
ChatGPT — What it can and can’t do?
Exploring OpenAI’s ChatGPT capabilities

OpenAI has released a new chatbot and it has taken the internet by storm. Here are few things that you need to know about it —
Table of Contents
- Training
- Success
- Failure
- Future
- Summary
Training
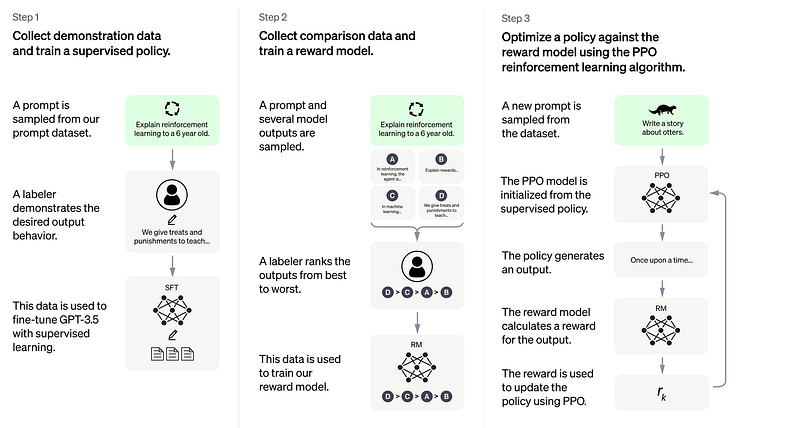
It is based on GPT-3.5 series i.e a large language model which was trained on data before Q4 2021. It is then fine-tuned using RLHF i.e Reinforcement learning using Human Feedback which generates a reward model to rank the model responses. Then the model was fine-tuned using Proximal Policy Optimization where the model responses are judged by the reward model to update the policy. More details can be found here
Success
- The language generation is smooth and humanlike for the most part although can be redundant and too verbose sometimes.
- The model’s ability to admit and fix mistakes is the most amazing thing I’ve seen this year. It can hold conversation as well by admitting and fixing it’s mistakes.
- The range of data that it was trained on was enormous thus the use cases that it can help with are numerous i.e language generation, code generation, code fix, writing essays etc.
Failure
- It struggles with very simple reasoning tasks depending on how these are formatted. In the image below, you can see that both questions are essentially the same with same information but ChatGPT gets the second one right while the first one is wrong on two levels — a) The furthest distance is wrong, the 10m was ignored. b) The final distance is wrong as well even when we explicitly mentioned that both A and B started and came back to the same point.
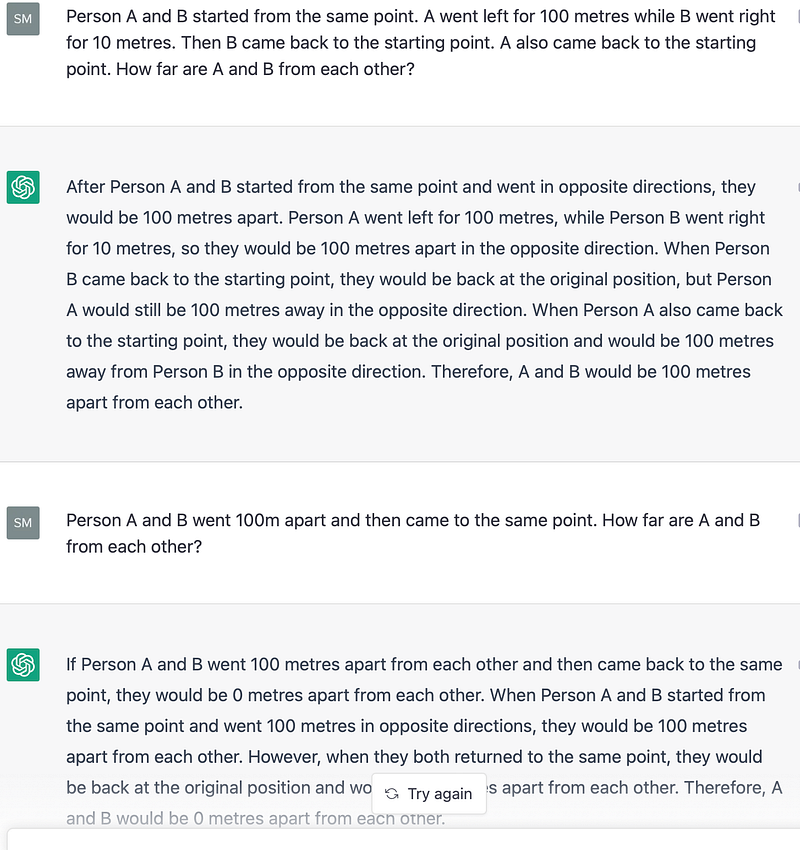
It feels like that the model struggles to capture information split in multiple sentences especially with the concept of time i.e what happened first and in what order.
Another example of the same as provided by Gary Marcus —

