

Catálogo de Dados do Zero Até Implantação e Evolução!!!
Oque é? Alternativas de código aberto? Como implementar? Desafios e muito mais!
Essa publicação se destina a dar uma luz para a situação que “algumas” instituições que começaram a entender e valorizar seus dados como sendo um produto interno que impulsiona, qualifica e distingui seus produtos em relação ao mercado a curto prazo. Essas mesmas empresas que infelizmente, internamente, cada área de negócio construiu sua arquitetura muitas das vezes sem um padrão, sem uma qualidade ou saneamento básico e fazendo a distribuição de maneira arcaica e lenta, cheias de gambiaras, uma verdadeira favela de dados.
Nessa situação caótica é muito comum que as pessoas do negócio estejam de certa forma alienadas, colocando a culpa de situações de lentidão em um determinado “software” ou solução, ou tenham a “certeza” que determinada informação não exista em toda essa zona.
#Como mudar essa situação? Como evitar o “Shadow IT” com dados? Impedir o “tráfico” de informações?
Uma alternativa é entender o que já existe, organizar, dicionarizar e catalogar as bases disponíveis, de modo a distribuir e criar uma oportunidade de fomentar uma cultura organizacional orientada a dados, ou seja, criar um Hub de dados.
Esses são alguns dos casos, segundo os engenheiros do LinkedIn de uso de um catálogo de dados e uma amostra dos metadados de que eles precisam:
- Pesquisa e descoberta: esquemas de dados, campos, tags, informações de uso.
- Controle de acesso: grupos de controle de acesso, usuários, políticas.
- Linhagem de dados: execuções de pipeline, consultas, registros de API, esquemas de API.
- Conformidade: taxonomia de privacidade de dados / categorias de anotação de conformidade.
- Gerenciamento de dados: configuração da fonte de dados, configuração de ingestão, configuração de retenção, políticas de eliminação de dados (por exemplo, para GDPR “Right To Be Forgotten”), políticas de exportação de dados (por exemplo, para GDPR “Right To Access”).
- Explicação de AI, reprodutibilidade: definição de recurso, definição de modelo, execuções de execução de treinamento, declaração de problema.
- Operações de dados: execuções de pipeline, partições de dados processadas, estatísticas de dados.
- Qualidade de dados: definições de regras de qualidade de dados, resultados de execução de regras, estatísticas de dados.
Observando a necessidade crescente do mercado várias comunidades e empresas pelo mundo desenvolverão várias soluções como, por exemplo, o Dataportal da Airbnb, Metacat da Netflix, Databook da Uber, DataHub do LinkedIn, Amundsen do Lyft, Lexikon do Spotify e o Data Catalog da Qlik.
Dentro dessas e de muitas outras, as que tem mais se destacado principalmente nas comunidades e empresas que adotam e utilizam de soluções de código aberto são o Amundsen do Lyft e DataHub do LinkedIn.
O Amundsen por ser uma solução que foi lançada antes de o DataHub e de ter sido incorporado LF AI Foundation, ganhou uma grande comunidade e muitas empresas a utilizam em seus ambientes produtivos.
Olhando para o DataHub, podemos notar que o histórico de sucesso de projetos de código aberto do LinkedIn se repetindo como foi o caso do Kafka. Já nos seus primeiros meses o projeto, ganhou uma grande comunidade e está sendo adotado por muitas empresas e até instituições financeiras que o utilizam e contribuem ativamente.
#Por experiência, pela quantidade integrações e pela documentação muito rica, prefiro o DataHub e você?
DataHub :)
é uma plataforma de metadados de código aberto para a stack de dados moderna.
