
中國 — 关于 ChatGPT 技术的一般文章
ChatGPT 和谈话的艺术:生成人工智能的潜力分析。
中國 — 了解 ChatGPT 的技术和应用。

第 1 节 — 介绍
ChatGPT 是人工智能分支的一部分,称为生成人工智能 (GenAI)。
它们是用于生成文本、音频、图像、视频、模拟和计算机代码的算法。
生成式人工智能采用称为机器学习、深度学习和神经网络的人工智能技术,根据对文字、声音、图像和视频的统计预测来生成内容。
之所以称为生成式,是因为它通过简单的自然语言命令创建了一些以前不存在的东西,例如“画一张猫和狮子坐在一起的图片”或“写一篇关于环境的文章”,或编写代码在 Python 中。
1 — 生成式 AI 和内容制作
生成式 AI 根据从其受过训练的大量数据中学习到的统计数据和概率来制定响应。
生成人工智能能够生产:
- 文章、诗歌、新闻、脚本、审查计算机代码、演示文稿、翻译等文本。
- 新风景、人脸、绘画、化身、虚拟环境等图像。
- 音频,例如音乐、音效、画外音、将视频或音频转换为文本等。
- 来自先前定义的文本或图像的合成视频。
这里令人兴奋的是,生成式人工智能产品会根据用户提出的问题在计算机提示符下提供答案,这是一个接收问题的空白行,类似于聊天机器人。
ChatGPT 4.0 版称为多模式。 这意味着它可以从提示行中提供的文本或图像生成内容。
2 — 通过提示行的命令
我可以让 ChatGPT 写一篇关于环境的文章,或者让 DALL-E 从简单的问题中生成一幅关于我们社会偏见的印象派绘画,比如:
- ChatGPT,你能写一篇关于环境的文章吗?
- DALL-E,你能画一幅关于环境的印象派画作吗?
你写作时就好像在和朋友、孩子或邻居聊天一样。
第 2 节 — ChatGPT 和综合内容
生成式 AI 生成的主要产品称为合成数据或内容,由数字世界中的机器(应用程序)创建。
它们是使用从输入数据中学习的统计技术和模式从预先存在的数据生成的文本、图像、音频和视频内容。
一个生成式 AI 应用程序可能已经过训练,可以阅读数千篇关于政治的文章,以便能够提出或回答有关该主题的新问题。
另一个应用程序可以从成对的数据与文本和图像的关联中生成印象派绘画,这些印象派绘画已经接受了印象派画家的数百幅画作的训练。
所有应用程序的概念都是相同的。
首先是基于大量数据的训练,包含数千、数百万或数十亿个示例,其结果是从简单的问题中得到智能答案。
一些生成合成内容的应用程序及其功能是:
- ChatGPT 生成文本、计算机代码。
- MidJourney 创造美丽的插图。
- DALL-E 用于绘制美丽的图画。
- MusicLM 用于创作歌曲。
生成合成内容的最终结果是如此之好,以至于大多数时候我们都不知道如何区分它是由机器还是人类生成的。
生成式 AI 应用程序已经侵入互联网,并提供面向文本、计算机代码、音频、视频和图像的各种合成数据生成。
由于与剽窃和版权相关的数据限制,以及现实世界数据的成本,生成式人工智能系统倾向于使用合成数据进行自身训练。
