
中國 — 关于 ChatGPT 技术的一般文章
ChatGPT — LLM 模型(大型语言模型)
中國 — 了解 ChatGPT 的技术和应用。

ChatGPT — LLM 模型(大型语言模型)
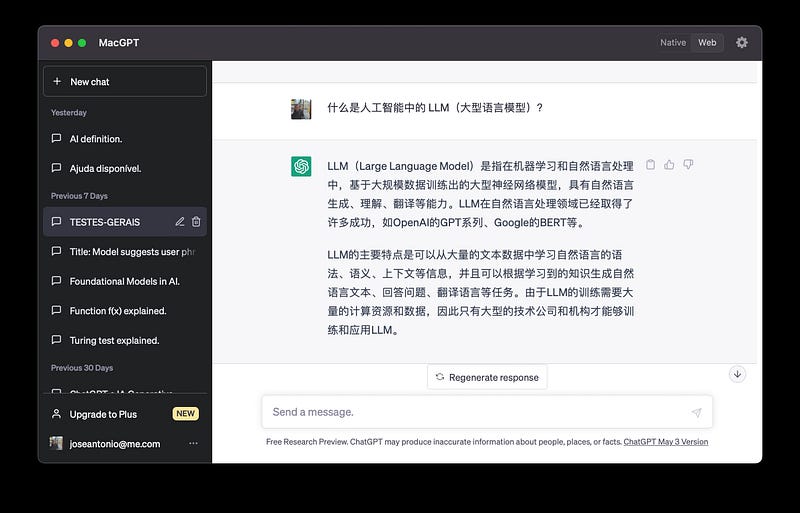
LLM(大型语言模型)是这些模型中最著名的。
用于使用自然语言处理 (NLP) 算法和称为 Transformers 的 AI 训练技术解决语言问题。
ChatGPT 使用这种从长文本字符串中获取含义的技术来了解不同的单词或语义组件可能如何相关,然后确定它们彼此相邻出现的可能性。
一款猜测较早学习的单词和短语的游戏,稍后再猜。
这些转换器在一个称为预训练的过程中在大量自然语言文本上无人值守地运行,然后由与模型交互的人类进行调整。
预训练是教授系统的地方,或者更确切地说,是它自己学习文本中单词之间关系的地方。
这些大规模模型导致了系统的发展,这些系统可以理解我们所说或所写的内容,或者更确切地说,可以从他们从人类那里学到的东西中产生知识。
使用这些模板的一个非常简单的例子是在键入消息时自动填写表格和手机。 该系统为您提供了备选词,供您在句子的上下文中进行选择。
我们正在谈论猜测下一个词或接下来的两个词。 LLM模型把这个概念发挥到了极致,有的可以看前后700个单词,有的远不止于此。
也就是说,他们试图猜测文本中接下来的 700 个单词。
这些系统越聪明,它们就能猜到越多的单词,或者更确切地说,可以统计地预测出正确的单词作为答案。
1 — 在各种人类活动中训练的模型
值得注意的是,只要经过适当的训练,这些模型就可以适用于所有类型的人类活动。
例如:
- 用著名艺术家的作品训练的系统可以按照这些艺术家的风格生成新的艺术作品。
- 受过数学或化学教科书训练的系统可以在这些领域产生具有新想法的结果。
- 接受辩护案例培训的系统可以学习和协作,以便在法官和法院中开发和解决案件。
我们可以看到,这些系统将在未来几年入侵世界,我们将在我们的教育、个人和职业生活中与其中许多系统互动。
出于这个原因,我们正在目睹一场主导和改进这项技术的竞赛,这项技术可能与互联网一样重要,并且可以带来社会变革,如农业、工业和技术革命。
2 — LLM 算法
LLM是一种深度学习算法,可以根据海量数据训练得到的知识,识别、归纳、翻译、预测和生成文本等内容。
这些文本模型不仅仅用于教授或翻译人类语言。
他们可以通过聊天机器人以文本格式回答问题,应用范围非常广泛,例如:
- 了解蛋白质、分子、DNA 和RNA。
- 编写计算机代码。
- 为图像生成器构建文本和图像对。
- 改进搜索引擎。
- 作曲、写诗、写故事、写书。
这些模型在推理、常识和问题解决等人工智能领域展示了强大的能力。
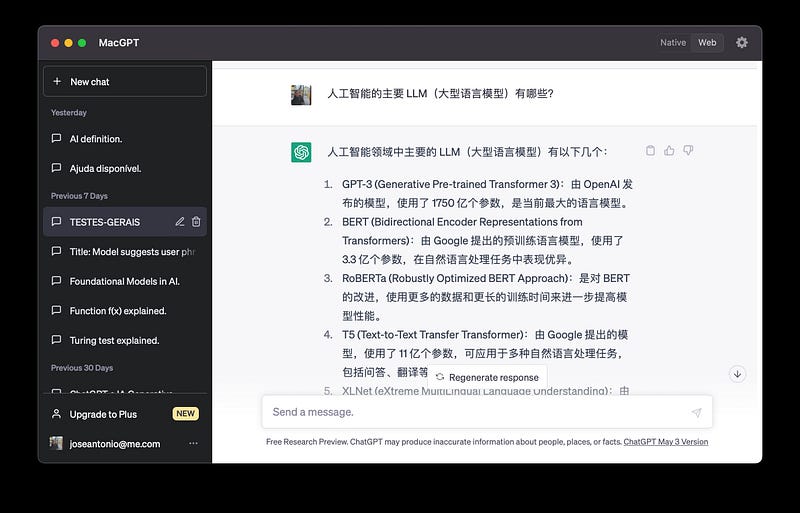
最受欢迎的 LLM 模型是:
- ChatGPT 中使用的 OpenAI 的 GPT(生成式预训练转换器)。
- CODEX by OpenAI 用于计算机代码生成。
- Microsoft 的 Sydney 基于 ChatGPT for Bing 构建。
- Bard 使用的谷歌LaMDA(对话应用程序语言模型)是谷歌的会话人工智能服务。
- Nvidia 的威震天。
- Facebook 的 RoBERTa(稳健优化的 BERT 方法)。
- 欧洲共同体的BLOOM(BigScience Large Open-science Open-Access Multilingual Language Model)由欧洲研究人员、政府和公司组成的联盟在巴黎地点的大型机上开发。
- 来自IsraeliAI21 的Jurassic。