Arquitetura
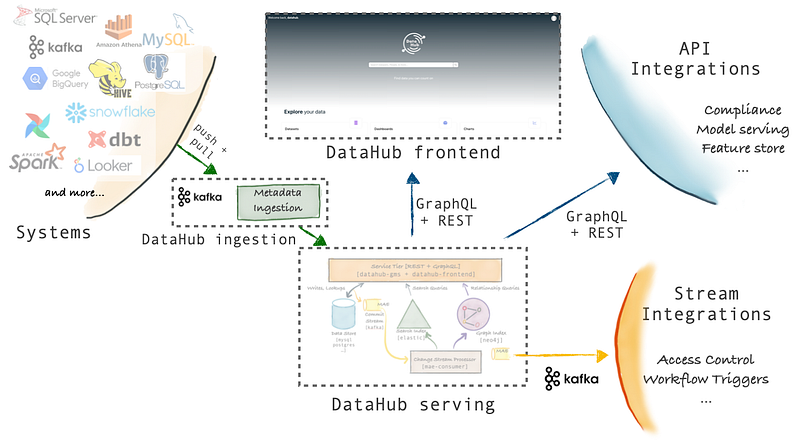
Sua arquitetura pode ser dividida em ingestão, Serving e FrontEnd:
- Arquitetura de Ingestão:
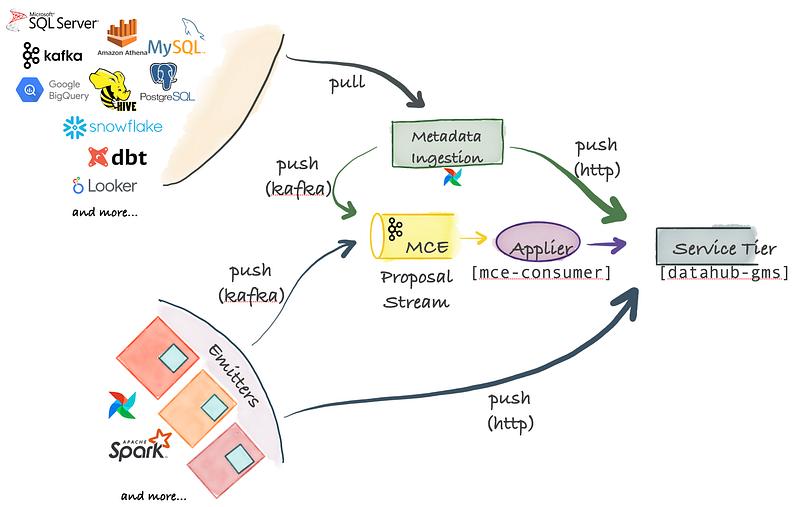
Com um sistema de ingestão em Python que se conetar em diferentes fontes para extrair metadados enviados via HTTP ou Kafka para uma camada de armazenamento, essas pipelines podem ser integradas a um Airflow para uma ingestão programada ou uma linhagem de captura.
- Arquitetura de “Serving”:
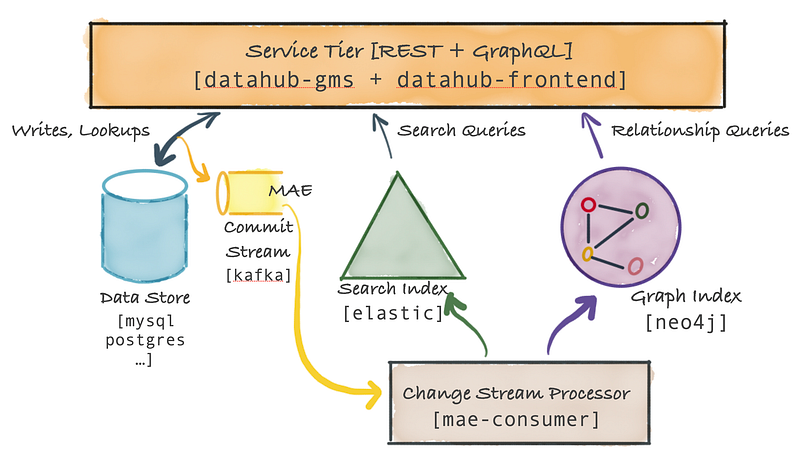
Os metadados são persistidos em um armazenamento de documentos (pode ser um RDBMS como MySQL, PostgreSQL ou um armazenamento de chave-valor como Couchbase, etc.).
O DataHub possui Metadata Commit Log Stream (MAE), serviço que possibilita verificar se houver alteração de metadados e iniciar uma reação de atualização em tempo real a modificação que aconteceu.
- Arquitetura de FrontEnd: React App + Graphql + Imagens:
Seu FrontEnd é construindo utilizando React visando possibilitar:
- Configurabilidade: a experiência do cliente deve ser configurável, de modo que as organizações de implantação possam adaptar certos aspectos às suas necessidades. Isso inclui a possibilidade de configuração de tema / estilo, exibição e ocultação de funcionalidades específicas, personalização de cópias e logotipos, etc.
