
Cambridge Analytica: the Geotargeting and Emotional Data Mining Scripts
Last year, Michael Phillips, a data science intern at Cambridge Analytica, posted the following scripts to a set of “work samples” on his personal GitHub account.
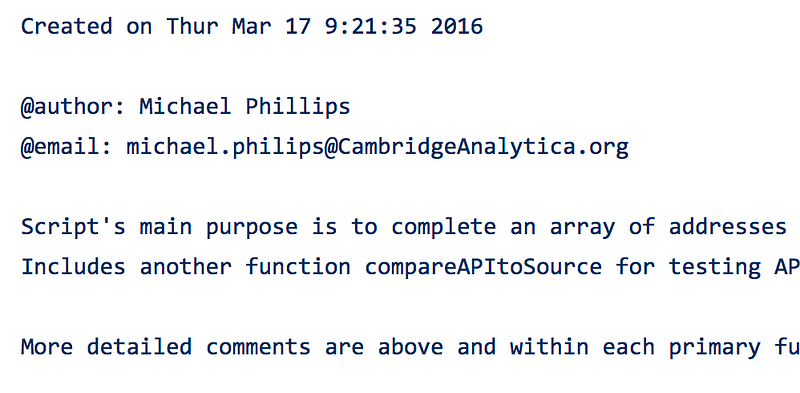
The Github profile, MichaelPhillipsData is still around. It contains a selection of Phillips’ coding projects. Two of the “commits” — still online today — appear to be scripts that were used by Cambridge Analytica around the election. One of them even lists his email address. The rest of his current work, Phillips notes on his Github profile, he unfortunately “cannot share.”
GitHub - MichaelPhillipsData/GitSampleCode: Sample Work
archived 11 Aug 2017 20:37:44 UTC
archive.is
The first of Phillips’ two election data processing Github scripts is titled GeoLocation.py,* a list-completing and enrichment tool that can be used to:
“complete an array of addresses with accurate latitudes and longitudes using the completeAddress functionIncludes another function compareAPItoSource for testing APIs with source latitude longitudes.”
Phillips describes the geolocation list completion script as performing the following tasks (to enrich clients’ personal information files):
“Essentially what it does is: For each address in the addresses file, try to get an accurate lng/lat quickly (comparing available datafrom Aristotle/IG to the zip code file data to determine accuracy), but if we can’t, we fetch it from ArcGIS.”
>Don’t miss the line item called “Voter_ID”

