
Bulk with RESTful APIs

How to handle bulk actions when we use RESTful APIs. Deal with different HTTP responses & the considerations of the processes behind. Avoid slowdowns and misconfigurations choosing the right solution. By Manuel Raya & Pedro Escudero.
Bulk RESTful, thanks
Handling bulk requests in a RESTful API is one of the most frequent cases to be considered in this kind of architecture. This fact is especially actual when your system should face a considerable amount of traffic.
Before going ahead with more in-depth analysis, we want to clarify that we consider that we are performing a bulk when the action to be done is of the same type, over the same collection. In other cases, we will speak about a batch action (a different question that we left for a future article is if a batch action is REsTful at all). If you want more extensive documentation regarding this, we invite you to visit this document about bulk operations by John Apostolidis.
Furthermore, as a disclaimer, we are aware of SSE, WS, SFTP load, and other approaches for pushing data but, in this article, we will analyze the RESTful options for this challenge. As we mention in the conclusions, the final solution will depend on a bunch of factors that include, among others, your previous infrastructure, monitoring systems, the knowledge of your staff, the product requirements, the exact amount of traffic, etc.
The issue
Imagine that you want to create (or update, or delete) an item with a regular RESTful request. You would make a POST HTTP call to the proper endpoint, something like POST http://yourdomain/collection, with the needed data. Then you expect a 201 response if everything goes fine, or a 4xx / 5xx reply if something fails. Junior work. Easy, peasy.
Now, imagine that you want to create two items with just one HTTP call. This kind of action makes absolute sense. You are saving time in the transport layer, and the client application avoids making multiple requests.
Well, if all goes fine, your API will respond with a 201. But, what happens when the creations fail? Or when the request has not 2 but 1000 items to be created and it needs over 10 seconds to be processed by the server application? Yeah, that’s the point.
Here you have a handful of ways to deal with this issue:
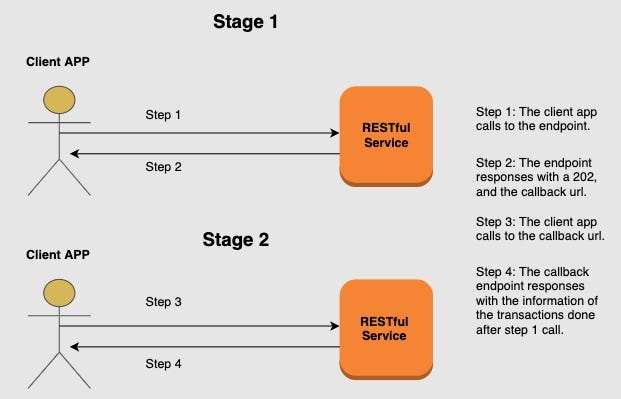
1. Respond with a 202, process the data later
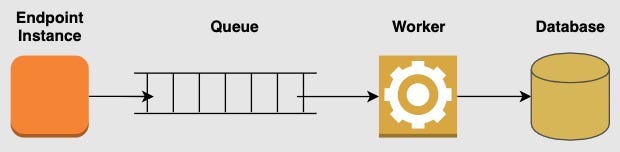
In this case, the endpoint accepts a request with a bunch of elements to be processed and stores them in a queue system. Then a worker will consume and process messages from the queue.
Considerations:
- Beyond the format of the request, it is not a good practice to validate the received data at the endpoint level. Leave that check to the worker.
- You need to create a callback endpoint for each request. There is where the result of the process is shown (the access will be done using a long polling approach and enforcing it with a rate limit if needed).
- You can select the queue system that better fits your needs, knowledge, or current infrastructure (for instance, RabbitMQ is a good choice). We have seen implementations that use for storing a NoSQL database. In those cases, the speed of the procedures should not be relevant. A simple backend task, without a hard timeline.
2. Respond with a 200 (or a 201), process the data at the moment
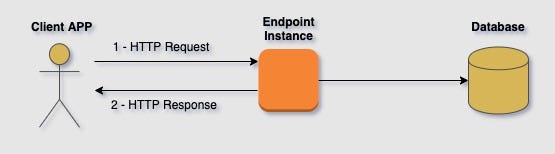
Using this approach, The client sends the full bulk request, the whole bulk is processed, and then the instance that has handled the request sends a response. This solution has some benefits, but also some tradeoffs:
- The data is processing on the fly. A synchronous response is provided, and there are no additional layers that can potentially slow down the workflow.
- The cost of development is not high. It is pretty similar to any other RESTfull endpoint.
- The cost of maintenance is meager. No further infrastructure required.
- If the instance that it is handling the request fails (it has an unexpected shutdown), the client doesn’t know if the data has been processed totally, partially or if it has not been processed at all.
- For a proper treatment of the response, it is needed to add some logic for each one of the elements sent.
3. Respond with a 206
While we have never seen this option finally implemented, we have been in meetings where some developers have proposed it. In more than one country. In different companies. Not only juniors. All this together seems that is floating over there a misunderstanding of when to use a 206 response, or more concretely for what.
The HTTP 206 response is intended for successfully range requests. I guess the confusion is coming from the description of this code in the guides “206 Partial Content “. The range requests are thought for handling petitions allowing to send only a portion of an HTTP message from a server to a client. This is useful mainly for downloading large files like jpg, mp4, pdf, etc. You can find a more in-depth explanation in this Mozilla page about range requests.
4. Respond with a 200, just jump and trust (don’t do this at all !!!)

This is the laziest solution. Also, the weakest one. When the request is received, a 200 HTTP response is sent, without taking care if the actions requested have been successful or not. Such behavior entails crucial issues, like the lack of traceability on the client-side (not to mention how it works against RESTful principles).
Perhaps, you think this alternative is fine for a send and forget approach, sometimes employed in logging. But if you step back, and rethink it, you will realize that if you don’t care about some data, most likely you don’t need it. Anyhow, this stinky option could work, for a while. Until you need to dig in logs in a crisis, and those logs are not there.
Through the years, we have seen several variants of this implementation. None of those deserves the development time:
- Queuing the message and processing it later. Similar to option one but poorly done, without any callback endpoint (also 202 is a more precise answer than a 200 for this).
- Validating each element before the response. If there is an error, send a 400. Still, if after the validation, there is another problem (in the persistence, for example) that is not adequately communicated to the client.
- Asking the clients to call the resource endpoint for checking if the object is there (or when the requested action was a PUT or PATCH checking that it appears with the proper values). If they don’t have the expected answer, then the operation has failed. This choice is utterly inefficient. An endpoint is going to be called in quite a weird way. Logging and debugging will become a nightmare. Mere checking requests will overload an endpoint that should serve content. Furthermore, while you are going away from the standard, the integrations with your system will be painful and bug-prone.
Then, what should we do?

There is not a white or black scenario, but neither grey. You need to understand your underline architecture and analyze your client and business requirements. In any case, unless you are exploring for yourself or doing a quick proof of concept, we strongly recommend that you should avoid options 3 and 4.
Regarding options 1 and 2, option 1 seems more robust. Responding a 202 and processing the data later, you ensure that you are protecting if there is an unexpected issue, and you enforce the data integrity. However, processing the data at the moment is still a valid solution depending on the requirements of your applications and the tradeoff that you can assume.
Keep in mind that your decision on how to organize the communication at the API level will determine the pace of your application. The integration of your own related microservices, partner apps, and web and mobile developments will depend on it.
Remember, the code is poetry, but only if you take care of it.