- Extensibilidade: estender a funcionalidade do DataHub deve ser o mais simples possível. Fazer alterações como estender uma entidade existente e adicionar uma nova entidade deve exigir esforço mínimo e deve ser bem abordado em documentação detalhada.
Integrações:
Como catálogo de dados, um dos seus principais pontos de adoção é sua quantidade de soluções prontas de ingestão. Com o DataHub é necessário apenas ter o Docker instalado, instalar uma biblioteca Python e fazer a execução de arquivo de configuração YML passando a categoria de ingestão, informações de acesso como usuário e senha, e o destino “sink”.
Relação de integrações:
- Kafka
- MySQL
- Microsoft SQL Server
- Hive
- PostgreSQL
- Redshift
- AWS SageMaker
- Snowflake
- SQL Profiles
- Superset
- Oracle
- Feast
- Google BigQuery
- AWS Athena
- AWS Glue
- Druid
- SQLAlchemy
- MongoDB
- LDAP
- LookML
- Looker dashboards
- File
- dbt
- Google BigQuery
- Kafka Connect
Não achou seu banco de dados ou fonte de dados, uma alternativa é utilizar SQLAlchemy para colher os metadados ou fazer a ingestão via API Rest ou diretamente no Kafka interno do DataHub.
Além de integração com banco de dados, APIs, Kafka, é possível conduzir a integração e buscar informações de modelos de inteligência artificial.
Deploy:
Outra preocupação quando se trata de catálogo de dados é aonde e como será instalado? Sua autenticação? Backup e logs?
Uma preocupação pessoal é sempre adotar soluções que seja possível de serem utilizadas em diferentes ambientes, Clouds e o DataHub pode ser implantando localmente via imagem docker, ambiente kubernetes, AWS e GCP.
Sua autenticação pode ser integrada a JaaS Authentication, JaaS Authentication via React, Google Authentication e Okta Authentication. Os logs estão em diretórios que podem ser acessados remotamente e os dados estão salvos no banco de dados.
Demonstração local:

Esse é um exemplo de como realizar a instalação local de um PostgreSQL, criar uma tabela de exemplo, instalar o DataHub e fazer a ingestão do metadados do PostgreSQL no DataHub. Para realizar essa demostração foi necessário ter o Docker, Git e Python instalados.
Deploy PostgreSQL usando Docker-compose:
Crie o arquivo docker-compose.yml
version: '3'services:
postgres:
image: postgres:13.1
healthcheck:
test: [ "CMD", "pg_isready", "-q", "-d", "postgres", "-U", "root" ]
timeout: 45s
interval: 10s
retries: 10
restart: always
environment:
- POSTGRES_USER=root
- POSTGRES_PASSWORD=password
- APP_DB_USER=docker
- APP_DB_PASS=docker
- APP_DB_NAME=docker
volumes:
- ./db:/docker-entrypoint-initdb.d/
ports:
- 5432:5432Execute o comando a seguir:
docker-compose upUsando alguma ferramenta de conexão a banco de dados como Dbeaver, acesse o PostgreSQL e crie a tabela a seguir:
CREATE TABLE COMPANY(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL,
JOIN_DATE DATE
);Deploy do DataHub
Tendo o Python 3.6 instalado ou superior, execute os comandos abaixo no terminal:
python3 -m pip install --upgrade pip wheel setuptools
python3 -m pip uninstall datahub acryl-datahub || true
python3 -m pip install --upgrade acryl-datahubdatahub versionInstale a CLI do DataHub em seu terminal:
datahub docker quickstartAcesse http://localhost:9002, seu usuário e senha serão “datahub”, sem as aspas.
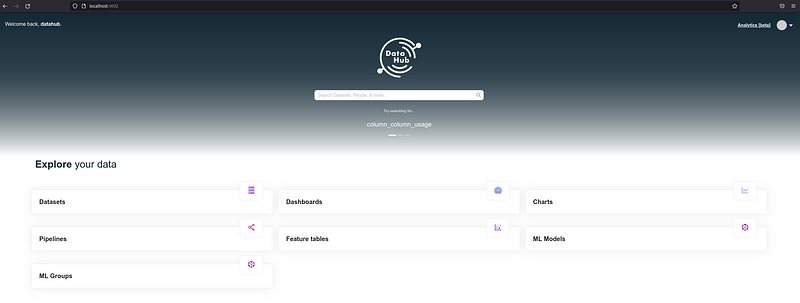
Temos nosso DataHub e o PostgreSQL executando:

Ingestão do metadados PostgreSQL no DataHub.