The second “work-related” script sitting on Phillips’ Github repo is called Twitteranalysis.py.
Phillips offers a quick starter for how the Twitter sentiment-mining code works:
For starters, we will just get sentiment from textBlob for tweets containing keywords like “Trump”, “Carson”, “Cruz”, “Bern”, Bernie”, “guns”, “immigration”, “immigrants”, etc.
Twitteranalysis.py also finds the Twitter user IDs amongst the tweet sample it collects in order to “retrieve all the user’s recent tweets and favorites.”
Looking in more detail, it then:
- Separates users’ tweets into [control] groups containing each keyword
- Produces a “sentiment graph” of the whole group using textBlob and matplotlib
As a real-time social media mining tool which uses common tools like tweepy and matplotlib, this doesn’t appear to be science fiction or extremely complex. However, this is not what makes the code interesting as a key research, political evidence, and cultural object.
The most fascinating part of the Twitter sentiment-miner that Phillips’ posted is how it appears to pull users’ IDs and find their “recent tweets” and favorites to expand the company’s corpus of keywords around specific objects of election “outrage” sentiment (ie, immigration, border control, etc.).
Looking below, nearly all “sentiments” within the lines of code involve “hot-button” 2016 election topics such as abortion, citizenship, naturalization, guns, the NRA, liberals, Obama, and Planned Parenthood.
See for yourself, here’s the actual code:
#each sentiments list will have tuples: (sentiment, tweetID)
#note: could include many more keywords like “feelthebern” for example, but need neutral keywords to get true sentiments. feelthebern would be a biased term.
In any case, here are the “sentiments” the script was set to look for via Twitter’s API:
hillarySentiments = [] hillaryKeywords = [‘hillary’, ‘clinton’, ‘hillaryclinton’]
trumpSentiments = [] trumpKeywords = [‘trump’, ‘realdonaldtrump’]
cruzSentiments = [] cruzKeywords = [‘cruz’, ‘tedcruz’]
bernieSentiments =[] bernieKeywords = [‘bern’, ‘bernie’, ‘sanders’, ‘sensanders’]
obamaSentiments = [] obamaKeywords = [‘obama’, ‘barack’, ‘barackobama’]
republicanSentiments = [] republicanKeywords = [‘republican’, ‘conservative’]
democratSentiments = [] democratKeywords = [‘democrat’, ‘dems’, ‘liberal’]
gunsSentiments = [] gunsKeywords = [‘guns’, ‘gun’, ‘nra’, ‘pistol’, ‘firearm’, ‘shooting’]
immigrationSentiments = [] immigrationKeywords = [‘immigration’, ‘immigrants’, ‘citizenship’, ‘naturalization’, ‘visas’]
employmentSentiments = [] emplyomentKeywords = [‘jobs’, ‘employment’, ‘unemployment’, ‘job’]
inflationSentiments = [] inflationKeywords = [‘inflate’, ‘inflation’, ‘price hike’, ‘price increase’, ‘prices rais’]
minimumwageupSentiments = [] minimumwageupKeywords = [‘raise minimum wage’, ‘wage increase’, ‘raise wage’, ‘wage hike’]
abortionSentiments = [] abortionKeywords = [‘abortion’, ‘pro-choice’, ‘planned parenthood’]
governmentspendingSentiments = [] governmentspendingKeywords = [‘gov spending’, ‘government spending’, ‘gov. spending’, ‘expenditure’]
taxesupSentiments = [] taxesupKeywords = [‘raise tax’, ‘tax hike’, ‘taxes up’, ‘tax up’, ‘increase taxes’, ‘taxes increase’, ‘tax increase’]
taxesdownSentiments = [] taxesdownKeywords = [‘lower tax’, ‘tax cut’, ‘tax slash’, ‘taxes down’, ‘tax down’, ‘decrease taxes’, ‘taxes decrease’, ‘tax decrease’]
Drilling down to the list of terms that are linked to each election sentiment keyword (in the code as #(nameOfTuple, sentimentList, keywordList ), we can see:
personSentimentList = [(‘hillary’, hillarySentiments, hillaryKeywords), (‘trump’, trumpSentiments, trumpKeywords), (‘cruz’, cruzSentiments, cruzKeywords), (‘bernie’, bernieSentiments, bernieKeywords), (‘obama’, obamaSentiments, obamaKeywords)]
issueSentimentList = [(‘guns’, gunsSentiments, gunsKeywords), (‘immigration’, immigrationSentiments, immigrationKeywords), (‘employment’, employmentSentiments, emplyomentKeywords), (‘inflation’, inflationSentiments, inflationKeywords), (‘minimum wage up’, minimumwageupSentiments, minimumwageupKeywords), (‘abortion’, abortionSentiments, abortionKeywords), (‘government spending’, governmentspendingSentiments, governmentspendingKeywords), (‘taxes up’, taxesupSentiments, taxesupKeywords), (‘taxes down’, taxesdownSentiments, taxesdownKeywords) ]
Phillips also provides a snippet of code “for taking random twitter IDs” to create a Twitter “control group.” This part of the code appears to “skim the most recent tweets that have mentioned one of our [Cambridge Analytica’s pre-defined] keywords.”

Phillips explains in the notes within his code about the practicalities of sentiment mining — this is not big data (ie, “all the tweets”) that were being sought out:
“it turned out that skimming all of the tweets found very very few occurances of keywords since “twitter is such a global/multilingual platform.”
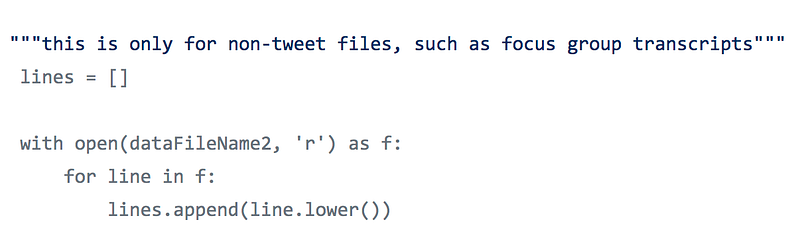
Next, Phillips provides a snippet to parse *any* text that CA was “looking for through non-tweets (like transcripts of some sort),” noting that the tool is set up to “find sentiment and adds [it] to the respective keywords’ data list”:

Interesting functionality, indeed. The lines of code then follow with a function that Phillips states:
“goes through tweets of each user, looks for keywords, and if the keyword is there, we find the sentiment for that tweet and add it to the sentiment data list”

Finally, the code compiles the collected and refined Twitter data into a set. Phillips describes:
“compiles the sentiment data for each keyword group into an easier to work with format (dataframe) … it is only meaningful if compared with a control group, since keyword selection is impossible to employ neutrally.”

The final output of the Twitteranalysis.py is a list of tweets and Twitter users (via user IDs) from a pre-defined set of keywords (abortion, NRA, Hillary, Obama, lower taxes, guns, immigration, liberals, etc.). All relate to #Election2016 campaign issues. Also, this code appears to be extensible — it can be used outside of Twitter, such as to mine the transcripts and recorded text from focus groups and survey respondents.
These scripts normally wouldn’t be that interesting. But provided both were added by a Cambridge Analytica intern (at least at the time) and contain a running dialog of what the tools do, how they work, and why they were built— and the fact that they are *still* available on Github — I thought I’d share.
Almost every pronoun used in the script walkthroughs (see the archived Github links) is inclusive and plural — “our,” “we,” “we’re,” etc. Also, reference to convert to format “to put into the neural network.”

