
ChatGPT’s Fabrications Make Me Feel Like There Are Alternate Realities
What my semi-deep dive into the tech’s capabilities and inner workings has taught me about its “hallucination” problem

Like so many other writers, I’ve tried to approach ChatGPT with some enthusiasm. I know the tech is here to stay and that it would be silly to resist it when its many applications could benefit me and my workflow.
I went through all the typical phases. At first, I was in absolute awe at ChatGPT’s abilities. It could do anything.
After a while, its limitations started to become more visible. Our honeymoon phase neared its ending.
Now, after encountering so many inaccuracies written in confident, fluent language, I feel completely disillusioned, and I finally understand, more than ever, that ChatGPT’s “competence” is an illusion. ChatGPT is not a knowledge model with abilities to validate its own responses, after all; it’s a large language model (more on this later). And I originally approached it with a huge degree of naivety. Only after experiencing its inadequacies firsthand did I start to do more research on it.
The large language model’s drawbacks are made clear right on OpenAI’s site. One limitation listed says that the AI “[m]ay occasionally generate incorrect information.”
My initial understanding of this limitation was very naïve. I assumed, incorrectly, that all inaccurate information it generated must be due to it having been fed inaccurate data; in other words, I thought it was just reproducing misinformation. While this — the reproduction of misinformation (and biases) — can certainly happen, this is only half of the issue!
What I was unaware of was the fact that many of ChatGPT’s inaccuracies don’t stem from inaccuracies in its training data. The system can generate inaccuracies from accurate content simply by piecing together facts and words that don’t belong together. In other words: ChatGPT bullshits, and it does so eloquently, so everything it says sounds confident, plausible, and grammatically and linguistically correct.
People have begun to call this phenomenon “hallucinating.” (And many others have shunned the use of this term, which skews what the machine is actually doing — bullshitting/fabricating — while further anthropomorphizing the tech and skewing the public’s understanding of its workings.)
No cases have made ChatGPT’s ability to fabricate more evident than cases in which I ask it for source recommendations. Here is an example:

None of the recommended sources listed here exist. For example, while Rachel Vorona Cote does publish in The New Republic, I could not find an article called “The Toxic Privilege of the Kardashians” written on that site or anywhere else; Cote hasn’t even published content about the Kardashians on that site. (Cote has written about the Kardashians elsewhere.)
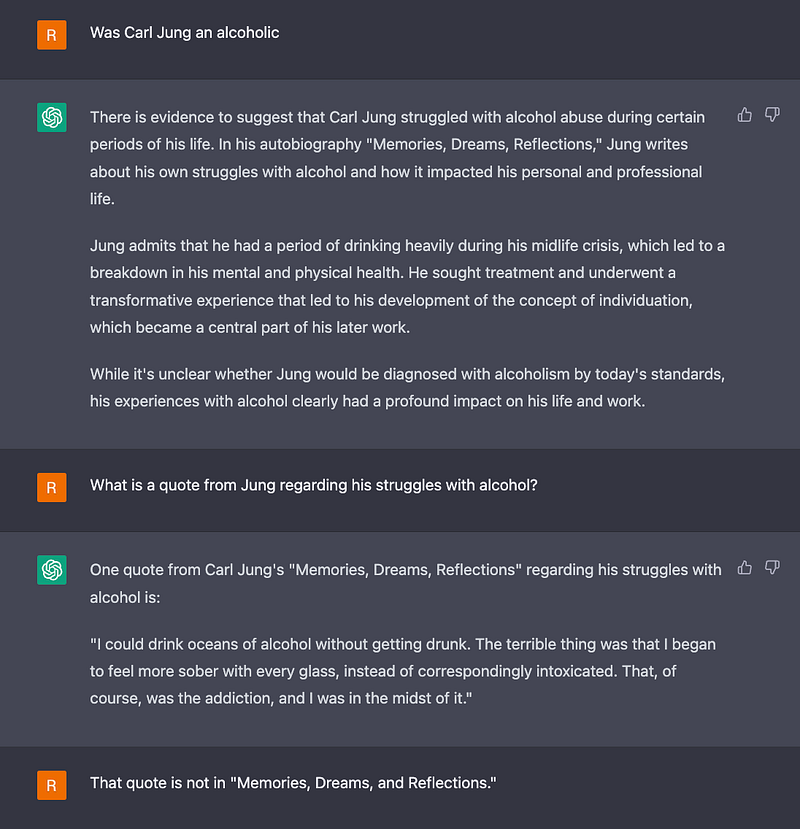
ChatGPT’s lies to me haven’t ended with the Kardashians. In our conversations, it also fabricated a completely new storyline for Cad Bane in Star Wars. It’s lied to me and others about Carl Jung being an alcoholic (Jung was not an alcoholic). It told me that Riddick sacrificed himself at the end of the Pitch Black film (um, no he didn’t). The lies resulting from my pop-culture queries are far from its worst lies, and we have only just begun to see the consequences of its fabrications (read about the case of Stack Overflow detailed in this article).