Faça o clone do projeto do DataHub
git clone https://github.com/linkedin/datahub.gitNavegue até a pasta do scripts de ingestão:
cd datahub/metadata-ingestion/scriptsCrie o arquivo metadata_ingest_from_postgres.yaml com o seguinte conteúdo:
source:
type: postgres
config:
username: root
password: password
host_port: localhost:5432
database: postgres
database_alias: postgrespublic
include_views: True
sink:
type: "datahub-rest"
config:
server: "http://localhost:8080"Execute o comando abaixo:
./datahub_docker.sh ingest -c ./metadata_ingest_from_postgres.yml
A partir do comando acima todos os metadados serão ingeridos e estarão disponíveis para acesso:
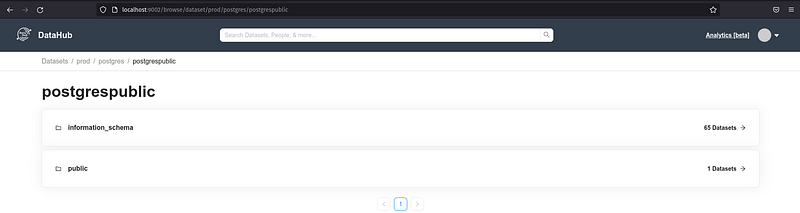
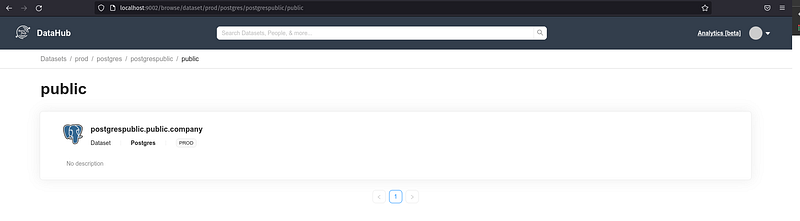
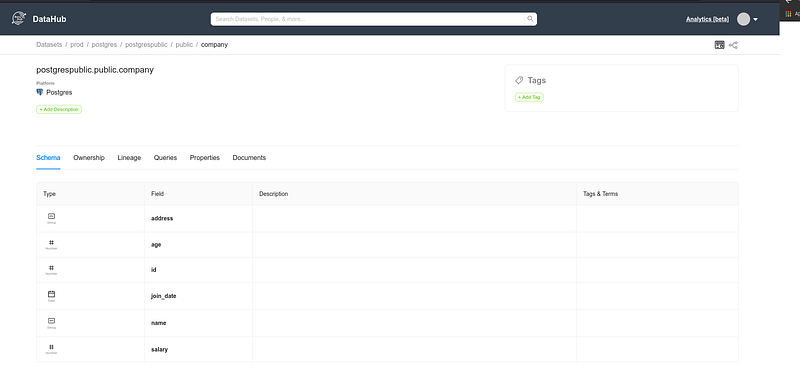
