
Is OpenAI’s DALL-E text to image good enough?
It’s capable but leaves a lot to be desired

I am not a machine learning programmer, let alone a data scientist. But as a content creator, my interest in generative AI is twofold:
- #1: If an innovation provides an opportunity to unleash my creativity, I want to be the first to know about it
- #2: If it isn’t good enough for me (conversely, I am not good enough for it), I want to know who is benefitting from it, how much, and why.
Past Microsoft’s acquisition of OpenAI, it released GPT-3. I studied it with my #1 intent above but ended up serving the #2 objective. I also wrote about my conclusion: Why Writers Should Be Afraid of AI
When DALL-E got released, it made top headlines. I do not keep any news notifications ON — all they do is distract me. But DALL-E refused to go unnoticed.
Past its announcement of beta in July 2022, every 2nd day, I came across a Medium article shouting about text-generated art. I could not help but click, only to be redirected to one more AI-based tool that claimed to paint it as good as your imagination.
Today, reading one of those articles, I almost gave up reading about it.
A game artist won an art contest using generative AI:
Following that link trail today, however, I felt I struck a goldmine.
I read about Jason Allen, who won the Colorado State Fair’s digital art competition using AI-generated graphics — not without sparking a fierce online debate about the morality of using AI in an art contest.
Jason won a $300 cash prize and put his creations (titled Théâtre D’opéra Spatial) for sale for $750 each. He used a tool named Midjourney, a Discord-based text-to-image tool. Being a gamer, he also applied Photoshop to perfect his AI-generated masterpiece.
Despite being not much into data science, the whole thing intrigued me to the point to check out the text-based image generation tools.
DALL-E is neither simple nor cheap:
When I googled “text to image”, the first entry that came up was Deepai. As soon as I entered prompts, images matching those prompts began to appear. There was some delay, yes, but the interface was straightforward. There was no login required.
Compared to that, DALL-E’s tool required me to log in first, so that it could count my credit usage.
DALL-E’s pricing is somewhat complex. The first 50 images are free. Past that, it costs $15 for 460 images. Looks quite cheap, right?
Creativity is iterative. No one gets it right in the first place. That’s how DALL-E makes money.
The only catch is that the images run out by a factor of 4 vs 1. In other words, your single text prompt gives you 4 images in response. Those 460 images only give you 115 query prompts to try.
Makers of text-to-image generators want you to think that your creativity is your only limitation. That’s fair. But DALL-E capitalizes on the most crucial fact: Creativity is iterative. No one gets it right in the first place.
On top of your genuinely creative iterations, in the case of DALL-E, you literally spend your first few prompts figuring out how it works the best. The text inference model isn’t intuitive enough to understand the context and intent of your query.
I will prove this in the next section.
DALL-E generated images aren’t what you think they would be:
I entered “laughing crybaby” in two different text-to-image tools. Following were the outputs:

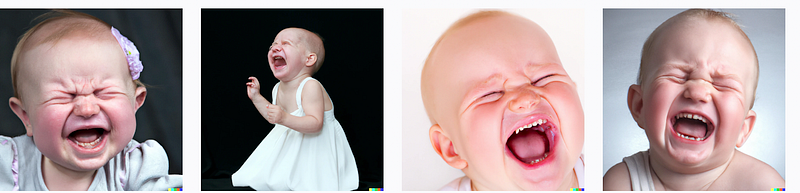
Can you guess which one was generated by DALL-E? I couldn’t trust my eyes when I created them first.
The answer is: It’s the latter. The former was generated by DeepAI.org’s text-to-image tool. Despite its machine-generated poorer quality image, it reveals the purpose of the text more clearly compared to the more realistic DALL-E-generated images.
My next experiment was “Curious kids”. My reasoning was that maybe DALL-E wasn’t good enough with verbs (laughing), so adjectives (Curious) would be better.
DALL-E gave me this:

Compared to that, Unsplash gave me the following as the first entry:

And this:

You pick the winner among those. But clearly, the makers of DALL-E need some open source awakening.
The Cases when DALL-E fared better:
During those experiments, the splash image of DALL-E caught my attention.

