print('Variables are independent (fail to reject H0)')You might have learned the chi square probability table in school. The values in this table are not the p-value. They are the test statistics of the chi-square distribution based on the different degrees of freedom and alpha. You need to compare the test statistic you calculated with the numbers in this table.
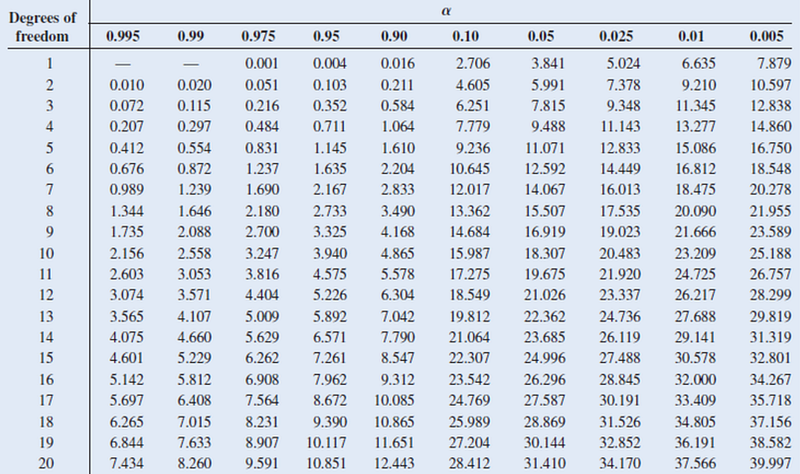
One important takeaway from this classic table is that the chi-square test can be particularly sensitive to sample size. Look at the bottom left corner (7.434 for 20 df / 0.995 alpha) and the upper right corner (7.879 for 1 df / 0.005 alpha). Their test statistics are comparable. This means that, given a big enough sample size, even insignificant connections might appear to be statistically significant.
So, this is it. We just calculated the chi-square test statistic by hand.
After this step, we will just follow the standard steps of hypothesis testing, which are rejecting or failing to reject the null hypothesis based on the p-value and the significance level, alpha.
There are only two possible results from this step.
1. The p-value is smaller than the alpha. We can reject the null hypothesis.
2. The p-value is bigger than the alpha. We can’t reject the null hypothesis in this case.
If you’re not sure what a p-value is, I recommend reading this.
I’ll leave you with one last thought.
You can use hypothesis testing in so many different ways in your everyday life, and it’s actually fun to do so. For example, your hypothesis could be that “taking vitamin C keeps me from getting a cold." Then you start counting how many times you get a cold after not taking vitamin C for X days. I know that it’s not a completely controlled test, but it’s fun to do it!
I think you should write down three of your own null hypotheses today.
Special thanks to people who reviewed this blog post: Joshua Moore at Snap, Federico Vaggi at GoogleX, Calliea Pan at Twitter, Mike Walmsley at UManchester, and Axel Kuhn.
Their feedback was very valuable, and it all made my blog much better than it was before.