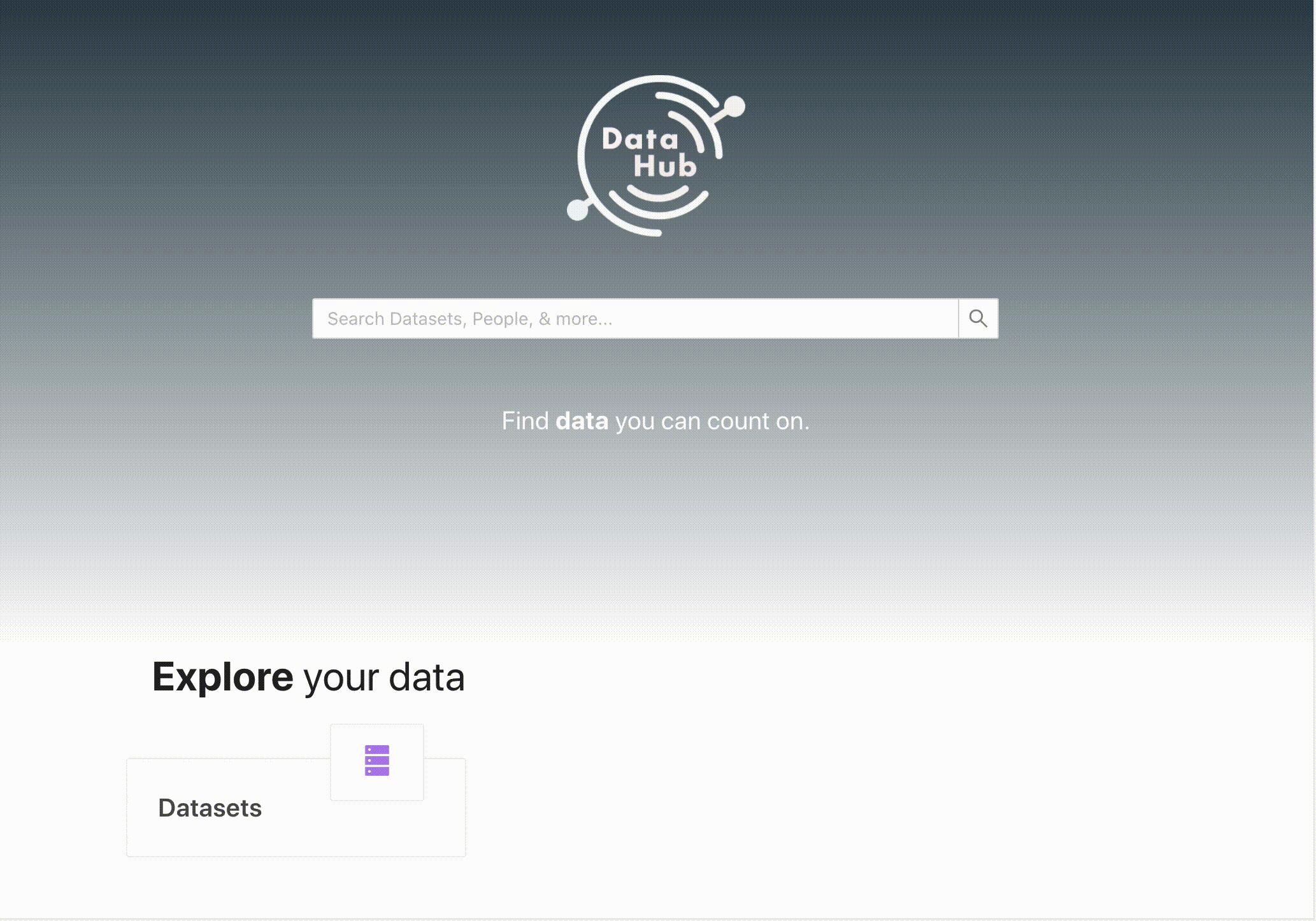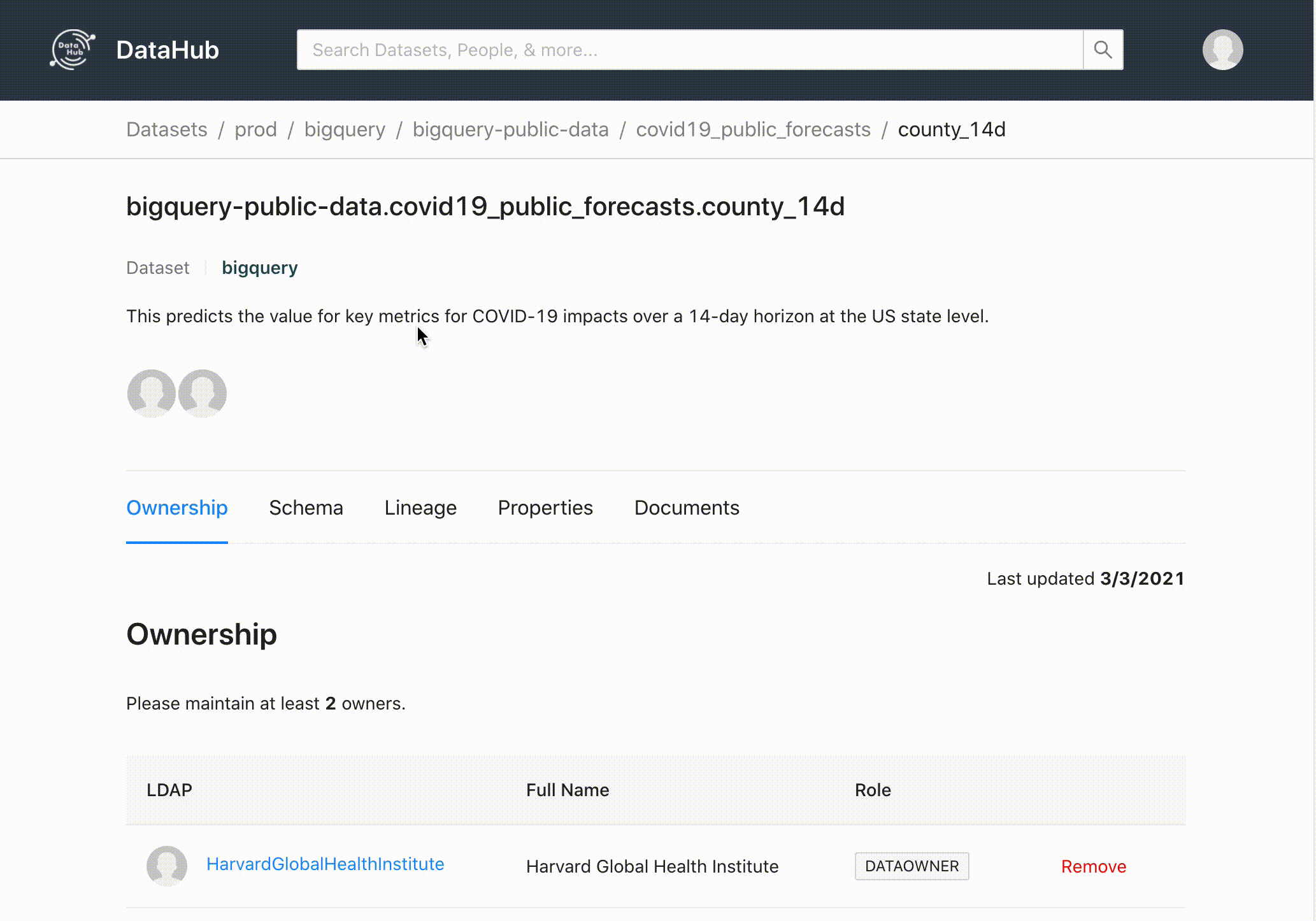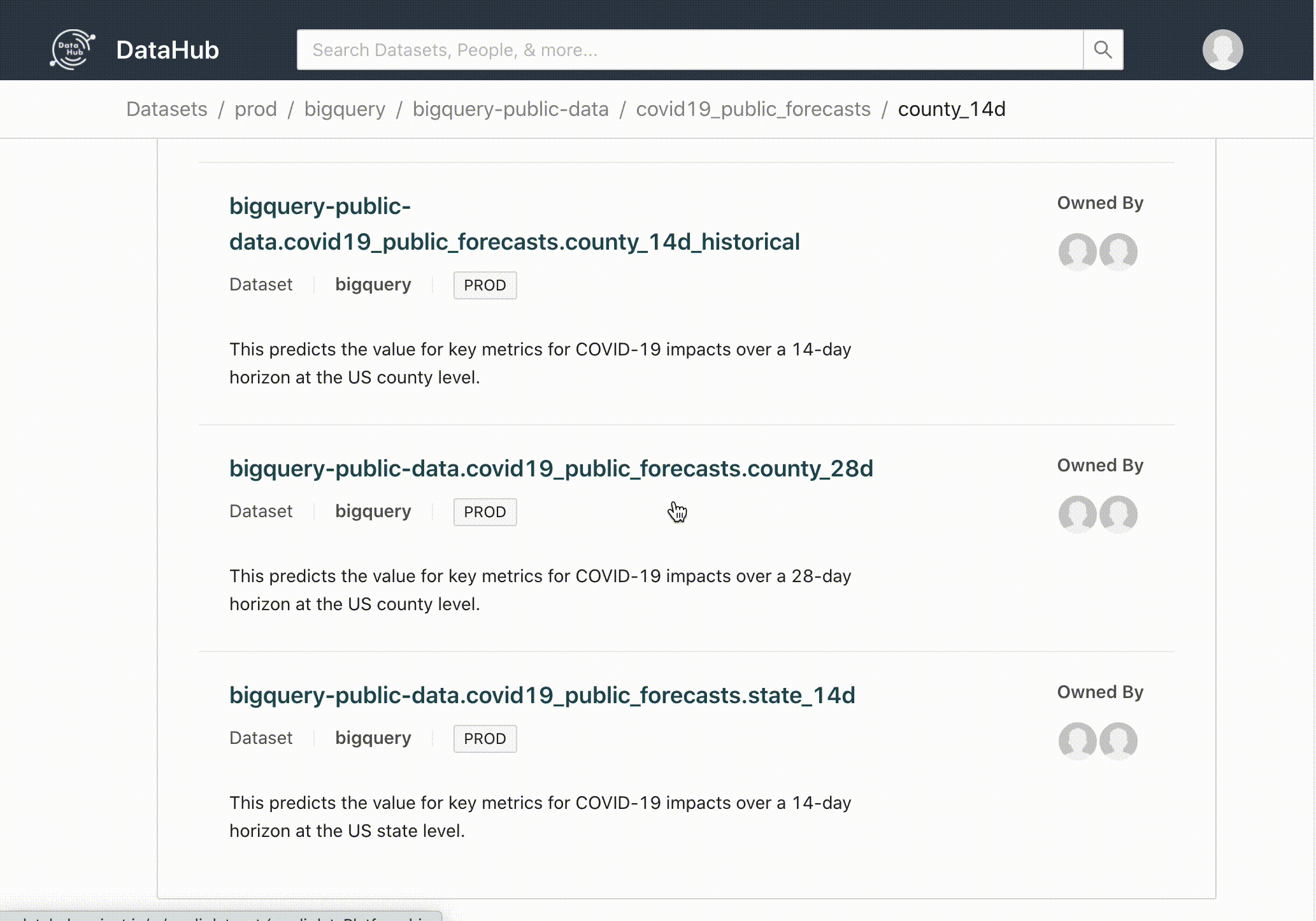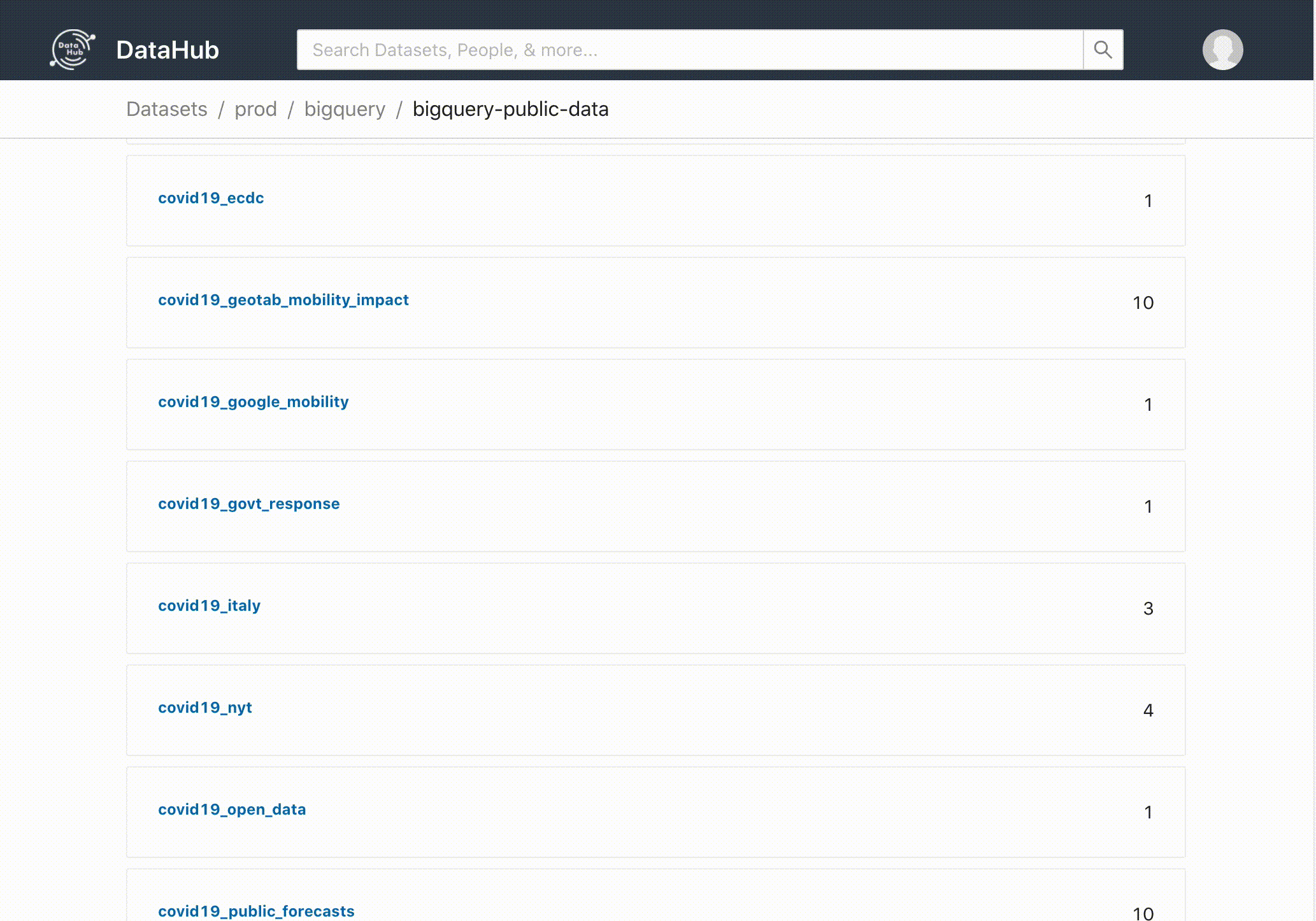
Além dos metadados colhidos é possível colocar uma descrição e tags para o schemas, tabelas e suas colunas; descobrir seu dono “Ownership”, linhagem, principais queries, propriedades e adicionar links de documentações adicionais.
Conclusão:
Estruturar o universo de dados inicialmente caóticos pode ser uma tarefa muito complexa e um primeiro passo será conduzir uma imersão e catalogação dos dados de modo a possibilitar uma reestruturação para um cenário onde haja uma melhor governança e qualidade das informações.
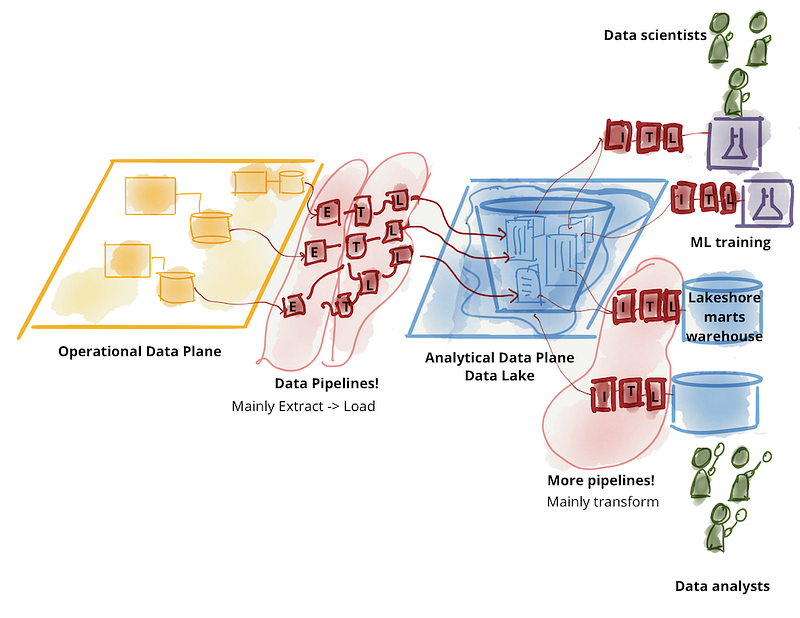
Uma visão de uma arquitetura de dados ideal:
O DataHub é uma poderosa solução para catálogo de dados que além de se integrar a diferentes bancos de dados, possibilita uma linhagem de dados e até mesmo uma catalogação de modelos de inteligência artificial. Contudo, essa solução não é mágica, é necessário acompanhamento e ingestão de dados como descrição dos campos, bem como a gerenciamento de acesso.
“Sem dados, você é apenas mais uma pessoa com opinião.”, W. Edwards Deming
Referências:
#Obrigado por sua leitura, compartilhe essa publicação, por favor! :)