
Character-level Convolutional Networks for Text Classification
One of the common natural language understanding problems is text classification. Over last few decades, machine learning researchers have been moving from the simplest “bag of words” model to more sophisticated models for text classification.
Bag of words model uses only information about which words are used in the text. Adding TFIDF to the bag of words helps to track relevancy of each word to the document. Bag of n-grams enables using partial information about structure of the text. Recurrent neural networks, like LSTM, can capture dependencies between words even if they are far from each other. LSTM learns structure of sentences from the raw data, but we still have to provide a list of words. Word2vec algorithm adds knowledge about word similarity, which helps a lot. Convolutional neural networks can also help to process word-based datasets.
A trend is to learn using raw data, and provide machine learning models with an access to more information about text structure. A logical next step would be to feed a stream of characters to the model and let it learn all about the words. What can be cruder than a stream of characters? An additional benefit is that the model can learn misspellings and emoticons. Also, the same model can be used for different languages, even those where segmentation into words is not possible.
The article “Character-level Convolutional Networks for Text Classification” (Xiang Zhang, Junbo Zhao, Yann LeCun) explores usage of character-level ConvNet networks for text classification. They compare performance of a few different models on several large-scale datasets.
Datasets contain from 120,000 to 3,600,000 samples in the training set, from 2 to 14 classes. The smallest dataset is AG’s News: news articles divided into 4 classes, 30,000 articles for each class in the training set. The largest is Amazon Review Polarity: 2 polarity segments with 1,800,000 reviews for each of them.
Character-level ConvNet was compared with state-of-the-art models: Bag-of-words and its TFIDF, Bag-of-ngrams and its TFIDF, Bag-of-means on word embedding, word-based ConvNet, word-based LSTM.
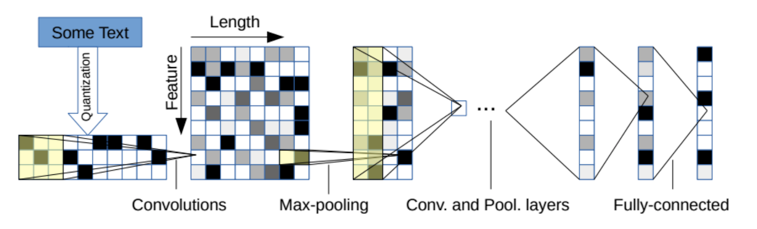
Character-level ConvNet contains 6 convolutional layers and 3 fully-connected layers.
Results are quite interesting. N-gram and N-gram TFIDF models have are the best for smaller datasets, up to several hundreds of thousands of samples. But when dataset size grows to several million we can observe that character-level ConvNet performs better.
ConvNet tends to work better for texts which are less curated. For example, ConvNet works better on Amazon reviews dataset. Amazon Reviews are raw user inputs, whereas users could be more careful in writings on Yahoo! Answers.
Choice of alphabet matters. ConvNet works better is not distinguishing between upper and lower case characters.
Another overview of this paper
Other useful links:
Understanding Convolutional Neural Networks for NLP
A Set of Character-Based Models for Sentiment Analysis, Ad Blocking and other tasks
This article was originally published on http://pavel.surmenok.com/2016/06/12/character-level-convolutional-networks-for-text-classification/





