
Calculating Vector P-Norms — Linear Algebra for Data Science -IV
Mathematical principles that underpin the regularization methods in Machine Learning
In the Linear Algebra Series, to give you a quick recap, we’ve learned what are vectors, matrices & tensors, how to calculate dot product to solve systems of linear equations, and what are identity and inverse matrices.
Continuing the series, the next very important topic is Vector Norms.
So,
What are Vector Norms?
Vector Norms are any functions that map a vector to a positive value which is the magnitude of the vector or the length of the vector. Now, there are different functions that offer us different ways to calculate vector lengths.
That’s okay but why are we studying this and what does this vector length represent…?
Why learn about Norms??
Norms are a very important concept in machine learning and deep learning that is generally used to calculate the error in the predictions of an ML/DL model.
The length of the vector usually represents the error between the prediction and the actual observation(label).
We often need to calculate the length or magnitude of vectors to be either used directly as a regularization method in ML or as part of broader vector or matrix operations.
So, what sort of functions are these?
Characteristics of Norm functions
Norms are any functions that are characterized by the following properties:
- Norms return non-negative values because it’s the magnitude or length of a vector which can’t be negative.
- Norms are 0 if and only if the vector is a zero vector.
- Norms follow the triangle inequality i.e. the norm of the sum of two(or more) vectors is less than or equal to the sum of the norms the individual vectors. It simply states that geometrically, the shortest path between any two points is a line. Represented by the equation: ∥a+b∥≤∥a∥+∥b∥ where a and b are two vectors and the vertical bars ∥ generally denote the norm.
- The norm of a vector multiplied by a scalar is equal to the absolute value of this scalar multiplied by the norm of the vector. Representing equation: ∥k⋅x∥=|k|⋅∥x∥
Steps to calculate P-norms
The calculation of a P-norm is based on the central formula:
∥x∥ₚ=(∑ᵢ|xᵢ|ᵖ)¹/ᵖ
Here is a quick 4-step process to get the p-norm of a vector
- Get the absolute value of each element of the vector.
- Raise these absolute values to a power p.
- Calculate the sum of all these raised absolute values.
- Get the pₜₕ root or raise the power to 1/p on the result of the previous step.
Now, based on the value of P in the formula, we get different types of Norms. Let’s discuss these one-by-one:
L⁰ Norm
Putting p = 0 in the formula will get us the L⁰ norm.
Anything raised to the power 0 will return 1 except 0. L⁰ is not really a norm because it doesn’t exhibit characteristic #4(described above). Multiplying a constant will give us that number itself.
L¹ Norm
Putting p = 1 gets us L¹ norm. Essentially, the formula would be calculating the sum of the absolute values of the vector.
Formula: |x|₁=(∑ᵢ |xᵢ|)
This is used to calculate the Mean Absolute Error.
Python Code
We can get the L¹ norm using the linear algebra module of the Numpy package which offers a norm() method. By default, the norm function is set to calculate the L2 norm but we can pass the value of p as the argument. So, for L¹ norm, we’ll pass 1 to it:
from numpy import linalg#creating a vector
a = np.array([1,2,3])#calculating L¹ norm
linalg.norm(a, 1)##output: 6.0L² Norm
Putting p = 2 gets us L² norm. The formula would be calculating the square root of the sum of the squares of the values of the vector.
Also known as the Euclidean norm. This is a widely used norm in Machine learning which is used to calculate the root mean squared error.
∥x∥₂ = (∑ᵢ xᵢ²)¹/²
So, for a vector u, L² Norm would become:
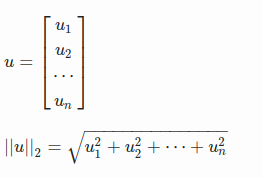
Python Code
Again, using the same norm function, we can calculate the L² Norm:
norm(a) # or you can pass 2 like this: norm(a,2)## output: 3.7416573867739413Squared L² Norm
∑ᵢ|xᵢ|²
The squared L2 norm is simply the L2 norm but without the square root. Squaring the L2 norm calculated above will give us the L2 norm.
It is convenient because it removes the square root and we end up with the simple sum of every squared value of the vector.
The squared Euclidean norm is widely used in machine learning partly because it can be calculated with the vector operation xᵀx.
Python Code
Let’s verify this in python code:
x = np.array([[1], [3], [5], [7]])
euclideanNorm = x.T.dot(x)## output: array([[84]])np.linalg.norm(x)**2
##ouput: 84.0The Max Norm
This is the L∞ norm which simply returns the absolute value of the greatest element of the vector.