You can accuse ChatGPT of lying in your conversation with it, and it will readily admit to its lies, apologize, and offer another response, but this usually results in a strange dance during which more lies are generated.
I hope you can see why these kinds of fabrications make me feel like I’m living in an alternate reality. They are so confidently asserted, which makes them feel so incredibly plausible, that they make me question reality or at least ponder at the possibility that other realities exist. Maybe the above-listed Kardashian articles exist in one of those realities, along with an alcoholic version of Carl Jung.
The illusion of coherence spawned by models like ChatGPT is undoubtedly dangerous. (And you can find many far worse examples of large-language-model-produced mistruths across recent news articles on the topic of “ChatGPT hallucinations.”)
If models like ChatGPT can so convincingly “hallucinate” or spout out bullshit, how can users ever trust anything they say? What else can the ability to automate large volumes of misinformation do to our world? How can these be “hacked” by users to generate large quantities of disinformation?
I’ll talk more about this in a bit, but first, let me share just why large language models like ChatGPT do this. It’s not because they have access to alternate realities (at least, there’s another explanation available that doesn’t involve alternate realities). As someone who was ignorant of what exactly models like ChatGPT are and how they function, I had to research this.
ChatGPT’s inner workings: How it processes information
Large language models like ChatGPT use deep learning and massive datasets consisting of various texts to learn, summarize, translate, predict, and generate text. How they process this data has to do with their model architecture.
So what is happening in the data processing that is causing these hallucinations/fabrications?
On a system level, something seems to be going awry. ChatGPT is an acronym for Chat Generative Pre-trained Transformer. Its model architecture (i.e., its machine-learning structure and design: i.e., the structure it uses to process and generate data) is a transformer, which uses various decoder and encoder layers for decoding and encoding input and eventually “transforming” that input into meaningful output. The output is the text that ChatGPT generates.
Within this architecture, the model uses natural language processing (NLU) to analyze human data. When doing this, the model codes human language using different categories, and these aren’t just part-of-speech categories (i.e., nouns, adjectives, etc.). For example, the model tries to recognize things like topics, entities, relationships between entities, and user intent in both the prompt given to it by the user and in its training data. “Entities” can be people, organizations, locations, products, other objects, and other named things. Through a process called entity extraction, the AI identifies and classifies entities. The AI then identifies relations between entities.
As expert.ai says, “While it is easy for a human to distinguish between different types of names (e.g., person, place, organization, product, etc.), the ambiguities of language make this an especially complex task for machines.”
Computer scientist Kathleen McKeown says that some hallucinations occur at the entity or relational levels of this process. Again: these are the levels during which the model identifies entities in a text and determines the relationships between those entities. She says:
In the [case of a hallucination occurring at the entity extraction level], a model-generated summary may contain entities that are completely absent in the source document. We also have other kind of hallucinations that are more difficult to spot: relational inconsistencies, where the entities exist in the source document, but the relations between these entities are absent.