已经有公司在健康、金融、游戏等专业领域销售合成数据。
从现在开始密切关注您在 Internet 上交互的数据,您会发现其中很大一部分是合成的。
欢迎来到由生成式人工智能由机器生成的文本、图像、照片、音乐、书籍、故事、视频和其他类型知识的时代。
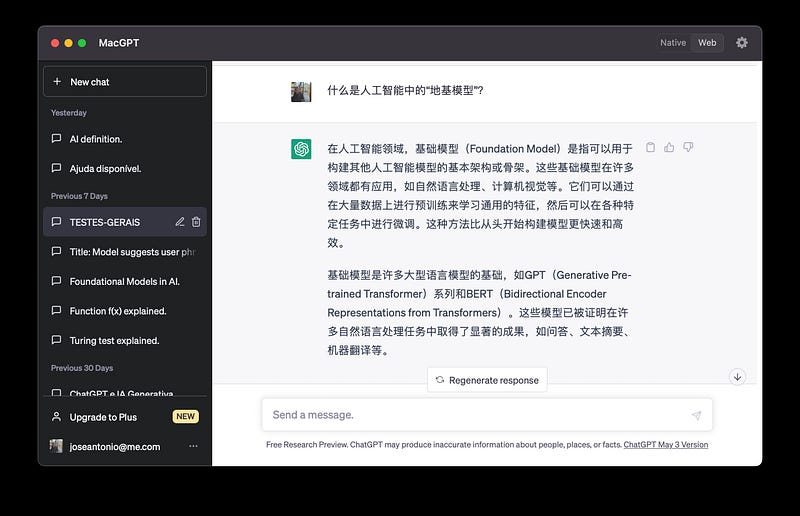
第 3 节 — ChatGPT 和“地基模型”
生成式 AI 应用程序由所谓的“地基模型”提供支持。
这个词是最近由斯坦福大学的 HAI(以人为中心的人工智能)创造的,并立即被 AI 社区所接受。
这些系统被称为模型,因为它们代表了基于训练中使用的大量数据来模拟或建模现实世界某些方面的尝试。
这些模型为构建 AI 系统定义了一个新的成功范例。 他们接受了大量数据的训练,可以适应创建其他专业模型并生成多个应用程序。
由于培训成本巨大,一旦准备好这些模型就可以通过 API 访问,从而允许开发人员开发新的应用程序。
这些模型是使用深度学习和人工神经网络等人工智能技术从大量数据中训练出来的。
在经典 AI 中,您必须确保数据集被标记以执行特定任务。 这是一项艰苦的工作,人们花费了数千小时在所谓的监督机器学习系统中为数据集查找、识别和标记图像、文本或图形。
1 — 培训“地基模型”
在生成式 AI 中,模型是根据大量未标记的数据进行训练的,这些数据可用于不同的任务,只需进行最少的调整。
这些差异化模型是机器学习无监督学习系统的一部分。
我们正在第一眼看到这些模型在图像和语言世界中的潜力,例如 ChatGPT、Bard、DALL-E,它们展示了这项技术的能力。
这些模型的主要特点是,从先前任务中积累的知识中,模型可以通过自监督学习和学习迁移技术来学习执行新任务。
该模型可以将它了解的有关一种情况的信息应用到另一种情况,这使它相信自己具有接近人类的智能。
这些模型通过补充人类工作并提高我们的生产力,为我们的社会开辟了巨大的机会。
这些模型可应用于广泛的行业,包括医疗保健、教育、翻译、社交媒体、法律等。
同时,它们会带来风险,并会破坏我们对信息的信心,从而增加偏见。
OpenAI 的 GPT-3 表现出令人印象深刻的行为,但也可能会意外失败,并带有人们知之甚少的偏见。
即使是具有数万亿参数和生成 25,000 词文本能力的 GPT-4 也会产生幻觉,OpenAI 对此发出了警告。
在本文的前一篇文章中,我们列出并描述了生成式人工智能及其影响我们社会的基础模型的一些风险。
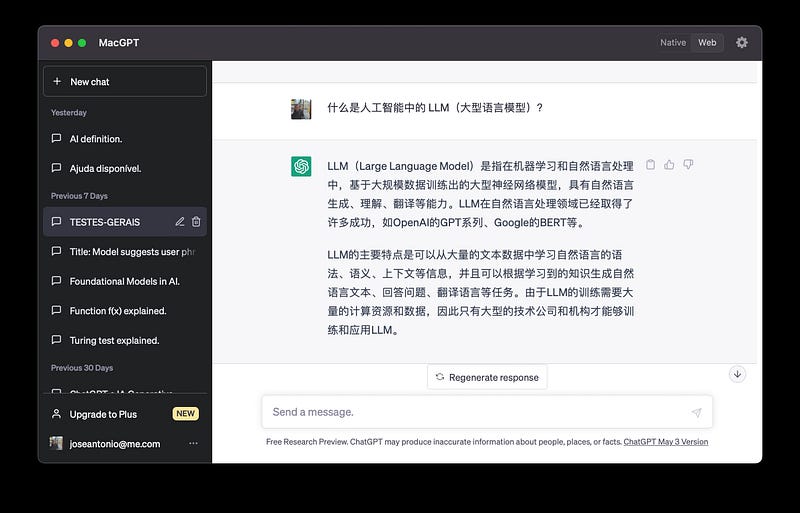
第 4 节 — ChatGPT — LLM 模型(大型语言模型)

LLM(大型语言模型)是这些模型中最著名的。
用于使用自然语言处理 (NLP) 算法和称为 Transformers 的 AI 训练技术解决语言问题。
ChatGPT 使用这种从长文本字符串中获取含义的技术来了解不同的单词或语义组件可能如何相关,然后确定它们彼此相邻出现的可能性。