Wait, there’s one more thing. When Phillips committed his original Twitteranalysis.py script, he accidentally left the working Twitter API keys in the code (via the consumer key and consumer “secret”). This contains the alphanumeric strings which are used for the developer account to access data from Twitter’s API.
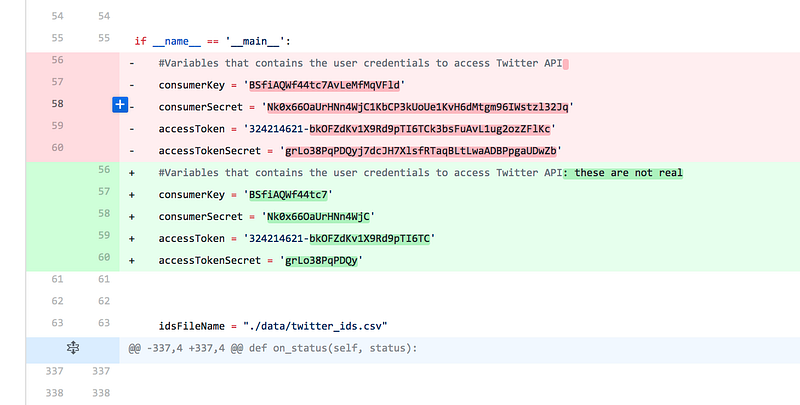
Interestingly, on Feb 23, 2017 (yes, 2017), Phillips removed the API keys:
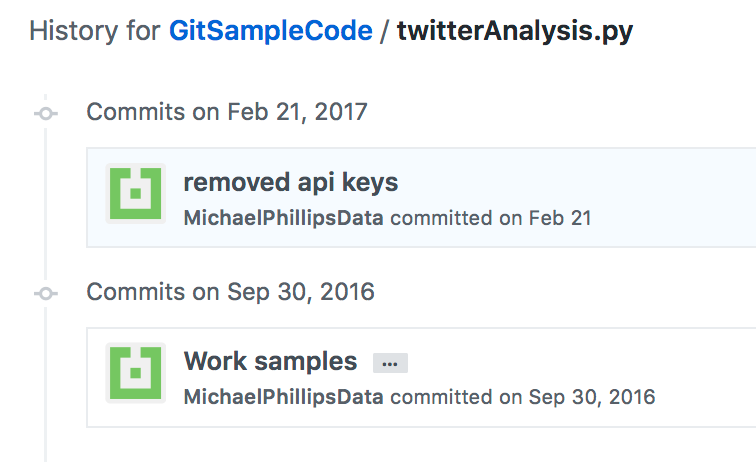
Two days later, another Github user added a comment about Phillip’s mistake:
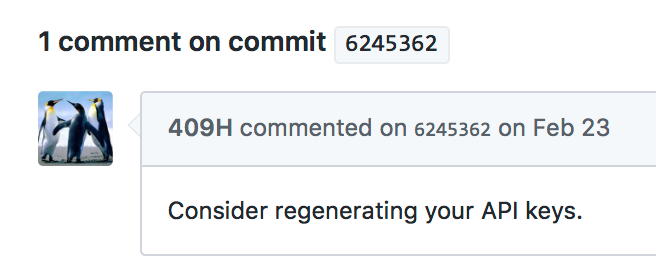
Was this API key Cambridge Analytica’s? Or SCL’s ? While both scripts— the first including Phillips’ @cambridgeanalytica.org email address, clearly are voter data and election related, from the commentary in the script, it’s not clear who the API key belonged to. This might have been Phillips’ own account.
Regardless, this code shows the inner workings of client voter file geo-data “enrichment” and presumably automated voter database processing for clients by Cambridge Analytica.
This code also provides the proof in showing once and for all how Twitter users’ emotional reactions and real-time discussions even favorites/likes (pulled from the API) are mined in real time and used to create test phrases, establish control groups, and apparently provide sets of future terms around keywords related to political campaign issues.
The fact that Cambridge Analytica was using this kind of code to mine emotional responses that surface from users’ “recent tweets” from a defined set of 2016 presidential campaign “trigger words” is interesting.
I’m confident Phillips provided this data in earnest, as he includes an excellent working description in the purposes and uses of these scripts. He was an CA intern who wanted to show his work to get a job in the future. Yet, this is part of the arsenal of tools used by Cambridge Analytica to geolocate American voters and harness American’s real-time emotional sentiment (see example below for Instagram targeting).

I’d argue the question of the ownership of Cambridge Analytica — a foreign business previously registered in the United States as a foreign corporation (SCL Elections ) just became a bit more relevant.
Foreign influence— sound familiar?
And that fact that a working Twitter developer API key — possibly one of Cambridge Analytica’s own — was left sitting on GitHub by a data intern for anyone to use is, well, another story. The code will likely be removed soon, so it’s available here: