
中國 — 关于 ChatGPT 技术的一般文章。
ChatGPT 和版权、道德与法规.
中國 -了解 ChatGPT 的技术和应用。

ChatGPT 和版权、道德与法规
当一个人产生了文本、音频、视频、绘画或代码等内容时,可以说他获得了版权。
当 ChatGPT 产生内容时,您不知道谁拥有权利。 它是否属于开发产品的公司、创建问题的用户或用于训练算法的数据的所有者。
1 — 在这个技术时代该做什么?
由于没有监管,第一起版权诉讼开始出现。
他们中的第一个在美国,反对微软、GitHub 和 OpenAI,因为 OpenAI Codex 产品使用了从 GitHub 上抓取的数据。
由于 AI 技术引发伦理问题并影响版权,此时最好的办法就是将 ChatGPT 作为研究、学习和个人发展的来源。
2 — 什么是合成内容?
这些是机器生成的内容,例如文本、视频、音频、图像、计算机代码,类似于人类生成的内容。
以至于无法确定它们是由机器还是人类生产的。
此类内容的制作呈爆炸式增长,第一批公司和产品出现了,例如 Jasper、Stable Diffusion、Stability.AI、Character.AI、Replika、Midjourney、Lexica Art、You.Com。
随着 OpenAI 推出 ChatGPT,除了巨头 Google、Adobe、Meta 和 Microsoft 之外,该领域还出现了 450 多家初创公司。
3 — 合成内容的产生会导致失业吗?
当我们要求人工智能软件生成绘画、图像、文本等合成内容时,我们可能会减少内容制作者的工作量。
这让我们相信,他们可以与内容和代码的画家、作家、作家和制作人竞争。
学生用 ChatGPT 回复替换论文和作业。 大学感到困惑并正在审查他们的教学模式。
医疗保健中的聊天机器人可以消除医疗面谈甚至咨询。 在商业领域,它可以取代顾问和销售人员。
这会使创意经济面临风险吗?
这项技术可以改变市场、工作、经济,并将为人类带来一个新时代,在这个时代,人类的创造力将与机器的支持相结合。
专家表示,这种人工智能可以重塑几乎所有东西,包括搜索引擎,而且公司会以某种形式使用它
4 — 什么是生成式人工智能?
合成内容属于人工智能的一个领域,称为生成人工智能(Generative AI)。
它们是使用机器学习和神经网络技术开发的模型,使用来自互联网的大量数据来训练它们的算法。
最常见的模型是用于自然语言处理的 LLM(大型语言模型)或用于语言翻译、文本生成、问答的 NLP(自然语言处理)。
ChatGPT 的 GPT-3 是一个 LLM 应用程序。
5 — 训练算法的数据来自哪里?
用于训练系统的生成模型中使用的数据集(数据集)作为开放和公共数据从互联网上获取。
它们被称为“Web Scraping”或从 Internet 上收集的数据。 通过抓取软件和机器人收集,包括文本、图像、视频、计算机代码、html 和元数据。
它们是不同类型的数据,结构化或非结构化,将用于训练生成人工智能系统。
6 — 数据抓取示例
我的数据科学主要项目使用了数据抓取。 可以在 GitHub 上找到该项目。( GitHub 1)
数据是从博客、推特和新闻中收集的。
它们用于开发和训练能够预测后续单词的 NLP(自然语言处理)模型。
根据这些数据,我开发了一个预测模型来促进在移动设备上打字。
与消息传递系统一样,在键入一个词时,除了可以构成句子的第二个或第三个词之外,我还会收到三个可供选择的建议,从而促进文本的产生。
该模型给我留下了深刻的印象,因为实际上数据采样使我能够获得最常用的词,这些词被计算为表明最有可能在应用程序中使用的词。
N-Grams 标记化技术用于预测算法中的单词组合。 该项目是通过一个 Shiny 应用程序和一个使用 R-Presentation 的推介完成的。
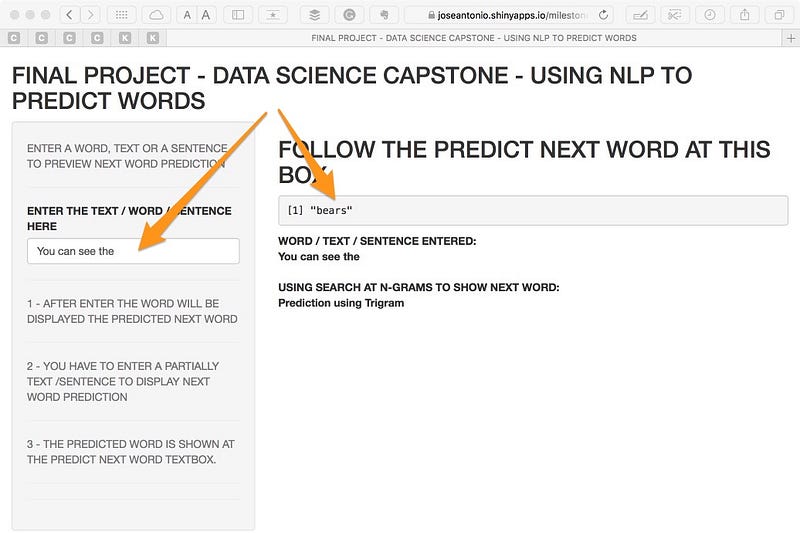
学术项目中,使用了开放数据。 在应用程序的最终结果中,算法从该数据中学习了要连接的最佳单词,并丢弃了原始数据源。
这就是生成式 AI 中发生的情况,原始数据源被丢弃,在应用程序完成后消失。
我使用了 16MB 的采样,但我想知道 ChatGPT 中使用的 530GB 在使用强化学习的这种性质的算法的准确性方面做了什么
7 — 模型训练和虚假信息的产生
用于文本生成的 AI 模型经过训练,可以分析从互联网上抓取的大量文本中的模式。
他们试图找到统计规律来预测句子中接下来应该出现哪些词。 在这个过程中,他们可以将正确的内容与错误的内容混合在一起。
目前,我们还不知道这些系统会产生多少虚假信息。
合成文本中的许多此类错误只能由专家检测到,他们在使用 ChatGPT 时会注意到一些细节。
8 — 生成式人工智能的风险
我列出了生成式 AI 的一些风险。
- 剽窃内容的生成。
- 版权影响和道德问题。
- 可能产生有毒内容,例如错误信息、仇恨言论、有偏见的图像。
- 生成不可靠和不正确的内容。
- 产生看似合理的答案,但有错误的观点。
- 淘汰都灵测试,该测试验证机器是否可以具有与人类相同的行为。
- 基于不正确的来源生成有偏见的内容。
9 — 硬币的两面
一些人认为这些系统会引发相互冲突的道德问题、侵犯版权并面临严重的法律挑战。
其他人则认为生成式 AI 超越任何诉讼。
这些公司坚持认为,这些数据的使用在美国属于合理使用原则。 它通过促进表达自由来鼓励使用受版权保护的作品。
在法律领域,我们必须开始回答有关 AI 输出和输入数据的版权问题。
谁拥有输出数据的版权? 使用者? 创建模型的公司? 原始数据的所有者?
在输入的数据中,数据权利人是否对所创造的内容有合法的主张? 在数据收集中应该使用什么样的法律限制?
10 — 技术的经济和社会影响是什么。
一些人认为技术会带来大规模失业,而另一些人则认为我们正在进入一个人机合作的新时代,在这个时代,生成式人工智能将通过加速创造阶段来帮助创造过程。
这项技术的治理掌握在生产生成模型的公司手中,有些人持谨慎态度,而另一些人则认为必须发布模型才能实现民主化并在社会和经济中产生影响。
开发 AI 产品的公司宣称他们所做的是合法的,版权所有者开始对合法应该做的事情采取立场。
由于这个和其他原因,2023 年将是生成人工智能 (Gen-AI) 年。
作家何塞·安东尼奥 (Zezinho)。Author José Antonio (Zezinho).
1 GitHub — https://github.com/joseantonio11/data-science-capstone