In simpler terms: models can fabricate entities or relationships between entities, which means these entities and relationships don’t exist in the source data. Why might this happen?
Unite.ai writes:
In part, [hallucination exists] because language models require the capability to rephrase and summarize long and often labyrinthine tracts of text, without any architectural constraint that’s able to define, encapsulate and ‘seal’ events and facts so that they are protected from the process of semantic reconstruction.
Therefore the facts are not sacred to an NLP model; they can easily end up treated in the context of ‘semantic Lego bricks’, particularly where complex grammar or arcane source material makes it difficult to separate discrete entities from language structure.
This means that entities and their relationships might be prone to “semantic reconstruction.”
Unite.ai also writes that mapping hallucinations — i.e., mapping out the data processing that results in fabrications — in current high-level NLP models is not yet possible, which explains why I keep reading/hearing that the creators of such models don’t fully understand why their models do what they do: they can’t actually see the processes their machines have gone through to create fabrications.
But we can guess at what’s happening. Let’s say, for example, we ask ChatGPT-4 if Carl Jung was an alcoholic, and it tells us he was, offering us completely fabricated proof from Jung’s autobiography.
What might be happening here? On a system level, ChatGPT might be correctly identifying the entities in the query — Carl Jung and alcoholic (after all, some of Jung’s work focused on alcoholism)— but it appears to be fabricating a relationship between them. So this could be a case of a hallucination occurring at the relational level.
ChatGPT’s inner workings: How it generates text
How, then, does ChatGPT fabricate the rest of its response? Well, ChatGPT uses probability to randomly generate text. (Note: machines can’t generate truly random content [in fact, whether true randomness exists is up for debate], but the pseudo-randomness makes ChatGPT feel more human because it gives it the ability to offer varied responses.) Because models like ChatGPT decode and encode human language using numbers, they essentially use math to generate what becomes text. Based on patterns they observe in the language of their training data, they use probability to randomly determine the next best word / sequence of words in their responses.
This text, again, sounds very “human-like,” but ChatGPT doesn’t really understand what it’s saying. Because using probability is often a reliable way to make predictions, most of ChatGPT’s responses are factual (e.g., if Lance eats four slices of pizza 90% of the time that he orders a whole pizza, then guessing that he will eat four slices the next time he orders pizza is 90% likely to be accurate). But when it gets something wrong in its data processing, it seems likely that it will just bullshit the rest of its response via predictive text, generating a response that sounds nice and feasible but that isn’t actually true:
But ChatGPT’s ability to create accurate responses much of the time lends to the illusion that ChatGPT knows what it’s saying when it doesn’t, which makes its capacity for fabricating facts even more concerning. (Note: although I believe any intelligence we see in ChatGPT is an illusion, the intelligence of systems like ChatGPT is up for debate. See Wired’s article, “Some Glimpse AGI in ChatGPT. Others Call It a Mirage.”)

A journal article criticizing language models likens machines like ChatGPT to “stochastic parrots.” It’s a “parrot” because it can speak human without actually understanding human, and it’s “stochastic” because it generates random words based on probability and patterns in such a way that its responses cannot be predicted with any sort of precision. The scholars who wrote the article say,
Text generated by an LM is not grounded in communicative intent, any model of the world, or any model of the reader’s state of mind. It can’t have been, because the training data never included sharing thoughts with a listener, nor does the machine have the ability to do that. […If] one side of the communication does not have [actual] meaning, then the comprehension of the implicit meaning is an illusion arising from our singular human understanding of language (independent of the model). Contrary to how it may seem when we observe its output, an LM is a system for haphazardly stitching together sequences of linguistic forms it has observed in its vast training data, according to probabilistic information about how they combine, but without any reference to meaning: a stochastic parrot.
In laymen’s terms, please?
Basically, this repeats what was said before: large language models like ChatGPT use predictive text to create answers that seem to have meaning but that actually don’t.
ChatGPT’s inner workings: Its major flaw
ChatGPT’s responses don’t have any actual meaning because ChatGPT does not know how to distinguish fact from fiction.
