
But what is a Gaussian process? (An intuition for dummies)
Several machine learning models, as neural networks, are very popular in the data science community, due to its scalability and capacity. However, they exist other models with good properties not as known as neural network that may be a better fit for some problems. In particular, I will present the basic properties of a Gaussian process in this article, trying not to focus my attention on the analytical details but just on the intuition behind this awesome model. Lots of articles give all the mathematical details, and I will leave some cool references at the end of this article if you want to know more about Gaussian processes, so do not worry!
The formal definition and the understandable definition.
If you have a look at the formal definition of a Gaussian process, it is scary: “A Gaussian Process (GP) is a collection of random variables (of potentially infinite size), any finite number of which have (consistent) joint Gaussian distributions.” Some of you may come from a non strictly mathematical background, maybe you have studied engineering or computer science, and this definition may sound, at least, very abstract. However, it is very accurate, but non-intuitive. Let us build a little of intuition here. I prefer the following short and abstract but pragmatic definition:
“A Gaussian process is a model that defines a distribution over functions with respect to observations and the assumptions provided by its kernel function and other hyper-parameters”
Now things change, mainly because you can transfer the definition of a distribution into a distribution over functions. Let us think on a simple univariate normal distribution, where you can sample points from it. You will recover the points located in positions probably according to its shape, that depends on the mean and standard deviation of it.
Moreover, you can also estimate, from a set of observations that we want to fit into an univariate normal distribution, those values using maximum likelihood. Well, the same concepts apply to a Gaussian process! But with the difference that the samples of the Gaussian process are functions, not points.
A picture is worth a thousand of words
And those functions depend on data, as the following figure shows. In the figure, the purple line is the function that we want to perform probabilistic regression on. Recall that this function is unknown to us and we only see it by means of the observations, plotted as red circles. The black line is the prediction that our Gaussian process do about the function and the blue cloud is the uncertainty that the Gaussian process computes about the prediction of the function for all the points where it is defined (basically, in the plots for all the x axis).
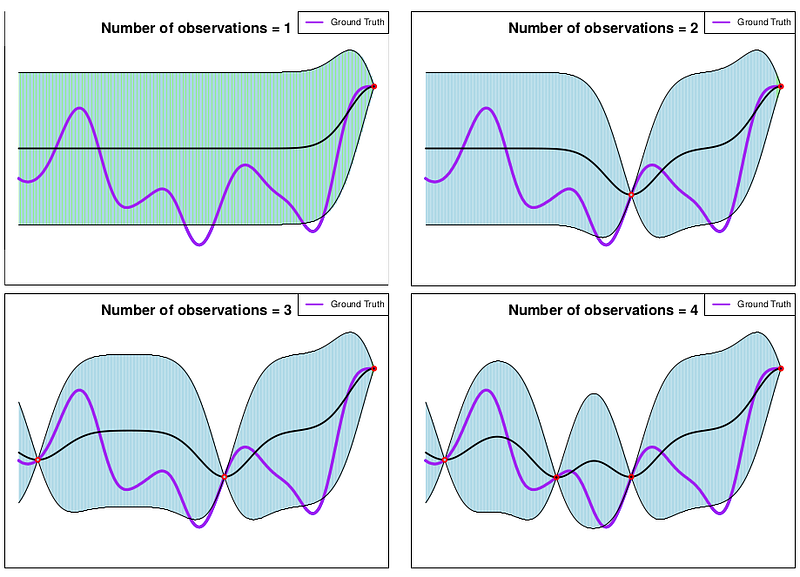
Basically, the blue cloud represents all the possible functions, or the functional space, that according to the Gaussian process assumptions about the data, encoded by the value of their hyper-parameters and the analytical expression of its kernel function, explain the data. You can also interpret the previous figure in the following way: For all the points in the x axis the Gaussian process computes a Gaussian distribution that is defined by the prediction, or “mean” (black line) and the uncertainty about the prediction (blue cloud). Basically, if you plot, for all x, all these distributions you end up having a Gaussian process. Recall that the uncertainty is lower in the neighbourhood of observed locations, as we know the value of the function in that location. Gaussian processes can also be applied to a function of more than one variable! But have the drawback that its vanilla version does not scale.
The assumptions about the function made by a Gaussian process
Not all functions belong to the functional space defined by a Gaussian process. So before applying it to an unknown black-box function it is important to know which assumptions does the Gaussian process make about the objective function. In particular, the functional space of the Gaussian process is completely specified, as in the case of the mean and standard deviation of an univariate normal distribution, by a mean vector and a covariance matrix (whose entries are computed using a kernel function, but that is another story). In particular, the basic things that we need to ensure are the following ones:
- The function is continuous.
- The function is smooth.
- The function is stationary (that is because of stationary kernels, however, extensions of Gaussian process like Deep Gaussian processes or transformations of its kernel functions are able to cover non-stationary functions)
If our objective function has these properties, then we can perform probabilistic regression on it using a Gaussian process. Here are some family of functions that could be targeted by a Gaussian process by changing the value of one of its hyper-parameters.
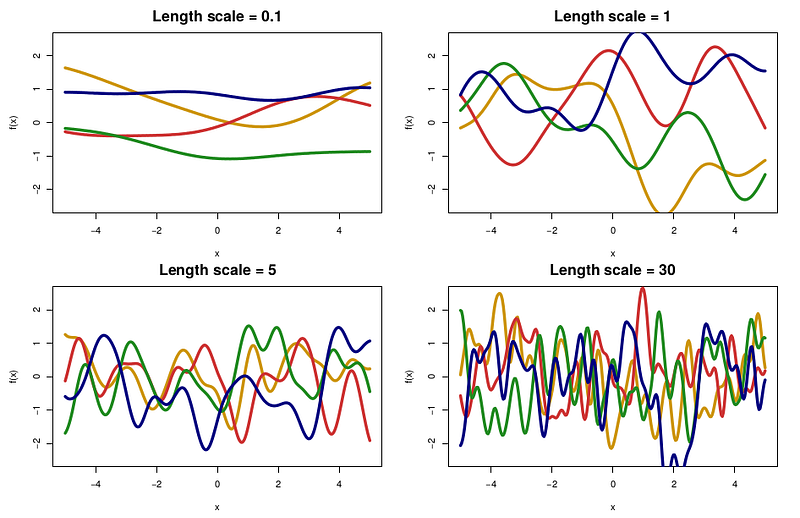
And the nicest thing is that Gaussian processes are available on scikit-learn! Do not hesitate to click on this link, where you will find lots of documentation of how to use them under the scikit-learn interface.
https://scikit-learn.org/stable/modules/gaussian_process.html
Conclusions
Let me be this clear, if your objective function satisfies the assumptions required by a Gaussian process (being stationary, continuous and smooth) then, Gaussian processes are the state-of-the-art in probabilistic regression. They are a great tool. However, in order to be fit, they need to perform the inverse of a matrix, which is very inefficient. But this is not a problem for variations of the model such as Sparse Gaussian processes, that I will analyze in a future Medium post. Did you like this article? Do you want me to explain more models in further medium articles? Do you want more information about the hyper-parameters and kernel functions (or covariance functions) of Gaussian processes? Please leave your opinion in the comments!