一款猜测较早学习的单词和短语的游戏,稍后再猜。
这些转换器在一个称为预训练的过程中在大量自然语言文本上无人值守地运行,然后由与模型交互的人类进行调整。
预训练是教授系统的地方,或者更确切地说,是它自己学习文本中单词之间关系的地方。
这些大规模模型导致了系统的发展,这些系统可以理解我们所说或所写的内容,或者更确切地说,可以从他们从人类那里学到的东西中产生知识。
使用这些模板的一个非常简单的例子是在键入消息时自动填写表格和手机。 该系统为您提供了备选词,供您在句子的上下文中进行选择。
我们正在谈论猜测下一个词或接下来的两个词。 LLM模型把这个概念发挥到了极致,有的可以看前后700个单词,有的远不止于此。
也就是说,他们试图猜测文本中接下来的 700 个单词。
这些系统越聪明,它们就能猜到越多的单词,或者更确切地说,可以统计地预测出正确的单词作为答案。
1 — 在各种人类活动中训练的模型
值得注意的是,只要经过适当的训练,这些模型就可以适用于所有类型的人类活动。
例如:
- 用著名艺术家的作品训练的系统可以按照这些艺术家的风格生成新的艺术作品。
- 受过数学或化学教科书训练的系统可以在这些领域产生具有新想法的结果。
- 接受辩护案例培训的系统可以学习和协作,以便在法官和法院中开发和解决案件。
我们可以看到,这些系统将在未来几年入侵世界,我们将在我们的教育、个人和职业生活中与其中许多系统互动。
出于这个原因,我们正在目睹一场主导和改进这项技术的竞赛,这项技术可能与互联网一样重要,并且可以带来社会变革,如农业、工业和技术革命。
2 — LLM 算法
LLM是一种深度学习算法,可以根据海量数据训练得到的知识,识别、归纳、翻译、预测和生成文本等内容。
这些文本模型不仅仅用于教授或翻译人类语言。
他们可以通过聊天机器人以文本格式回答问题,应用范围非常广泛,例如:
- 了解蛋白质、分子、DNA 和RNA。
- 编写计算机代码。
- 为图像生成器构建文本和图像对。
- 改进搜索引擎。
- 作曲、写诗、写故事、写书。
这些模型在推理、常识和问题解决等人工智能领域展示了强大的能力。
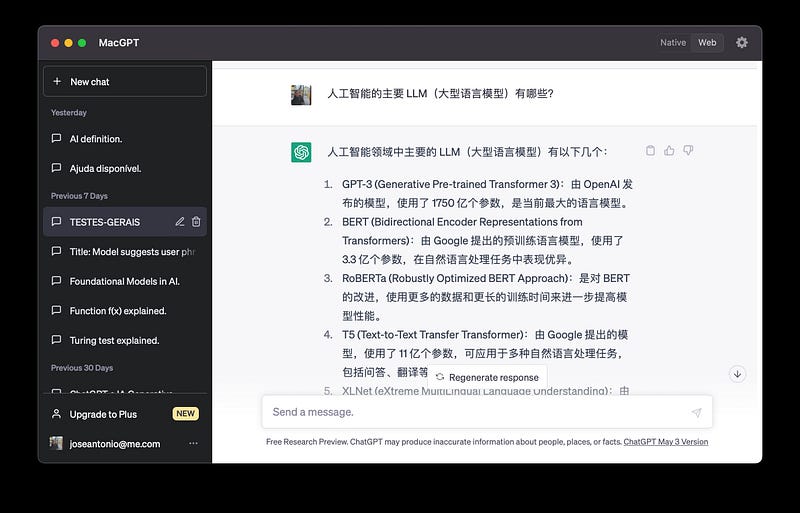
最受欢迎的 LLM 模型是:
- ChatGPT 中使用的 OpenAI 的 GPT(生成式预训练转换器)。
- CODEX by OpenAI 用于计算机代码生成。
- Microsoft 的 Sydney 基于 ChatGPT for Bing 构建。
- Bard 使用的谷歌LaMDA(对话应用程序语言模型)是谷歌的会话人工智能服务。
- Nvidia 的威震天。
- Facebook 的 RoBERTa(稳健优化的 BERT 方法)。
- 欧洲共同体的BLOOM(BigScience Large Open-science Open-Access Multilingual Language Model)由欧洲研究人员、政府和公司组成的联盟在巴黎地点的大型机上开发。
- 来自IsraeliAI21 的Jurassic。