Formula becomes:
‖x‖∞=maxᵢ|xᵢ|
Python Code
Let’s verify this in python code, we’ll simply need to pass infinity to the norm function:
x = np.array([[1], [3], [5], [7]])
norm(x, np.inf)##output: 7.0You can play around with all the python codes here:
Graphical Visualisations
Let’s try to analyze the plots graphically. I’ve used the same formula in 2 dimensions(x,y) and the 3rd dimension represents the norm itself.
You can check out this surface plotter which I used to get these plots.
L¹ Norm
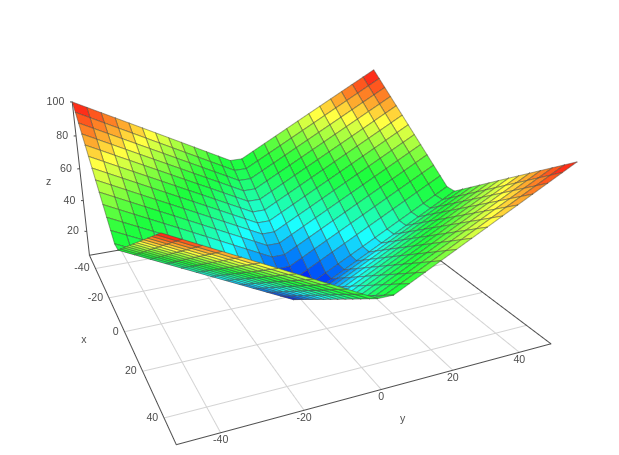
More like planes attached to each other. X and Y are the parameters here.
L² Norm
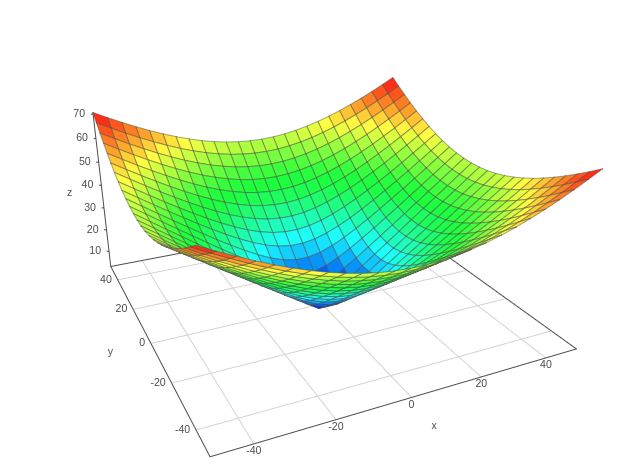
Squared L² Norm
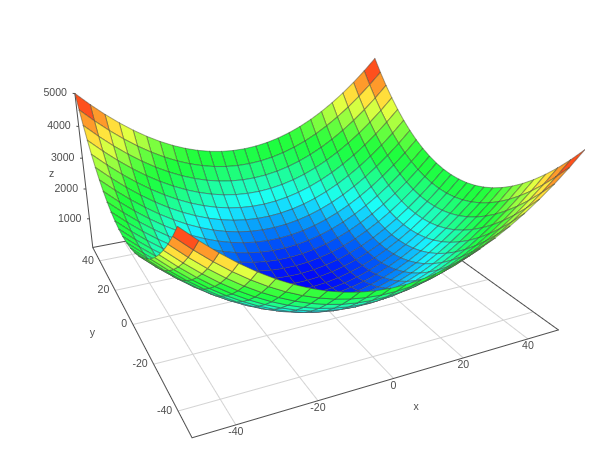
The squared L2 norm and L2 norm look similar but there is an important difference here with respect to the steepness of the plot near the zero mark(in the middle blue region). The square L2 norm doesn’t differentiate well between zero and other smaller values. Thus this uncovers one problem with its use.
Summary
In this tutorial, we looked at different ways to calculate vector lengths or magnitudes, called the vector norms.
Specifically, we learned how to:
- calculate the L1 norm which is calculated as the sum of the absolute values of the vector.
- calculate the L2 norm that is calculated as the square root of the sum of the squared vector values.
- calculate the max norm which is calculated as the maximum vector values.
Data Science with Harshit
With this channel, I am planning to roll out a couple of series covering the entire data science space. Here is why you should be subscribing to the channel:
- These series would cover all the required/demanded quality tutorials on each of the topics and subtopics like Python fundamentals for Data Science.
- Explained Mathematics and derivations of why we do what we do in ML and Deep Learning.
- Podcasts with Data Scientists and Engineers at Google, Microsoft, Amazon, etc, and CEOs of big data-driven companies.
- Projects and instructions to implement the topics learned so far. Learn about new certifications, Bootcamp, and resources to crack those certifications like this TensorFlow Developer Certificate Exam by Google.