I concluded that it wasn’t enough to specify adjectives (fortune-telling). The placement of the object (in a giant hamburger) was also important.
Cool, that gave me a couple of successful attempts with DALL-E:

And…

So DALL-E was good with popular fiction. Well…not for quite long. Following was the result I got from Deepai.org, completely free without spending single credit.
The text term? “Hulk thumping fist in the kitchen sink”.

Our favorite DALL-E brought home the glory:

Not only it missed the subject (Hulk), but it also got the verb (thumping) part wrong in at least 2 images.
Conclusion:
DALL-E’s image generation quality is superior. To exploit it, it also suggests using “Digital Art” in the query to produce superior images.
However, its text interpretation is far inferior even compared to free tools.
The only problem it could solve is to provide copyright-free assets to organizations that cannot afford lawsuits, and also want steep savings in artist hiring budgets.
DALL-E Competition:
OpenAI’s DALLE is not without competition.
Midjourney, the tool that won Jason Allen his virality and fame, is much more simplistic. Daniel Miessler, an IT analyst, compared Midjourney with Mac OS, while comparing DALLE with Linux CLI.
Midjourney trained on high-quality images from Deviant Art which is quite popular in the gaming and graphics community. In contrast, OpenAI’s DALL-E is trained using a much more exhaustive image dataset from across the internet. Because of it, DALL-E perhaps requires more succinct and complex phrases to generate desired images.
Midjourney also gained a smarter edge by basing its query mechanism on Discord — the 24H cafe frequented by the gaming+graphics community.
Apart from Midjourney, there is Stability.ai, which uses the Stable Diffusion model. It is based on the 2b English language label subset of the LAION 5b dataset. Unlike DALL-E and Midjourney, it is open source and has a moderate GPU requirement. It is not cloud-based. Hence, any AI and graphics enthusiast can play with it using the txt2img tool.
An online demo of Stable Diffusion (again, free) hosted on huggingface produced the following image for “Mad scientist”.

OpenAI’s DALL-E produced the following:

Stereotypical — Not something I expected. But not incorrect either. Probably, DALL-E wants me to work harder by specifying terms such as “cartoon”, “art” or “nuclear”.
I am not wasting my credits. While I am not aware of the source from which Stable Diffusion produced it, it was something I would definitely prefer to DALL-E’s.
What does text-generated art mean for designers:
Digging around AI-generated art winning the art contest, I came across a thought-provoking tweet.
The “bigger issue” tweet was akin to something I had written about how GPT-3 AI will affect the writers’ market.
DALL-E and its friends look like a dream come true for wannabe artists who aren’t good at painting. However, the biggest gain lies with huge game studios and illustrated book publishing houses, which employ artists in the proportion of digital assets they produce.
Instead of hiring armies of Photoshop + 3DS designers, they can now hire half a dozen qualified storytellers with an eye for art and mass-produce digital content.
The next elimination will be that of those storytellers, who will get replaced by NLP tools that generate smarter image generating text.
Would hand artists starve then? Not quite.
The AI tools are learning from centuries-old art & literature repositories. They are far from perfect. The Achilles hill for AI-tool is that human languages aren’t declarative like programming languages. They are a much bigger superset of them. They hold context which is too subtle for AI to codify and interpret.
Again, it isn’t completely unachievable. But it is something that needs to be addressed comprehensively, in a long, single attempt. This isn’t the right fit for today’s project management methodologies, which need to look agile and constantly release something, just to uphold the stock markets.
Until AI catches up with its human equivalent, the AI-tool consumer factories will keep hiring mediocre artists and writers to fill the gaps left by imperfect machine learning.
Content creators will be marginalized, but not eliminated. Big publishing houses will employ them en-mass to repair the creations of the machines. By paying them meagrely, they will ensure they don’t suffer from liberation, which will once again open up the vistas of human imagination.
The rest of their savings will be spent after marketing aka convincing the audience that only machine-generated art is real.
That’s when the dark ages will return.
Want to read every Medium story? Become a member using this link. A part of your membership fee will support Pen Magnet’s writings.
Want to get an email every time Pen Magnet publishes? Click here to join his subscriber list.