除了最知名的,还有大量公司致力于开发 LLM 供自己使用,或在市场上将其商业化,例如百度、DeepMind、Meta、AI21 Labs、LG AI Research、Anthropic、华为、除其他外。
为企业本身或商业化开发 LLM 的竞赛现在正在进行,通过软件 API 提供对训练系统的访问,对访问或内容收费。
每个人都希望在生成人工智能市场中占有一席之地,因为他们知道这场革命将显着改变产品和服务以及我们的整个社会。
3 — LLM最受欢迎的模式
目前最流行的 LLM 模型是 ChatGPT 中使用的 GPT-3.5。
GPT-3.5 在 45TB 的数据库上进行训练,相当于超过 2.92 亿页的文档,或 4990 亿个单词。 它使用 1750 亿个参数(神经网络中输入层和输出层之间的连接点)。 它有 96 层注意力(神经网络算法)。
LLM 能发展到多大还不得而知。 据说新的 GPT-4 版本有 100 万亿个参数。 如果 GPT-3 很聪明,想象一下这个新版本。
参数数量的增长开始看起来像摩尔定律,它决定了计算机芯片上晶体管数量的指数增长。
由于规模、成本和专用硬件,这些模型最初是由大型企业、政府和初创公司开发的,它们获得了大型云公司的大量投资和支持。
4 — 投资开发生成式人工智能
生成式 AI 的世界仅限于资金最充足的参与者。 微软在 OpenAI 上投入了 100 亿,这是在已经完成的基础上。
由于没有人可以独自完成所有事情,因此在这个新市场中,我们几乎总是有以下两者的结合:
- 谁有意志和才能。 对于初创公司或敏捷技术公司(OpenAI、DeepMind、Stable Diffusion 等)而言。
- 谁拥有内容。 对于搜索引擎、百科全书、图书馆、书商等(Google、Microsoft Bing、Wikipedia、Meta 等)。
- 谁拥有云服务(AWS、Google、Microsoft Azure)等技术基础设施资源。
- 谁拥有硬件,在本例中为GPUS 制造商(Nvidia、Intel、AMD)。
谷歌被认为是这个房间里的大象,是唯一一家内部拥有一切的公司,因此可以在没有第三方依赖的情况下进行开发。 谷歌害怕使用开放数据,除了搬起石头砸自己的脚之外,在推广一项可以直接影响其最有价值的业务 — — 搜索引擎的技术方面。
一位技术分析师评论说,现在可以以 500,000 美元的成本开发一个小型 LLM,这并没有让任何小公司的人兴奋。
考虑到大量的计算资源和能源使用,一个有趣的引述是,训练一个大型 LLM 模型的碳足迹与驾驶五辆汽车在其生命周期内的碳足迹相同。
GPT-3.5 使用 10,000 个 Nvidia GPU 进行训练,每张卡的成本为 10,000 美元。 据说 GPT-4 使用了 30,000 个这样的 GPU 卡。 目前尚不清楚所用能源的成本,或微软与 OpenAI 合作负责的技术基础设施的一般成本。
5 — API 是解决方案