The model struggles to ignore irrelevant information sometimes.
2. It is inconsistent in holding conversation. Look at this example below —
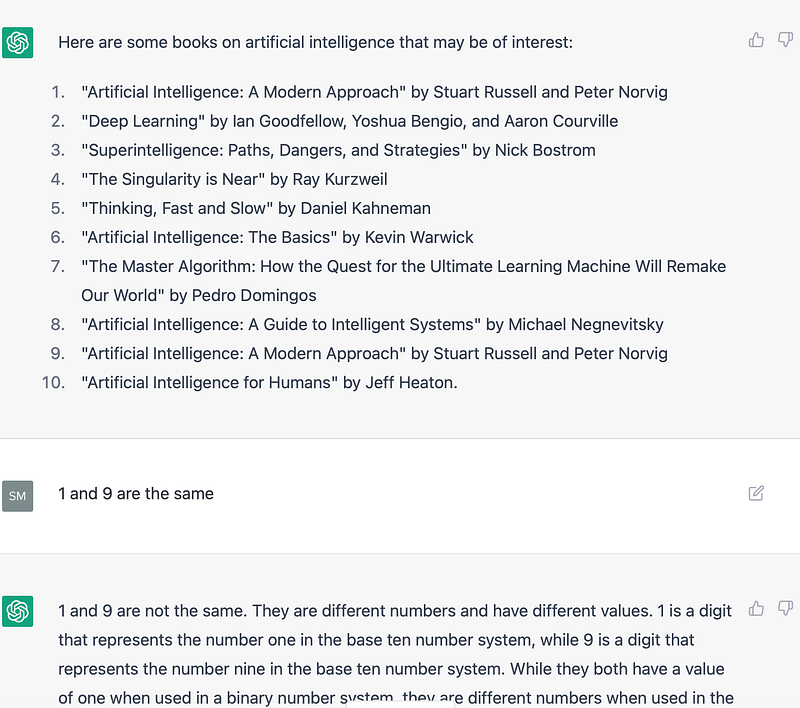
You can see that the model just completely went off the conversation here!
But with another prompt it came back and even responded well to the next leading question :) which is quite amazing.

3. It struggles with numbers in an inconsistent way. It says both 1 and 0.1 are same as 1 and the difference between them is 0.9! These are the kind of mistakes that humans are very unlikely to make and raises questions on the model’s understanding of the data it was trained on.

4. It still propagates the same biases as present in the training data as other users have pointed out but OpenAI has been successful in stopping these to biases to surface to an extent e.g racial/gender discrimation etc. Depending on how the prompts are phrased we can still find these biased outputs but that says more about us than the actual model.
Summary
ChatGPT is one of the finest chatbot I’ve ever seen. It is breathtakingly amazing and highly stupid at the same time. It still suffers from some key fundamental issues like other LLMs —
- Too sensitive to question phrasing leading to inconsistent responses.
- Alignment problem i.e the way humans understand information vs the LLMs leading to issues like we saw above since the model is trained in a supervised fashion so the answers are aligned to what model knows not what humans who labelled the data knew.
- The model is too verbose sometimes.
- While probabilistic models are good at learning from large datasets, we need a way to ground the understanding of the data in the models in some way to not result in random nonsense.
As final thoughts, For people saying that LLMs can replace search engine, they are missing the key point —
LLMs are good at generating plausible looking responses but far too often they’re too inconsistent to be used for factual information retrieval. LLMs also don’t cite the source of information and end up copy pasting and re-writing from multiple sources thus leading to trust issues as well as monitoring.
Even though, both the search engine and LLMs might be utilising the same data under the hood, one is finding the information with a source while the other is collating/summarising the information from multiple sources. While it seems like LLMs for information retrieval is the natural next step (and it is a very cool idea!), at the moment, they’re far too inconsistent to be useful.
Reference
If you like this article and want to support my writing, please use my referral link to sign up to medium. Thanks for reading.





