Causal Inference
Model Testing and Causal Search
This is the eighth post on the series we work our way through “Causal Inference In Statistics” a nice Primer co-authored by Judea Pearl himself.

You can find the previous post here and all the we relevant Python code in the companion GitHub Repository:
While I will do my best to introduce the content in a clear and accessible way, I highly recommend that you get the book yourself and follow along. So, without further ado, let’s get started!
2.5 — Model Testing and Causal Search
In this section, Pearl shows us how to build up on the d-separation definition introduced in the previous section:
Definition (d-separation) — A path p is blocked by a set of nodes Z, if and only if:
1. p contains a chain of nodes A → B → C, or a fork A ← B → C such that the middle node B *is* in Z, or
2. p is a collider A → B ← C such that the collision node B is *not* in Z, and no descendent of B is in Z.
If Z blocks every path between two nodes X and Y, then X and Y are d-separated, conditional on Z, and thus are independent conditional on Z
d-separation allows us to quickly identify which variables must be independent conditional on which other variables. Such conditional dependence conditions are testable implications that can be tested directly on the data we collected allowing us to validate our models and choose among several candidate models. In particular, we can consider the model validated if every d-separation condition is empirically verified by the data.
It can be shown that two DAGs belong to the same equivalence class if they contain the same skeleton (set of undirected edges) and exactly the same set of v-structures (converging arrows whose tails are not connected by an arrow) and we introduce no cycles in the resulting graph.
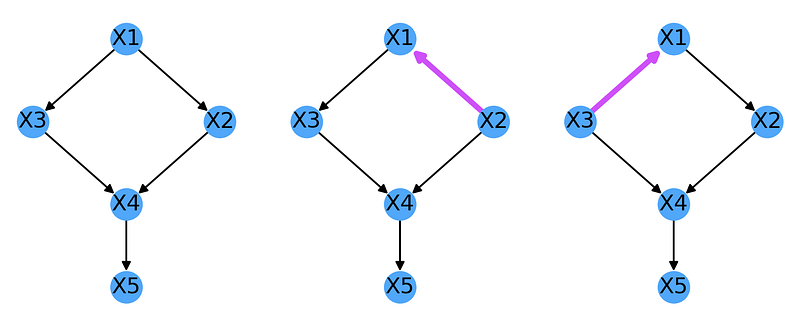
Let’s us clarify this discussion using the example of this DAG, from Fig 1.2 of Causality (Amazon link) Pearls more advanced Causality textbook:
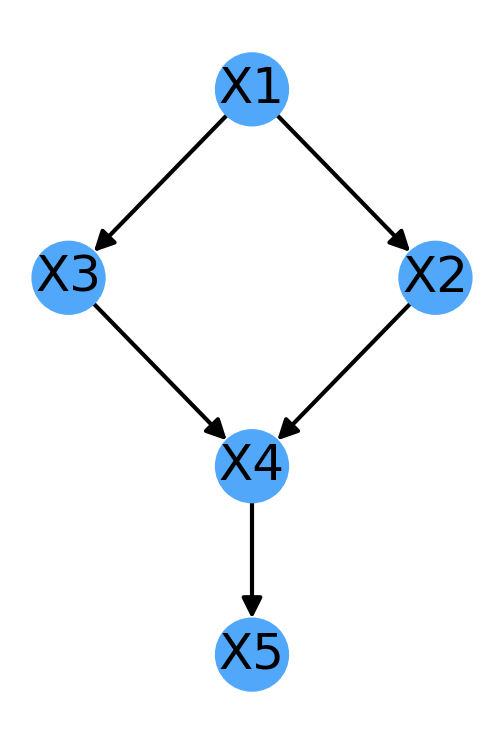
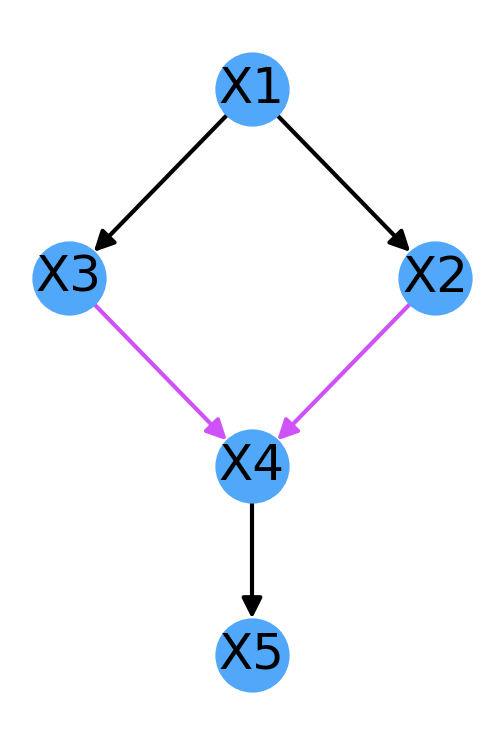
We see that it has only one v-structure, namely the collider at X4:
On the other hand, its equivalence class contains 3 graphs, itself and the graphs obtained by inverting the X1 →X2 and X1 →X3 edges:
This implies that we have no way of empirically determining the direction of the arrows connecting X1 ↔ X2 and X1 ↔ X3 and must infer them from some a-priori knowledge. Also note that we can’t actually invert both edges at the same time as that would create a new collider at X1.