OpenAI 一直在发布 API,以便开发人员可以生成可以访问他们已经训练过的 LLM 系统的应用程序。
APIS(应用程序接口)允许通过调用函数和例程在不同系统、平台和设备之间进行集成。
使用 API 的模型应该扩展到其他环境,例如 Google、Microsoft、Nvidia、BLOOM 以及最近出现的其他 LLM。
已经确定了主要成本,例如培训 LLM 和开发算法。 对应用程序的访问可以以美分美元的形式支付,以获取访问权限和使用的数据量。
大大降低 LLM 的初始成本并在市场上产生新的应用程序。
创造力将成为这个生成式人工智能新世界的极限,LLM 的产品越来越多,每个新版本都会产生大量的数据、处理和知识。
第 5 节 — 最后一句话和总结

1 — 我们看到的简要总结:
- Uma revolução tecnológica de IA surgiu com o lançamento do ChatGPT.
- ChatGPT 的发布带来了人工智能技术革命。
- 合成内容由机器以文本、音频、视频和图像格式生成。 它们是原创的,通常无法区分它们是由人还是机器制作的。
- 合成内容的生成是生成人工智能的一部分,它使用机器学习、深度学习和神经网络技术。
- 在这些系统中,用户通过提示符或使用自然语言的文本命令行与应用程序通信。
- 应用程序需要使用来自不同来源的大量数据进行训练,例如互联网、书籍、百科全书、科学文章等。
- 使用的主要技术是基础模型,LLM(大型语言模型)是从称为 NLP(自然语言处理)的 AI 领域派生的最重要的技术。
- LLM 的开发成本非常高。 他们集中在与他们有联系的大公司或创意初创公司。
- 可以使用软件API 访问LLM,这允许以更低的成本生成生成式AI 应用程序。
- 在生成人工智能方面,世界上最大的技术公司无法面面俱到。 除了资金和技术资源,他们还需要创新并转向创业公司。
- 法学硕士和生成式人工智能将成为在世界范围内普及人工智能的载体。
2 — 最后一句话
在正确的地点和正确的时间出现的技术最终呈指数级增长,标志着人类变革的一个时期。
微型计算机、互联网、网络浏览器、iPhone、云计算等引起了社会行为的变化,影响了市场。
指数技术的影响只有在它们变得流行并允许尽可能多的人使用时才能感受到。
人工智能的使用并未让用户认为它是人工智能应用程序。 Alexa 等虚拟助手、面部识别、垃圾电子邮件、Waze 等路由应用程序等。
借助 ChatGPT,人工智能趋于流行,允许访问个人或职业生活中不同领域的数十亿人。
具有 LLM 的基础模型将成为这种普及的载体,根据用户、问题和请求调整知识。
拥有世界上所有知识的神谕者。 服务员准备为我们提供知识来解决问题。
无论您年龄多大,您都将使用这项我们仍未完全了解的技术、它的风险、影响和好处。
作为一个社会,我们将不得不发现并找到其使用和应用的最佳替代品。
生成式人工智能可以成为一种技术,其影响可以造福于人类。
作家若泽·安东尼奥·泽津尼奥。Author José Antonio Zezinho.