除了最知名的,还有大量公司致力于开发 LLM 供自己使用,或在市场上将其商业化,例如百度、DeepMind、Meta、AI21 Labs、LG AI Research、Anthropic、华为、除其他外。
为企业本身或商业化开发 LLM 的竞赛现在正在进行,通过软件 API 提供对训练系统的访问,对访问或内容收费。
每个人都希望在生成人工智能市场中占有一席之地,因为他们知道这场革命将显着改变产品和服务以及我们的整个社会。
3 — LLM最受欢迎的模式
目前最流行的 LLM 模型是 ChatGPT 中使用的 GPT-3.5。
GPT-3.5 在 45TB 的数据库上进行训练,相当于超过 2.92 亿页的文档,或 4990 亿个单词。 它使用 1750 亿个参数(神经网络中输入层和输出层之间的连接点)。 它有 96 层注意力(神经网络算法)。
LLM 能发展到多大还不得而知。 据说新的 GPT-4 版本有 100 万亿个参数。 如果 GPT-3 很聪明,想象一下这个新版本。
参数数量的增长开始看起来像摩尔定律,它决定了计算机芯片上晶体管数量的指数增长。
由于规模、成本和专用硬件,这些模型最初是由大型企业、政府和初创公司开发的,它们获得了大型云公司的大量投资和支持。
4 — 投资开发生成式人工智能
生成式 AI 的世界仅限于资金最充足的参与者。 微软在 OpenAI 上投入了 100 亿,这是在已经完成的基础上。
由于没有人可以独自完成所有事情,因此在这个新市场中,我们几乎总是有以下两者的结合:
- 谁有意志和才能。 对于初创公司或敏捷技术公司(OpenAI、DeepMind、Stable Diffusion 等)而言。
- 谁拥有内容。 对于搜索引擎、百科全书、图书馆、书商等(Google、Microsoft Bing、Wikipedia、Meta 等)。
- 谁拥有云服务(AWS、Google、Microsoft Azure)等技术基础设施资源。
- 谁拥有硬件,在本例中为GPUS 制造商(Nvidia、Intel、AMD)。
谷歌被认为是这个房间里的大象,是唯一一家内部拥有一切的公司,因此可以在没有第三方依赖的情况下进行开发。 谷歌害怕使用开放数据,除了搬起石头砸自己的脚之外,在推广一项可以直接影响其最有价值的业务 — — 搜索引擎的技术方面。
一位技术分析师评论说,现在可以以 500,000 美元的成本开发一个小型 LLM,这并没有让任何小公司的人兴奋。
考虑到大量的计算资源和能源使用,一个有趣的引述是,训练一个大型 LLM 模型的碳足迹与驾驶五辆汽车在其生命周期内的碳足迹相同。
GPT-3.5 使用 10,000 个 Nvidia GPU 进行训练,每张卡的成本为 10,000 美元。 据说 GPT-4 使用了 30,000 个这样的 GPU 卡。 目前尚不清楚所用能源的成本,或微软与 OpenAI 合作负责的技术基础设施的一般成本。
5 — API 是解决方案
OpenAI 一直在发布 API,以便开发人员可以生成可以访问他们已经训练过的 LLM 系统的应用程序。
APIS(应用程序接口)允许通过调用函数和例程在不同系统、平台和设备之间进行集成。
使用 API 的模型应该扩展到其他环境,例如 Google、Microsoft、Nvidia、BLOOM 以及最近出现的其他 LLM。
已经确定了主要成本,例如培训 LLM 和开发算法。 对应用程序的访问可以以美分美元的形式支付,以获取访问权限和使用的数据量。
大大降低 LLM 的初始成本并在市场上产生新的应用程序。
创造力将成为这个生成式人工智能新世界的极限,LLM 的产品越来越多,每个新版本都会产生大量的数据、处理和知识。