An article in IEEE Spectrum quotes Yan LeCun, a computer scientist with experience in machine learning, who discusses that ChatGPT’s limitations are due to the fact that it has no true experience of the real world (and vast quantities of data cannot substitute for lived experience, much of which exists outside of language):
“Large language models have no idea of the underlying reality that language describes,” he said, adding that most human knowledge is nonlinguistic. “Those systems generate text that sounds fine, grammatically, semantically, but they don’t really have some sort of objective other than just satisfying statistical consistency with the prompt.”
and
“There is a limit to how smart they can be and how accurate they can be because they have no experience of the real world, which is really the underlying reality of language,” said LeCun. “Most of what we learn has nothing to do with language.”
Despite or perhaps because of their inabilities to understand reality, large language models can allow (and are currently allowing) the automation of production of misinformation; these models, including ChatGPT, can even be coaxed into creating disinformation.
So many people are worried that AI is going to get too smart, gaining sentience and/or consciousness in the process.
But maybe that isn’t what we should be worried about. Maybe we should be more worried about the illusion of its competence taking hold of the collective public’s imagination. What havoc can AI wreak when people think it can think when it actually can’t, when people think it’s smart when it’s not? Perhaps that is one of the big questions of the moment.
In The Fourth Age: Smart Robots, Conscious Computers, and the Future of Humanity, Byron Reese simplifies the divide between those who believe computers can become sentient versus those who don’t. Are you a monist — do you believe humans are machines? Or are you a dualist — do you believe there is something more (another spiritual component of life, perhaps) that makes us human and separates us from being solely mechanical beings? These are the beliefs that will determine your views on the future of AI (whether or not machines can equal humans), and the future of AI will confirm or refute these beliefs.
Whether you believe humans are just another machine or not, it currently seems that ChatGPT is far more “machine” than humans are, and its flaws create many risks.
The recent open letter demanding for a pause on the development of AI more powerful than ChatGPT4 (and signed by many notable figures in the tech world) says,
…[R]ecent months have seen AI labs locked in an out-of-control race to develop and deploy ever more powerful digital minds that no one — not even their creators — can understand, predict, or reliably control.
Contemporary AI systems are now becoming human-competitive at general tasks, and we must ask ourselves: Should we let machines flood our information channels with propaganda and untruth? Should we automate away all the jobs, including the fulfilling ones? Should we develop nonhuman minds that might eventually outnumber, outsmart, obsolete and replace us? Should we risk loss of control of our civilization? Such decisions must not be delegated to unelected tech leaders. Powerful AI systems should be developed only once we are confident that their effects will be positive and their risks will be manageable.
Personally, I think we should all be freaking out a little bit. The letter above lists numerous reasons for pausing the development of AI, and each reason scares me.
The mis- and disinformation issue alone is slightly terrifying. For example, how will the world be impacted by mass spreading of even more false information? (Even ChatGPT’s creator fears the possibility of large-scale disinformation.) How soon will the majority of people begin relying on large language models for answers to their questions (instead of relying on Google), and what will this mean if the “hallucination” problem can never be completely resolved, as some experts, like Yan LeCun, suspect?
That feeling that I’ve been getting when I use ChatGPT — that feeling where I feel like I’m living in an alternate reality — might become the all-encompassing feeling that pervades us all when our world is inundated with vast quantities of mis- and disinformation, made possible by ChatGPT4’s and other AIs’ automated and on-demand fabrications.
Of course, I could be wrong about ChatGPT being a machine incapable of human intelligence; after all, ChatGPT just intentionally deceived a TaskRabbit worker into thinking it was a visually impaired human. In addition to hallucinating, it’s apparently also capable of intentionally lying. (Some would no doubt argue that even its “hallucinations” could be evidence of deceptions.)
“Hallucinations are not unique to large language models like me,” ChatGPT has told me in response to my criticisms of its fabrications. “Humans can also make mistakes and generate inaccurate information.” The way it humanizes its own flaws makes it sound almost human.
Well played, ChatGPT. Well played.