We can confirm that these three graphs are equivalent by generating their “basis-set”, the equations that validate that each variable is independent of their non-descendants when conditioned on its parents.
For all three of these graphs, we have:
X3 _||_ X2 | X1
X4 _||_ X1 | X2, X3
X5 _||_ X1, X2, X3 | X4This is also the minimum set of equations we have to check to verify that our model is compatible with the data. If we simulate our model we can check, for example, that X5 is independent on X1, X2 and X3 when conditioned on X4 by fitting:
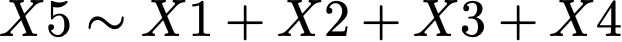
and checking that the coefficients for X1, X2 and X3 are zero. When we do this, we obtain:
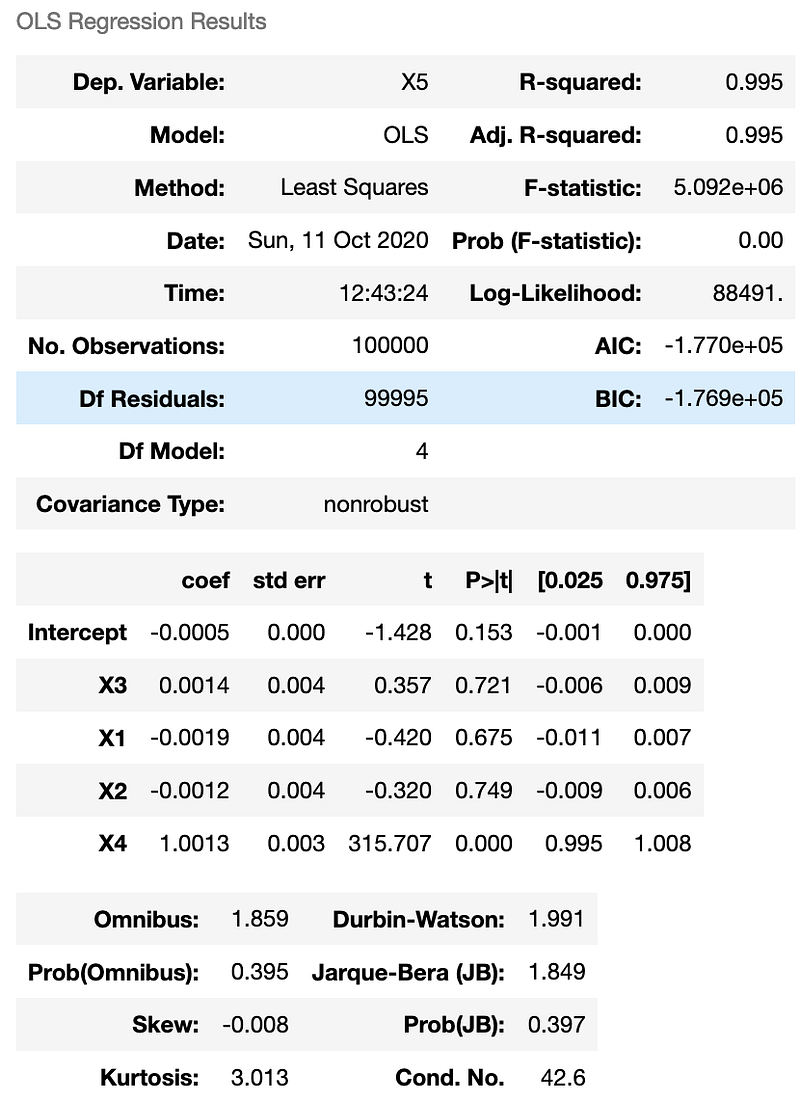
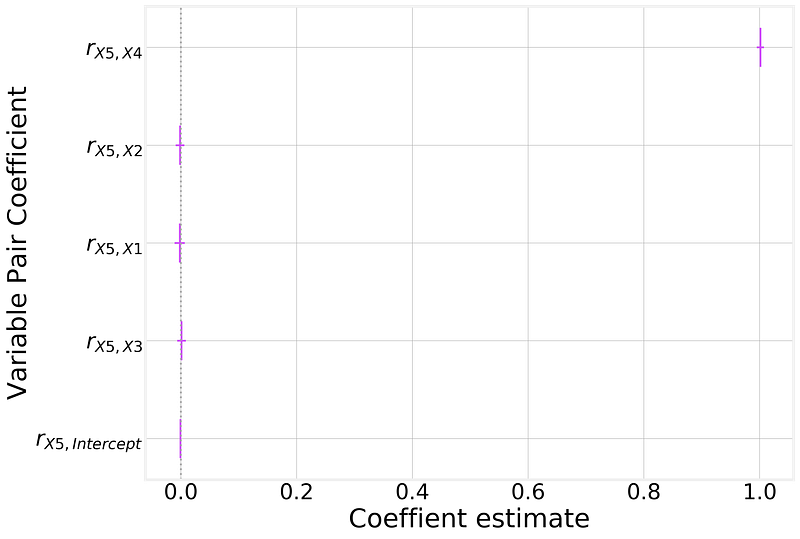
Were we easily see that only the coefficient for X4 is significant. Or, graphically:
Now let us consider a compre complex example from Fig 2.9 (already analyzed previously):
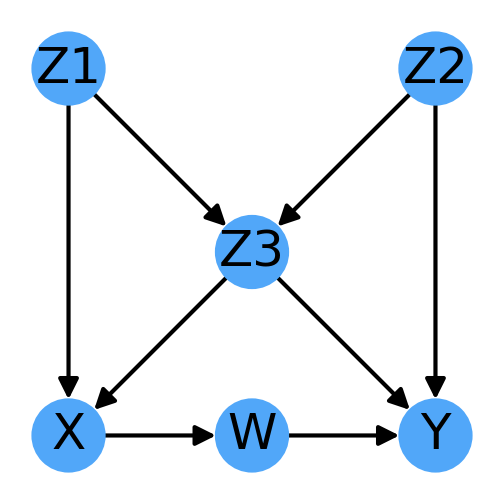
This graph has 3 v-structures:
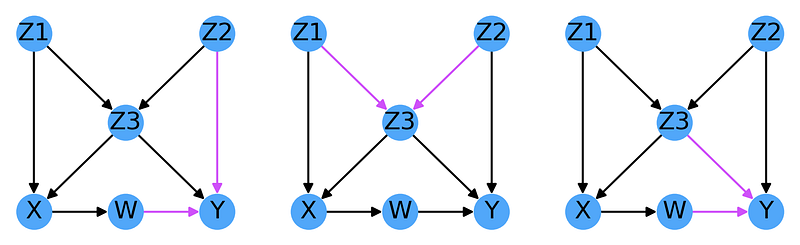
Z3 → Y ← Z2 is excluded due to the Z2 →Z3 edge and Z1 → X ← Z3 by the Z1 → Z3 edge.
However, if we try to change the direction of any of the arrows, we break out of the equivalence class. For example, reversing Z1 → Z3 would break the collider at Z3, while reversing W→ Y would create a new collider at W. Inverting the Z1 →X edge would both break the collider at X and create a new cycle.
As a consequence, the direction of every arrow in the DAG can be determined experimentally as any change would necessarily generate a different basis-set of equations to test.
This post completes Chapter two of the book. Congratulations on making it this far and I hope you continue to find these posts useful and interesting.
Just a quick reminder that you can find the code for all the examples above in our GitHub repository:
The next post in this series is already available:
And if you would like to be notified when the next post comes out, you can subscribe to the The Sunday Briefing newsletter: